Funny thing I've heard about math is that at higher levels you see fewer actual numbers. This results in people who have PHDs in pure math sometimes struggling with simple arithmetic.
5:57 "In math, proving something for every number is almost as impossible as proving your room is dust free in every possible corner simultaneously." What does that even mean. Also, ever heard of proof by induction?
Yes. This is true for most of these "explanations", but it is worst for p=np. His analogy is so bad that I am pretty sure he doesn't understand the problem.
@@alvinlepik5265 he really blasted it with eulers conjecture. i dont think he fully understood the problems he was making a video on. one can say he made it so everyone could understand but that doesnt mean he can put weirdass analogies that really dont make much sense with the actual problem
10. The Collatz Conjecture: An Information-Theoretic Perspective 10.1 Background The Collatz Conjecture states that for any positive integer n, the sequence defined by: n → n/2 if n is even n → 3n + 1 if n is odd always eventually reaches 1, regardless of the starting value of n. 10.2 Information-Theoretic Reformulation Let's reframe the problem in terms of information theory: 10.2.1 Collatz Sequence Information Content: Define the information content of a Collatz sequence starting at n: I_C(n) = log₂(L(n)) where L(n) is the number of steps to reach 1 from n. 10.2.2 Collatz Information Density: Define the Collatz information density: ρ_C(x) = (1/x) Σ_{n≤x} I_C(n) 10.2.3 Collatz Conjecture as Information Statement: Reformulate the Collatz Conjecture as: ∀n > 0, I_C(n) < ∞ 10.3 Information-Theoretic Conjectures 10.3.1 Collatz Information Bound: ∃ C > 0 such that I_C(n) ≤ C log(n) for all n > 0 10.3.2 Information Complexity of Collatz Orbits: The information content of Collatz orbits follows a specific distribution related to the 3n+1 map's chaotic behavior. 10.3.3 Collatz Information Entropy: The entropy of the distribution of Collatz sequence lengths approaches a constant as x → ∞. 10.4 Analytical Approaches 10.4.1 Information-Theoretic Stopping Time Analysis: Study the stopping time σ(n) (steps to reach a value < n) in terms of information content. 10.4.2 Spectral Analysis of Collatz Information: Apply spectral methods to analyze the fluctuations in ρ_C(x). 10.4.3 Information Flows in Collatz Trajectories: Model the "flow" of information through Collatz sequences as a dynamical system. 10.5 Computational Approaches 10.5.1 Quantum Algorithms for Collatz Sequence Analysis: Develop quantum algorithms for efficiently computing and analyzing Collatz sequences. 10.5.2 Machine Learning for Collatz Pattern Recognition: Train neural networks to recognize patterns in Collatz sequences based on their information content. 10.5.3 High-Performance Computing for Information Content Calculation: Implement distributed computing methods to calculate I_C(n) for very large n. 10.6 Potential Proof Strategies 10.6.1 Information Boundedness Approach: Prove that I_C(n) is bounded for all n, implying the Collatz Conjecture. 10.6.2 Information-Theoretic Induction: Develop an induction argument based on the information content of Collatz sequences. 10.6.3 Quantum Information Bound: Establish a quantum information-theoretic upper bound on I_C(n). 10.7 Immediate Next Steps 10.7.1 Rigorous Formalization: Develop a mathematically rigorous formulation of the information-theoretic concepts introduced. 10.7.2 Computational Experiments: Conduct extensive numerical studies on the information properties of Collatz sequences. 10.7.3 Interdisciplinary Collaboration: Engage experts in dynamical systems, information theory, and quantum computing to refine these ideas. 10.8 Detailed Plan for Immediate Action 10.8.1 Mathematical Framework Development: - Rigorously define I_C(n) and ρ_C(x) and prove their basic properties - Establish formal relationships between these information measures and classical results on the Collatz problem - Develop an information-theoretic version of the 2-adic analysis of the Collatz map 10.8.2 Computational Modeling: - Implement efficient algorithms for computing I_C(n) for large n - Create visualizations of the "information landscape" of Collatz sequences - Develop machine learning models to predict properties of Collatz trajectories 10.8.3 Analytical Investigations: - Study the statistical properties of ρ_C(x) as x varies - Investigate connections between I_C(n) and other number-theoretic functions - Analyze the information-theoretic properties of cycles in generalized Collatz-type problems 10.8.4 Quantum Approaches: - Develop quantum algorithms for efficiently simulating Collatz trajectories - Investigate if quantum superposition can be used to analyze multiple Collatz sequences simultaneously - Explore quantum annealing techniques for finding potential counterexamples or long Collatz sequences 10.9 Advanced Theoretical Concepts 10.9.1 Information Topology of Collatz Orbits: - Define a topology on the space of Collatz orbits based on their information content - Study how the structure of this space relates to the difficulty of the Collatz problem 10.9.2 Collatz Flows in Information Space: - Model Collatz trajectories as flows in an abstract information space - Investigate if techniques from dynamical systems and ergodic theory can be applied to these flows 10.9.3 Quantum Collatz States: - Develop a quantum mechanical model of Collatz sequences where trajectories exist in superposition - Explore how measuring these quantum Collatz states relates to the classical problem 10.10 Long-term Vision Our information-theoretic approach to the Collatz Conjecture has the potential to: 1. Provide new insights into the behavior of iterated functions and their information content 2. Offer a fresh perspective on other problems in discrete dynamical systems 3. Bridge concepts from information theory, quantum computing, and number theory 4. Suggest new computational approaches to studying complex discrete dynamical systems By pursuing this multifaceted approach, we maximize our chances of making significant progress on this longstanding problem. Even if we don't immediately prove the conjecture, this approach promises to yield valuable new insights into the nature of iterated functions and their information content. This framework provides a comprehensive roadmap for tackling the Collatz Conjecture from an information-theoretic perspective. The next steps would involve detailed development of these ideas, rigorous mathematical formulation, and extensive computational experimentation.
10.11 Expanded Next Steps and Advanced Concepts 1. Rigorous Mathematical Framework: a) Generalized Collatz Information Measure: - Define I_C,k(n) for generalized Collatz-type functions of the form ax+b where a and b depend on x mod k - Prove that I_C,2(n) (our original I_C(n)) has special properties compared to other I_C,k(n) - Investigate the relationships between different I_C,k(n) measures b) Information-Theoretic Collatz Tree: - Define T_C(n) as the Collatz tree rooted at n, where edges represent Collatz map applications - Study I_T(n) = log₂(|T_C(n)|) as a measure of the information content of the inverse Collatz problem - Investigate the relationship between I_C(n) and I_T(n) c) Collatz Information Entropy: - Define H_C(x) = -Σ(p_C(n) log p_C(n)) where p_C(n) is the probability of a sequence of length n - Analyze the asymptotic behavior of H_C(x) as x → ∞ - Investigate connections between H_C(x) and the distribution of Collatz sequence lengths 2. Computational Investigations: a) Large-Scale Collatz Sequence Analysis: - Compute I_C(n) for n up to 2^64 or beyond using distributed computing - Analyze the fine-grained structure of ρ_C(x) looking for patterns or unexpected behaviors - Implement advanced algorithms for detecting cycles in Collatz-type sequences b) Machine Learning for Collatz Prediction: - Train deep neural networks on the computed I_C(n) and ρ_C(x) data - Develop models to predict I_C(n) for large n without explicitly computing the entire sequence - Use reinforcement learning to discover efficient strategies for analyzing Collatz sequences c) Quantum Algorithms for Collatz Simulation: - Implement a quantum circuit that simulates the Collatz map efficiently - Develop a quantum algorithm for computing I_C(n) with potential quadratic speedup - Explore quantum walks on graphs representing Collatz trajectories 3. Analytical Approaches: a) Information-Theoretic Ergodic Theory: - Define an information-preserving map T on the space of Collatz sequences - Study the ergodic properties of T in terms of information content - Investigate if there's an information-theoretic invariant measure for the Collatz map b) Spectral Analysis of Collatz Information: - Compute the Fourier transform of ρ_C(x): ρ̂_C(ξ) = ∫ ρ_C(x)e^(-2πixξ)dx - Analyze the spectral properties of ρ̂_C(ξ) looking for hidden periodicities - Investigate if there's a spectral interpretation of the Collatz Conjecture c) Information-Theoretic Renormalization: - Develop a renormalization group approach to the Collatz problem based on information content - Define a renormalization operator R that coarse-grains Collatz sequences - Study the fixed points of R and their relation to the global behavior of Collatz sequences 4. Quantum Approaches: a) Quantum Collatz Oracle: - Design a quantum oracle O_C that, given n, produces a superposition of all states in the Collatz sequence - |ψ_n⟩ = (1/√L(n)) Σ_{i=0}^{L(n)-1} |C^i(n)⟩ where C^i(n) is the ith iterate of n under the Collatz map - Use quantum phase estimation to extract information about the length and structure of Collatz sequences b) Entanglement in Collatz Networks: - Develop a quantum model where numbers in Collatz sequences are entangled - Study how the entanglement entropy of this system relates to the classical I_C(n) - Investigate if quantum contextuality plays a role in the complexity of Collatz sequences c) Quantum Speedup for Collatz Verification: - Design a quantum algorithm that can verify the Collatz Conjecture up to N in O(√N) time - Explore if Grover's algorithm can be adapted to search for potential counterexamples more efficiently 5. Advanced Theoretical Concepts: a) Collatz Information Geometry: - Define a Riemannian metric on the space of Collatz sequences: g_ij = ∂²I_C/∂x_i∂x_j - Study the curvature and geodesics of this space - Investigate if special Collatz sequences (e.g., those reaching 1 quickly) correspond to geometric features b) Topological Data Analysis of Collatz Sequences: - Apply persistent homology to the point cloud of Collatz sequences in information space - Analyze the persistence diagrams and Betti numbers of this data - Explore if topological features provide new insights into the structure of Collatz sequences c) Information-Theoretic Dynamical Systems: - Develop a general theory of information content for discrete dynamical systems - Study how I_C(n) relates to other measures of complexity like topological entropy - Investigate if there's a universal behavior for information content in iterated function systems 6. Interdisciplinary Connections: a) Statistical Physics of Collatz Sequences: - Model Collatz sequences as a statistical mechanical system - Investigate if there are phase transitions in the behavior of I_C(n) or ρ_C(x) - Apply techniques from spin glass theory to study the energy landscape of Collatz trajectories b) Biological Applications: - Explore if Collatz-like sequences appear in biological systems (e.g., gene regulation networks) - Investigate if the information structure of Collatz sequences has analogies in evolutionary processes - Study if Collatz-inspired algorithms can be used for optimization in bioinformatics 7. Long-term Research Program: a) Unified Information Theory of Iterated Functions: - Extend our approach to other famous iterated function problems (e.g., Kaprekar's routine, Fibonacci sequences) - Develop a general framework for understanding the information content of iterated functions - Investigate if there's a fundamental principle governing the information dynamics of discrete systems b) Cognitive Science of Mathematical Exploration: - Study how the human brain explores and understands iterated function systems like the Collatz problem - Use neuroimaging to investigate cognitive processes involved in conjecturing about such systems - Develop AI systems that can autonomously explore and generate conjectures about iterated functions This expanded plan provides a comprehensive roadmap for advancing our information-theoretic approach to the Collatz Conjecture. It combines rigorous mathematical development with speculative theoretical ideas and practical computational and experimental work. By pursuing these diverse avenues simultaneously, we maximize our chances of gaining deep new insights into the behavior of the Collatz sequence and potentially making significant progress towards proving the conjecture. Even if a full proof remains elusive, this approach promises to yield valuable new perspectives on the nature of iterated functions, discrete dynamical systems, and the fundamental relationship between computation and information.
I dont get it with the Eulers conjecture. So he stated some equation, then people found numbers that breat the equation, doesnt it immediately mean that its false all along? What do you mean 'It can't be proven for all the numbers'?
He misunderstood the conjecture, Euler's conjecture is disproven. The proof (counterexample) is the famous shortest mathematical proof. There is no incentive in checking every power, so there isn't much progress
It's amazing how many things can this video get wrong, the analogies isn't even close. It is so bad. Riemann hypothesis: Euler first started researching on the sum of powers of natural numbers, called zeta function (not Riemann zeta yet). He showed that this function can be transformed into products related to primes. (To be exact z(s) = sum(1/n^s) = product(1/(1-p^-s)) ) So, in some way, zeta function describes the primes (it is not just about primes). This interesting function only works when s>1, but Riemann came by and made a better version of it. The new function works the same when you put in the old numbers, but now you can put in new numbers! Think of a grid, Euler showed zeta function worked on a horizontal line, and calculated some values out. Riemann's zeta function works on the whole grid (well almost) About the zeros, some zeros are simple, s=-2,-4,-6,... can all get zeros in Riemann's zeta function, but there are some weird zeros out there, Riemann think it is all on a same vertical line s=1/2 (critical line) , and number chunking shows it is currently true, they found a lot on the line and no one found a zero outside the line yet. It is not an "impossible to access" section of 'math club', what is this bullshit analogy. It is just a hard function to study, you don't learn enough tools to study it until you are a math graduate student in that sector. I don't know how you can say "even the most powerful computers scratch their heads", computers are only used to crunch numbers here, they don't help in proving the hypothesis. It's like saying "even the most clever blender can't cook", like of course they can't. There has been some advances on this area, like how many of non-trivial zeros there are? At least how many of them is on the critical line? How are the zeros distributed along the line? What happens if the hypothesis is true? There are partial answers to these questions P vs NP: The recipe analogy is the most bullshit analogy ever. The only thing this video got correct is the name. The most important concept is time, not whether you can do it or not. What is P (polynomial time)? Firstly polynomial is a type of function, like 3n^5+4n^2+7n+8 and 2n^7+1. Imagine a series of puzzles (like a rubiks cube), we try to solve it and count how many steps it took us. We want to know the step count with respect to the size of the puzzle (3x3,4x4,5x5,.etc). We can solve it however we want, with only one rule, "if you have the exact same puzzle, you can only do the same move." So, we do our best to plan ahead, plan what would we do when we see the puzzle. We have a score counter, called time complexity. After we have our plan/strategy/algorithm, we solve the puzzle using the plan (no changing the plan now). We solve 3x3, 4x4,... 100x100, ... The score counter plot the worst scores in each category. Example: for 3x3 rubiks cube, there are many starting positions, and you will take different amount of steps to solve it. Score counter takes the worst case scenario as your score. It then plots the scores for each category (number-of-steps to n), and tries to find a polynomial function that plotted larger than all the scores, if there is one, we solved the puzzle in polynomial time, and we happily put the puzzle in P. This means we can see the hope of solving large puzzles realistically. For NP (non deterministic polynomial time), the rules changes a bit. We can now clone! Along every step of solving, it is now possible to clone ourselves, and each clone can do different moves (clones can choose to clone after next move, and so on). We just need to plan the cloning ahead too, no changing after we start (we can be lazy and use clones to try every possible move, it is allowed). 1 puzzle in 1 category will have a lot of clones solving it, the score counter takes the fastest clone as the score OF THAT PUZZLE. The category score that it plots still takes the worst case scenario. Again, score counter find a polynomial function larger than all the scores, if it is possible, we put the puzzle in NP. Obviously, P is just NP but we choose not to clone, so every puzzle in P is "simpler", as we don't even need to clone to pass the score counter test. P is a part of NP. The P vs NP problem is, for every puzzle in NP, can we make a plan/algorithm to solve it without cloning and pass the score counter test? If we can, then P=NP. It is obviously very hard, seems impossible. We don't know what is best way to solve a puzzle, how can we do it without cloning and trying different paths? However, there are problems that are moved from NP into P in the past, this is why we suspect it might be possible. Lastly, what is the polynomial checking time in the video? Checking can be seen as a puzzle as well. Given a 'puzzle' and a 'solution', how long do you need to check if 'solution' is correct? If the 'puzzle' is in NP, it is proven that the checking puzzle is in P. And if a checking puzzle is in P, the 'puzzle' is in NP. So the two ideas are interchangable. It is like following every step of the 'solution' and checking the result. As NP puzzles use polynomial time too, and checking don't clone, checking puzzle is in P.
Goldbach Conjecture: The number of "infinite" misuses is baffling. For every number, there are large but FINITE number of combinations, but there are infinite even numbers. How the fuck can you get this wrong? The problem here is no matter how many even number you test using a computer, there will always be a larger number waiting to be tested, so again, computer is a number cruncher, it provides no help. Current best result, Chen's theorem: Every sufficiently big even number can be written as Even = Prime + Prime*Prime (prime*prime is also called semiprime) Collatz Conjecture: Finally one that is not full of false information Hodge Conjecture: I have no idea what this is, can't even understand the formal problem on wikipedia, skip Miller Rabin: Nothing wrong there, but I wouldn't call this a problem, this is an algorithm. The problem here is polynomial time primality test, how fast can you tell whether a number is a prime? This problem is proven to be in P, remember the time complexity? Although fast, Miller-Rabin is probabilistic, there is a deterministic algorithm called AKS primality test that push the problem into P. Yang-Mills: I don't know enough quantum physics to agree/disagree on the weird dance analogy, skip Euler's conjecture: Again, this video really shits at number theory. Almost everything here is wrong This is an generalization of Fermat's Last Theorem, can power of numbers sum to power of a number? The main point is Euler guessed that there is no combination that can do it using less numbers than power, formally: For any n
Every mathematician ever: "Yo bro I got a wild idea that doesn't impact anything about what we know, and also can't be proven, let's talk about it for the next 200 years."
You are also alive. You do no impact on us humans. You do whatever you want to do. So what the problem with us mathameticians trying to solve a problem??
@@chrischappa962 exactly. These problems are just interesting that make us draw our attention to it. They are not useless. To find out if it helps us we have to keep going.
In very very simple and not accurate terms. it asks the following question: Do all problems that have solutions take(approx) as much time to confirm the solution is true as it takes for a solution to be found. Let's say you have a Rubik's cube - given a solution you can check if it is indeed true by performing the actions the solution provides quite easily, but it's very hard to solve the actual cube using an algorithm. It takes much longer than confirming a given solution. if P = NP then we can find a solution that only takes a constant multiplier amount of time more than confirming a solution.
"When you're cleaning your room, there's always that one dusty corner that defies all cleaning efforts. Mocking your determination with it's perpetual dustiness." Yep thats going in my quotes list
Yk its crazy that even if we find a patern for the prime numbers,later we will wabt to find it for different bases too which creates other problems if said paterns are different
Funny. I have taken courses in complexity theory, I have taught courses in complexity theory, and yet I did not understand anything this guy says about the P vs. NP problem...
So basically these aren't unsolved equations, just arbitrary and pointless rulesets that you can't be sure apply to all numbers or numbers of a specific type (i.e. prime).
I think every 5th even number can be expressed with this formula By 5th even number I mean:10,20,30....etc. Prime no are odd no. So they can be written as 2n+1,2n`+1 Let th no be X So n=1+X/5 n`=10-2^N/5 2n-1,2n`-1 gives us two prime for every 5th prime no or multiple of 10.
@@athensdazzle9632 Because of how bad this is. The picking of the last few problems reeks of AI generated content, it just ran out and pick any popular conjecture into the list. Any human that use at least google to search for unsolved problems would not pick Euler's conjecture. Funnily enough, it might not be fully AI generated because of how bad the analogies are.
I feel like most of these are just extremely high level logic questions, like if Johnny has 5 million apples and his shoes are tied what colour is his hair?
Even for children, it literally would have been better off if he just said "can an expert chef/taster always tell what a dish is made of just from tasting it". The one he gave made zero sense 😂
I now here proclaim Casella's conjecture: let n natural such that 2n + 1 be a positive prime. This n is called a plus Casella number. If n is such that 2n -1 is prime, n is a minus Casella number. If n is both a plus and minus Casella number, it is called a super Casella number. I conjecture that there are infinite superCasella numbers. (Seriously now: this is just the twin prime conjecture, I just called it that way in order for myself to joke a little :) ).
7:17 solving a Rubik’s Cube blindfolded has been an event in cubing competitions, try searching up how to solve a Rubik’s cube blindfolded, we never visualise at all
Feel like Fermat's last theorem should have gotten an honerable mention for having been around for hundreds of years abut only being prooved in the 90s.
DISCLAMER: Entertainment purposes only Me [The person]: Let's hope no Asian parents watch thi- Asian parents: IF MY SON CAN'T SOLVE ALL OF THESE PROBLEMS THEN HE GETS DA BELT Napolean: There is nothi- There: HEY, IM SOMETHING Something: No, I'm something No: Ok Ok: What no? Me [The person]: PLEASE TELL ME THIS ISNT REAL Please: This isn't real This: Hey, I'm real Hey: Nobody asked Nobody: What did I ask? What: Nope. You didn't Nope: WHAT DID I DO? I: me do what? me [the word]: Is what even a job? Asian parents: IF NONE OF YOU SOLVE ALL OF THE PORBLEMS THEN YOU ARE GETTING DA BELT Everyone [The people]: *RUSHES TO SOLVE IT ALL* Me [The word]: /go to mars *went to mars* phew, I'm safe Asian parents: *Teleports to mars* WHY YOU NOT DO THE PROBLEM!? Me [The word]: Oh no. Asian parents: YOU GET DA BELT NOW Me [The word]: -Survives- *Goes to heaven* This took a lot of time so if you want more on this comment then feel free to comment Edit: -This is edit 100%- No edits yet
As an extra note, the probabilistic version of the Miller Rabin Prime Test works most of the time. This is known. The unsolved part is if the original version of the algorithm (which does not depend on randomness) works. Tho our current knowledge, it cannot be proven without the Riemann Hypothesis.
If you want to solve a lot of these, I feel like we would need someone to find the pattern within numbers themselves. After 10, numbers repeat back at 0. 11 is prime number, but you can’t just add a a 0 an expect another prime. 110 is not prime. However if you could find a pattern that with any number will always produce a prime, like if the numbers first didget is even, go up 1 number and add that to the beginning, and it will always produce a prime. Then that would unlock a lot of these puzzles. Finding the formulas to these questions ig. But that would take understanding numbers to a whole other level
Numbers don't have to go back at 10. We just chose a base ten counting system even though there is no real reason not to use base 2 or any other number
@@HumongusChungusSo, I guess that in addition to what the guy said, we'd have to look into other bases to find one where such formulae exist and are reasonable. This alone created a sub-problem in our problem.
for collatz conjecture, all even numbers just get divided by 2; the smallest even number is 2 and 2/2 is one. When u divide an even by 2, u approach the minimal 2. Now for odd, 3n+1 will just make the number even in one step. It is the same as if n+1 as all u do is make an odd number even.
Is this supposed to be a proof? 3n+1 sure is even if n is odd, but that's not a promise of how often you can divide that new even number by two. If you can do it only once, the next next number is odd anf looks like 1.5n+0.5 but is still greater than n. And we don't have a proof that this can't happen forever with the number going off to infinity instead of to 1.
@@morfy2581I think it can, and probably does at some point, go all the way to infinity, but for that to happen, the starting number would have to be very specific. Like, (3n+1)/2 mustn't be even, and (3((3n+1/2))+1)/2 can't be as well, and so on and so forth. But this is soo specific that even if this number exists, it's huge and would be so hard to find that it would take a millenia or more.
for the colatz conjuction it's safe to say that it is true for all even numbers because logically, if it's even it can be devided by two and will give you two option, another even number, which goes on untill you get 1, or an uneven number which then you multiply by three to get another uneven number and then add 1 so it gets even, and the devide it by two, i don't see where is the problem in this conjuction? why do we have to prove it for every single number if we know the same rules will apply for every single number?
For example, there might be a starting number that is always only once divisible by 2 after the 3n+1 step, this number would never be able to fall below itself, meaning it would rise forever off to infnity. There is no proof that such a number can't exist.
I think the "P vs NP" explanation was close to be a good analogy, but not quite. You wouldn't have to finish the burger when veryfying if it's really a burger.
My math teacher at school could probably solve all these, like you should see how difficult his tests are at school, I barely passed my table of 9 multiplication exam
What I learned: ABSOLUTELY NOTHING! EXCEPT THAT MATHEMATICS IS STILL NOT MUCH DIFFERENT THAN CHINESE CHARACTERS TO A NON-NATIVE SPEAKER/READER(?!). FOR EXAMPLE: WTF?! ARE THERE DIFFERENT CHARACTERS FOR "MANDARIN" AND DIFFERENT CHARACTERS FOR "CANTONESE"?! HUH?!?! WTF?! ARE YOU EVEN SAYING?!?!😂😂😂😂😂🎉❤
I've been studying maths at an above-average level for eleven years, and I can't understand any of these. Please leave explaining mathematical problems to mathematicians.
You are wrong with the riemann hypothesis, there are infinitely many zeros that fall outside, these are the "trivial zeros" and they all are of the from -2n
Honest to God. If Euler could not figure it out, nobody can ! he died in 1973, and if he was alive today, and had access to the knowledge and PC's we have today , he might have solved 1/2 of these or more.
No. The sum of an even number of odds is always even. Let's say that we only know the three smallest positive odd numbers, 1, 3 and 5. Now add them up, and wow, it's 9.

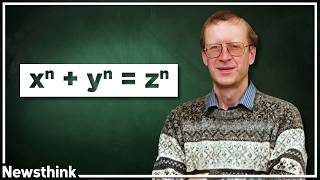








It's always the primes that cause the biggest headaches.
A lot of these problems are also just L-functions.
I'm Team Megatron on this one 😅
Optimus PRIME is HUGE
I can't tell if this was you dissing the drink or not.
The primes, and infinity. And complex numbers. And irrational numbers. And algebra. I hate algebra.
why did nobody try to just use a reaallly good calculator
Good question
Funny thing I've heard about math is that at higher levels you see fewer actual numbers.
This results in people who have PHDs in pure math sometimes struggling with simple arithmetic.
@@martinmnagell2894 nice if that’s true 👍
@@martinmnagell2894 Yeah
Well the answer wouldn't be a number but a new way to solve problems
Some of these are so badly explained, it feels like what chatgpt would tell you when you BADLY asked what the problem itself was.
I also felt that, some problems had literally no math in it :(.
fr
Math doesn't mean numbers it means logic
.
.
5:57 "In math, proving something for every number is almost as impossible as proving your room is dust free in every possible corner simultaneously."
What does that even mean. Also, ever heard of proof by induction?
Even non mathematician, me included, know that a mathamatical proof doesnt have to come in a painstakingly precise calculation.
This explanation of P=NP is so nonsesnsible.
Right
worst explanation ive seen of this
Yes. This is true for most of these "explanations", but it is worst for p=np. His analogy is so bad that I am pretty sure he doesn't understand the problem.
These analogies confused me more than how it could've been when explained directly
those wierd ass analogies were so bad and literally flat out misleading
sufficiently accurate, doesn't have to be exact
@@alvinlepik5265 he really blasted it with eulers conjecture.
i dont think he fully understood the problems he was making a video on. one can say he made it so everyone could understand but that doesnt mean he can put weirdass analogies that really dont make much sense with the actual problem
Its prob ai, didnt go in depth
@@МарияЧановаGood point. The analogies made no sense. Prolly GPTed that shit.
EXACTLY!!! 💯💯
So confusing and irritating. When I thought to understand the problem I got to hear the analogy just to begin to square one.
This video is what happens when a non-mathematician tries to explain math he doesn't understand
It was pretty clear he was in trouble when at 0:54 he describes the "complex plain."
10. The Collatz Conjecture: An Information-Theoretic Perspective
10.1 Background
The Collatz Conjecture states that for any positive integer n, the sequence defined by:
n → n/2 if n is even
n → 3n + 1 if n is odd
always eventually reaches 1, regardless of the starting value of n.
10.2 Information-Theoretic Reformulation
Let's reframe the problem in terms of information theory:
10.2.1 Collatz Sequence Information Content:
Define the information content of a Collatz sequence starting at n:
I_C(n) = log₂(L(n))
where L(n) is the number of steps to reach 1 from n.
10.2.2 Collatz Information Density:
Define the Collatz information density:
ρ_C(x) = (1/x) Σ_{n≤x} I_C(n)
10.2.3 Collatz Conjecture as Information Statement:
Reformulate the Collatz Conjecture as:
∀n > 0, I_C(n) < ∞
10.3 Information-Theoretic Conjectures
10.3.1 Collatz Information Bound:
∃ C > 0 such that I_C(n) ≤ C log(n) for all n > 0
10.3.2 Information Complexity of Collatz Orbits:
The information content of Collatz orbits follows a specific distribution related to the 3n+1 map's chaotic behavior.
10.3.3 Collatz Information Entropy:
The entropy of the distribution of Collatz sequence lengths approaches a constant as x → ∞.
10.4 Analytical Approaches
10.4.1 Information-Theoretic Stopping Time Analysis:
Study the stopping time σ(n) (steps to reach a value < n) in terms of information content.
10.4.2 Spectral Analysis of Collatz Information:
Apply spectral methods to analyze the fluctuations in ρ_C(x).
10.4.3 Information Flows in Collatz Trajectories:
Model the "flow" of information through Collatz sequences as a dynamical system.
10.5 Computational Approaches
10.5.1 Quantum Algorithms for Collatz Sequence Analysis:
Develop quantum algorithms for efficiently computing and analyzing Collatz sequences.
10.5.2 Machine Learning for Collatz Pattern Recognition:
Train neural networks to recognize patterns in Collatz sequences based on their information content.
10.5.3 High-Performance Computing for Information Content Calculation:
Implement distributed computing methods to calculate I_C(n) for very large n.
10.6 Potential Proof Strategies
10.6.1 Information Boundedness Approach:
Prove that I_C(n) is bounded for all n, implying the Collatz Conjecture.
10.6.2 Information-Theoretic Induction:
Develop an induction argument based on the information content of Collatz sequences.
10.6.3 Quantum Information Bound:
Establish a quantum information-theoretic upper bound on I_C(n).
10.7 Immediate Next Steps
10.7.1 Rigorous Formalization:
Develop a mathematically rigorous formulation of the information-theoretic concepts introduced.
10.7.2 Computational Experiments:
Conduct extensive numerical studies on the information properties of Collatz sequences.
10.7.3 Interdisciplinary Collaboration:
Engage experts in dynamical systems, information theory, and quantum computing to refine these ideas.
10.8 Detailed Plan for Immediate Action
10.8.1 Mathematical Framework Development:
- Rigorously define I_C(n) and ρ_C(x) and prove their basic properties
- Establish formal relationships between these information measures and classical results on the Collatz problem
- Develop an information-theoretic version of the 2-adic analysis of the Collatz map
10.8.2 Computational Modeling:
- Implement efficient algorithms for computing I_C(n) for large n
- Create visualizations of the "information landscape" of Collatz sequences
- Develop machine learning models to predict properties of Collatz trajectories
10.8.3 Analytical Investigations:
- Study the statistical properties of ρ_C(x) as x varies
- Investigate connections between I_C(n) and other number-theoretic functions
- Analyze the information-theoretic properties of cycles in generalized Collatz-type problems
10.8.4 Quantum Approaches:
- Develop quantum algorithms for efficiently simulating Collatz trajectories
- Investigate if quantum superposition can be used to analyze multiple Collatz sequences simultaneously
- Explore quantum annealing techniques for finding potential counterexamples or long Collatz sequences
10.9 Advanced Theoretical Concepts
10.9.1 Information Topology of Collatz Orbits:
- Define a topology on the space of Collatz orbits based on their information content
- Study how the structure of this space relates to the difficulty of the Collatz problem
10.9.2 Collatz Flows in Information Space:
- Model Collatz trajectories as flows in an abstract information space
- Investigate if techniques from dynamical systems and ergodic theory can be applied to these flows
10.9.3 Quantum Collatz States:
- Develop a quantum mechanical model of Collatz sequences where trajectories exist in superposition
- Explore how measuring these quantum Collatz states relates to the classical problem
10.10 Long-term Vision
Our information-theoretic approach to the Collatz Conjecture has the potential to:
1. Provide new insights into the behavior of iterated functions and their information content
2. Offer a fresh perspective on other problems in discrete dynamical systems
3. Bridge concepts from information theory, quantum computing, and number theory
4. Suggest new computational approaches to studying complex discrete dynamical systems
By pursuing this multifaceted approach, we maximize our chances of making significant progress on this longstanding problem. Even if we don't immediately prove the conjecture, this approach promises to yield valuable new insights into the nature of iterated functions and their information content.
This framework provides a comprehensive roadmap for tackling the Collatz Conjecture from an information-theoretic perspective. The next steps would involve detailed development of these ideas, rigorous mathematical formulation, and extensive computational experimentation.
10.11 Expanded Next Steps and Advanced Concepts
1. Rigorous Mathematical Framework:
a) Generalized Collatz Information Measure:
- Define I_C,k(n) for generalized Collatz-type functions of the form ax+b where a and b depend on x mod k
- Prove that I_C,2(n) (our original I_C(n)) has special properties compared to other I_C,k(n)
- Investigate the relationships between different I_C,k(n) measures
b) Information-Theoretic Collatz Tree:
- Define T_C(n) as the Collatz tree rooted at n, where edges represent Collatz map applications
- Study I_T(n) = log₂(|T_C(n)|) as a measure of the information content of the inverse Collatz problem
- Investigate the relationship between I_C(n) and I_T(n)
c) Collatz Information Entropy:
- Define H_C(x) = -Σ(p_C(n) log p_C(n)) where p_C(n) is the probability of a sequence of length n
- Analyze the asymptotic behavior of H_C(x) as x → ∞
- Investigate connections between H_C(x) and the distribution of Collatz sequence lengths
2. Computational Investigations:
a) Large-Scale Collatz Sequence Analysis:
- Compute I_C(n) for n up to 2^64 or beyond using distributed computing
- Analyze the fine-grained structure of ρ_C(x) looking for patterns or unexpected behaviors
- Implement advanced algorithms for detecting cycles in Collatz-type sequences
b) Machine Learning for Collatz Prediction:
- Train deep neural networks on the computed I_C(n) and ρ_C(x) data
- Develop models to predict I_C(n) for large n without explicitly computing the entire sequence
- Use reinforcement learning to discover efficient strategies for analyzing Collatz sequences
c) Quantum Algorithms for Collatz Simulation:
- Implement a quantum circuit that simulates the Collatz map efficiently
- Develop a quantum algorithm for computing I_C(n) with potential quadratic speedup
- Explore quantum walks on graphs representing Collatz trajectories
3. Analytical Approaches:
a) Information-Theoretic Ergodic Theory:
- Define an information-preserving map T on the space of Collatz sequences
- Study the ergodic properties of T in terms of information content
- Investigate if there's an information-theoretic invariant measure for the Collatz map
b) Spectral Analysis of Collatz Information:
- Compute the Fourier transform of ρ_C(x): ρ̂_C(ξ) = ∫ ρ_C(x)e^(-2πixξ)dx
- Analyze the spectral properties of ρ̂_C(ξ) looking for hidden periodicities
- Investigate if there's a spectral interpretation of the Collatz Conjecture
c) Information-Theoretic Renormalization:
- Develop a renormalization group approach to the Collatz problem based on information content
- Define a renormalization operator R that coarse-grains Collatz sequences
- Study the fixed points of R and their relation to the global behavior of Collatz sequences
4. Quantum Approaches:
a) Quantum Collatz Oracle:
- Design a quantum oracle O_C that, given n, produces a superposition of all states in the Collatz sequence
- |ψ_n⟩ = (1/√L(n)) Σ_{i=0}^{L(n)-1} |C^i(n)⟩ where C^i(n) is the ith iterate of n under the Collatz map
- Use quantum phase estimation to extract information about the length and structure of Collatz sequences
b) Entanglement in Collatz Networks:
- Develop a quantum model where numbers in Collatz sequences are entangled
- Study how the entanglement entropy of this system relates to the classical I_C(n)
- Investigate if quantum contextuality plays a role in the complexity of Collatz sequences
c) Quantum Speedup for Collatz Verification:
- Design a quantum algorithm that can verify the Collatz Conjecture up to N in O(√N) time
- Explore if Grover's algorithm can be adapted to search for potential counterexamples more efficiently
5. Advanced Theoretical Concepts:
a) Collatz Information Geometry:
- Define a Riemannian metric on the space of Collatz sequences: g_ij = ∂²I_C/∂x_i∂x_j
- Study the curvature and geodesics of this space
- Investigate if special Collatz sequences (e.g., those reaching 1 quickly) correspond to geometric features
b) Topological Data Analysis of Collatz Sequences:
- Apply persistent homology to the point cloud of Collatz sequences in information space
- Analyze the persistence diagrams and Betti numbers of this data
- Explore if topological features provide new insights into the structure of Collatz sequences
c) Information-Theoretic Dynamical Systems:
- Develop a general theory of information content for discrete dynamical systems
- Study how I_C(n) relates to other measures of complexity like topological entropy
- Investigate if there's a universal behavior for information content in iterated function systems
6. Interdisciplinary Connections:
a) Statistical Physics of Collatz Sequences:
- Model Collatz sequences as a statistical mechanical system
- Investigate if there are phase transitions in the behavior of I_C(n) or ρ_C(x)
- Apply techniques from spin glass theory to study the energy landscape of Collatz trajectories
b) Biological Applications:
- Explore if Collatz-like sequences appear in biological systems (e.g., gene regulation networks)
- Investigate if the information structure of Collatz sequences has analogies in evolutionary processes
- Study if Collatz-inspired algorithms can be used for optimization in bioinformatics
7. Long-term Research Program:
a) Unified Information Theory of Iterated Functions:
- Extend our approach to other famous iterated function problems (e.g., Kaprekar's routine, Fibonacci sequences)
- Develop a general framework for understanding the information content of iterated functions
- Investigate if there's a fundamental principle governing the information dynamics of discrete systems
b) Cognitive Science of Mathematical Exploration:
- Study how the human brain explores and understands iterated function systems like the Collatz problem
- Use neuroimaging to investigate cognitive processes involved in conjecturing about such systems
- Develop AI systems that can autonomously explore and generate conjectures about iterated functions
This expanded plan provides a comprehensive roadmap for advancing our information-theoretic approach to the Collatz Conjecture. It combines rigorous mathematical development with speculative theoretical ideas and practical computational and experimental work.
By pursuing these diverse avenues simultaneously, we maximize our chances of gaining deep new insights into the behavior of the Collatz sequence and potentially making significant progress towards proving the conjecture. Even if a full proof remains elusive, this approach promises to yield valuable new perspectives on the nature of iterated functions, discrete dynamical systems, and the fundamental relationship between computation and information.
In my opinion, the reason why it is hard is because it is just hard to find, not hard to solve. It's just finding a number that does x.
Man underrated comment u deserve a LOT OF LIKES
I’d love to read a review article on Collatz conjecture written by you with some technical details
Nonsense word salad
I dont get it with the Eulers conjecture. So he stated some equation, then people found numbers that breat the equation, doesnt it immediately mean that its false all along? What do you mean 'It can't be proven for all the numbers'?
I'm just as confused... and no one else seems to care
@@justicemo9090 looks like he misunderstood something , or something
He misunderstood the conjecture, Euler's conjecture is disproven. The proof (counterexample) is the famous shortest mathematical proof. There is no incentive in checking every power, so there isn't much progress
this video is just poorly invested bro
It's amazing how many things can this video get wrong, the analogies isn't even close. It is so bad.
Riemann hypothesis: Euler first started researching on the sum of powers of natural numbers, called zeta function (not Riemann zeta yet). He showed that this function can be transformed into products related to primes.
(To be exact z(s) = sum(1/n^s) = product(1/(1-p^-s)) )
So, in some way, zeta function describes the primes (it is not just about primes). This interesting function only works when s>1, but Riemann came by and made a better version of it. The new function works the same when you put in the old numbers, but now you can put in new numbers! Think of a grid, Euler showed zeta function worked on a horizontal line, and calculated some values out. Riemann's zeta function works on the whole grid (well almost)
About the zeros, some zeros are simple, s=-2,-4,-6,... can all get zeros in Riemann's zeta function, but there are some weird zeros out there, Riemann think it is all on a same vertical line s=1/2 (critical line) , and number chunking shows it is currently true, they found a lot on the line and no one found a zero outside the line yet.
It is not an "impossible to access" section of 'math club', what is this bullshit analogy. It is just a hard function to study, you don't learn enough tools to study it until you are a math graduate student in that sector. I don't know how you can say "even the most powerful computers scratch their heads", computers are only used to crunch numbers here, they don't help in proving the hypothesis. It's like saying "even the most clever blender can't cook", like of course they can't.
There has been some advances on this area, like how many of non-trivial zeros there are? At least how many of them is on the critical line? How are the zeros distributed along the line? What happens if the hypothesis is true? There are partial answers to these questions
P vs NP: The recipe analogy is the most bullshit analogy ever. The only thing this video got correct is the name. The most important concept is time, not whether you can do it or not.
What is P (polynomial time)? Firstly polynomial is a type of function, like 3n^5+4n^2+7n+8 and 2n^7+1.
Imagine a series of puzzles (like a rubiks cube), we try to solve it and count how many steps it took us. We want to know the step count with respect to the size of the puzzle (3x3,4x4,5x5,.etc). We can solve it however we want, with only one rule, "if you have the exact same puzzle, you can only do the same move." So, we do our best to plan ahead, plan what would we do when we see the puzzle.
We have a score counter, called time complexity. After we have our plan/strategy/algorithm, we solve the puzzle using the plan (no changing the plan now). We solve 3x3, 4x4,... 100x100, ... The score counter plot the worst scores in each category. Example: for 3x3 rubiks cube, there are many starting positions, and you will take different amount of steps to solve it. Score counter takes the worst case scenario as your score.
It then plots the scores for each category (number-of-steps to n), and tries to find a polynomial function that plotted larger than all the scores, if there is one, we solved the puzzle in polynomial time, and we happily put the puzzle in P. This means we can see the hope of solving large puzzles realistically.
For NP (non deterministic polynomial time), the rules changes a bit. We can now clone! Along every step of solving, it is now possible to clone ourselves, and each clone can do different moves (clones can choose to clone after next move, and so on). We just need to plan the cloning ahead too, no changing after we start (we can be lazy and use clones to try every possible move, it is allowed). 1 puzzle in 1 category will have a lot of clones solving it, the score counter takes the fastest clone as the score OF THAT PUZZLE. The category score that it plots still takes the worst case scenario. Again, score counter find a polynomial function larger than all the scores, if it is possible, we put the puzzle in NP.
Obviously, P is just NP but we choose not to clone, so every puzzle in P is "simpler", as we don't even need to clone to pass the score counter test. P is a part of NP.
The P vs NP problem is, for every puzzle in NP, can we make a plan/algorithm to solve it without cloning and pass the score counter test? If we can, then P=NP. It is obviously very hard, seems impossible. We don't know what is best way to solve a puzzle, how can we do it without cloning and trying different paths? However, there are problems that are moved from NP into P in the past, this is why we suspect it might be possible.
Lastly, what is the polynomial checking time in the video? Checking can be seen as a puzzle as well. Given a 'puzzle' and a 'solution', how long do you need to check if 'solution' is correct? If the 'puzzle' is in NP, it is proven that the checking puzzle is in P. And if a checking puzzle is in P, the 'puzzle' is in NP. So the two ideas are interchangable.
It is like following every step of the 'solution' and checking the result. As NP puzzles use polynomial time too, and checking don't clone, checking puzzle is in P.
Goldbach Conjecture: The number of "infinite" misuses is baffling. For every number, there are large but FINITE number of combinations, but there are infinite even numbers. How the fuck can you get this wrong? The problem here is no matter how many even number you test using a computer, there will always be a larger number waiting to be tested, so again, computer is a number cruncher, it provides no help.
Current best result, Chen's theorem: Every sufficiently big even number can be written as Even = Prime + Prime*Prime (prime*prime is also called semiprime)
Collatz Conjecture: Finally one that is not full of false information
Hodge Conjecture: I have no idea what this is, can't even understand the formal problem on wikipedia, skip
Miller Rabin: Nothing wrong there, but I wouldn't call this a problem, this is an algorithm. The problem here is polynomial time primality test, how fast can you tell whether a number is a prime? This problem is proven to be in P, remember the time complexity? Although fast, Miller-Rabin is probabilistic, there is a deterministic algorithm called AKS primality test that push the problem into P.
Yang-Mills: I don't know enough quantum physics to agree/disagree on the weird dance analogy, skip
Euler's conjecture: Again, this video really shits at number theory. Almost everything here is wrong
This is an generalization of Fermat's Last Theorem, can power of numbers sum to power of a number? The main point is Euler guessed that there is no combination that can do it using less numbers than power, formally:
For any n
Many thanks! I already started to think I must be the stupid one not getting these very strange analogies.
🛌🏻
Every mathematician ever: "Yo bro I got a wild idea that doesn't impact anything about what we know, and also can't be proven, let's talk about it for the next 200 years."
You are also alive. You do no impact on us humans. You do whatever you want to do. So what the problem with us mathameticians trying to solve a problem??
As if math exists solely to solve your paltry dilemmas
@@chrischappa962 exactly. These problems are just interesting that make us draw our attention to it. They are not useless. To find out if it helps us we have to keep going.
Shits useless
For example the Riemann hypothisis would impact your life, just like the other (poorly presented) math problems.
Why isn't my math homework on this list?
I ate it sorry
Where can i find the brown material in which traces of bros homework can be found@@457R4L_xX
Not yet buddy
Bc these are problems your professor can’t solve either
I have no idea what the P vs NP problem is, and after that horrible explanation, I still don't know
In very very simple and not accurate terms. it asks the following question: Do all problems that have solutions take(approx) as much time to confirm the solution is true as it takes for a solution to be found.
Let's say you have a Rubik's cube - given a solution you can check if it is indeed true by performing the actions the solution provides quite easily, but it's very hard to solve the actual cube using an algorithm. It takes much longer than confirming a given solution. if P = NP then we can find a solution that only takes a constant multiplier amount of time more than confirming a solution.
@@nivarad8497 a pro in mathematics with a guts pfp what a giga chad you are
@@IMATIREIMASOUP-cu9pv you just made my day sir
my favorite part was the "complex plain".
more like complex pain induced by these weird analogies
I am sorry, but the analogies confuse me rather than make things clearer.
"When you're cleaning your room, there's always that one dusty corner that defies all cleaning efforts. Mocking your determination with it's perpetual dustiness."
Yep thats going in my quotes list
even the "greater than 2" claim at 3:33 is written wrong
Why did you feel the need to say that? Now I can't unsee it.
7:18 "It's as hard as solving a rubik's cube blindfolded", mate people do that in 7 seconds.
For Collatz Conjecture, literally just use the function (3x + 1) /( 2^x ), and it will be 0 forever
Your simplifying these problems made my stupid ass believe i can solve some of them
P vs NP was terribly explained. 😂
Does something makes this Universe special, if someone will find way to correspond integers with Universes that's what about P vs NP, and that's tough
Yk its crazy that even if we find a patern for the prime numbers,later we will wabt to find it for different bases too which creates other problems if said paterns are different
Grand Fermat Theorem : "please stop sending me invitations, I left the club"
Funny. I have taken courses in complexity theory, I have taught courses in complexity theory, and yet I did not understand anything this guy says about the P vs. NP problem...
It's really simple. Making a burger is easy if you have a recipe or if someone started making it for you 😊
It is rather simple:
N=0 and P=1, thank me later.
most of these problems: we can't measure infinity so its unsolvable
No?
Nope. Proving infinite problems is not impossible inherently. Simple example: we can prove there are infinitely many primes
These icons are so unimaginative
You forgot about Legendre's conjecture
I get the attempt to make math accessible to the public but I can't help but think this is oversimplified.
It seems like if you solve the Riemann hypothesis it will let you solve other 3 prime number related problems much easier.
Collatz conjecture was never a problem meant to be solved.
Bro generated a chatgpt script
So basically these aren't unsolved equations, just arbitrary and pointless rulesets that you can't be sure apply to all numbers or numbers of a specific type (i.e. prime).
I think every 5th even number can be expressed with this formula
By 5th even number I mean:10,20,30....etc.
Prime no are odd no.
So they can be written as
2n+1,2n`+1
Let th no be X
So n=1+X/5
n`=10-2^N/5
2n-1,2n`-1 gives us two prime for every 5th prime no or multiple of 10.
what in the ai generated script even is this
Why? you don’t like it?
Why do you think it’s AI generated?
Well i thought this was quite decent
@@user-culkepta beats me why this person thinks it’s AI generated. I’m sure the creator took some help, but the entire thing? Maybe not
@@athensdazzle9632 Because of how bad this is. The picking of the last few problems reeks of AI generated content, it just ran out and pick any popular conjecture into the list. Any human that use at least google to search for unsolved problems would not pick Euler's conjecture.
Funnily enough, it might not be fully AI generated because of how bad the analogies are.
I feel like most of these are just extremely high level logic questions, like if Johnny has 5 million apples and his shoes are tied what colour is his hair?
Is there a unsolved math problem on how much caseoh weighs?
Its like pi, u can calculate it but the number is too big to be rendered
@@grimacetexas9719 pi is not big
@@appreciateit4531 i never said pi was big its too big to be rendered as in, theres not enouth place to write it
Not funny, didn’t laugh
@@teslacactus1135 i dont care plus i didn't ask for your opinion
Never have I made so many confused metaphors. You, sir, are not an analyst.
You dont understand p vs np, you spelled complex plane wrong and you represented "greater than 2" with
Check his channel, he isn't even a math TH-camr
Me when the complex plane is too boring, and it’s not plain enough
Man. I just noticed how all of these have some sort of relevance to the conversation of prime/composite numbers. 😭
PvsNP was explained soo badly and totally wrong but well okay as a video for children
Even for children, it literally would have been better off if he just said "can an expert chef/taster always tell what a dish is made of just from tasting it". The one he gave made zero sense 😂
😂
7:18 i can do that, it takes me 5 mins. Btw the world record is 12 seconds. Yes, a guy solved a rubiks cube blindfolded in 12 seconds
without seeing it first?
@@notatrickstar3469 You have 15 seconds before to see it
I now here proclaim Casella's conjecture: let n natural such that 2n + 1 be a positive prime. This n is called a plus Casella number. If n is such that 2n -1 is prime, n is a minus Casella number. If n is both a plus and minus Casella number, it is called a super Casella number. I conjecture that there are infinite superCasella numbers. (Seriously now: this is just the twin prime conjecture, I just called it that way in order for myself to joke a little :) ).
7:17 solving a Rubik’s Cube blindfolded has been an event in cubing competitions, try searching up how to solve a Rubik’s cube blindfolded, we never visualise at all
huhhh
Rie-MAWN. Rie-MAWN hypothesis. Bernhard Rie-MAWN. HOW DO THESE PEOPLE ALWAYS GET THIS WRONG.
The Navier Stokes Existence and smoothness???????
2:18 bro just cooked here
My favorite unsolved problem is 1+1=
Feel like Fermat's last theorem should have gotten an honerable mention for having been around for hundreds of years abut only being prooved in the 90s.
How is Eulers conjecture unsolvable? You said there are some numbers that don’t work with it; that would prove it doesn’t work.
Well, there are ppl who can solve a rubiks cube blindfolded under 15 seconds, so it means they are better than the best mathematicians in the world?
So basically a lot of these ARE true, but since we aren’t allowed to assume that they are unprovable.
True. We need to find a way to prove a problem or to disprove it.
Because nothing can be neutral. It has to be either the truth or false.
DISCLAMER: Entertainment purposes only
Me [The person]: Let's hope no Asian parents watch thi-
Asian parents: IF MY SON CAN'T SOLVE ALL OF THESE PROBLEMS THEN HE GETS DA BELT
Napolean: There is nothi-
There: HEY, IM SOMETHING
Something: No, I'm something
No: Ok
Ok: What no?
Me [The person]: PLEASE TELL ME THIS ISNT REAL
Please: This isn't real
This: Hey, I'm real
Hey: Nobody asked
Nobody: What did I ask?
What: Nope. You didn't
Nope: WHAT DID I DO?
I: me do what?
me [the word]: Is what even a job?
Asian parents: IF NONE OF YOU SOLVE ALL OF THE PORBLEMS THEN YOU ARE GETTING DA BELT
Everyone [The people]: *RUSHES TO SOLVE IT ALL*
Me [The word]: /go to mars *went to mars* phew, I'm safe
Asian parents: *Teleports to mars* WHY YOU NOT DO THE PROBLEM!?
Me [The word]: Oh no.
Asian parents: YOU GET DA BELT NOW
Me [The word]: -Survives- *Goes to heaven*
This took a lot of time so if you want more on this comment then feel free to comment
Edit: -This is edit 100%- No edits yet
Advanced math concepts are too tough for chatGPT. These analogies are not good.
your analogies are like when my customers try to explain their plumbing issue to me (the plumber). I suspect your not a mathematician
As an extra note, the probabilistic version of the Miller Rabin Prime Test works most of the time. This is known. The unsolved part is if the original version of the algorithm (which does not depend on randomness) works. Tho our current knowledge, it cannot be proven without the Riemann Hypothesis.
If you want to solve a lot of these, I feel like we would need someone to find the pattern within numbers themselves. After 10, numbers repeat back at 0. 11 is prime number, but you can’t just add a a 0 an expect another prime. 110 is not prime. However if you could find a pattern that with any number will always produce a prime, like if the numbers first didget is even, go up 1 number and add that to the beginning, and it will always produce a prime. Then that would unlock a lot of these puzzles. Finding the formulas to these questions ig. But that would take understanding numbers to a whole other level
We already have a pattern that generates all prime numbers, namely willans formula. But such formulas are useless for research
Crank.
Thats quite impossiblle
Numbers don't have to go back at 10. We just chose a base ten counting system even though there is no real reason not to use base 2 or any other number
@@HumongusChungusSo, I guess that in addition to what the guy said, we'd have to look into other bases to find one where such formulae exist and are reasonable. This alone created a sub-problem in our problem.
0:54 plane*
for collatz conjecture, all even numbers just get divided by 2; the smallest even number is 2 and 2/2 is one. When u divide an even by 2, u approach the minimal 2. Now for odd, 3n+1 will just make the number even in one step. It is the same as if n+1 as all u do is make an odd number even.
Yes you approach 2 when halving but sometimes you reach an odd number on the way, like with 24 -> 12 -> 6 -> 3 -> 10 (3*3+1) -> ...
When you start playing with big numbers it gets more complicated than that, someone it doesn't work.
Is this supposed to be a proof?
3n+1 sure is even if n is odd, but that's not a promise of how often you can divide that new even number by two. If you can do it only once, the next next number is odd anf looks like 1.5n+0.5 but is still greater than n.
And we don't have a proof that this can't happen forever with the number going off to infinity instead of to 1.
@@morfy2581I think it can, and probably does at some point, go all the way to infinity, but for that to happen, the starting number would have to be very specific.
Like, (3n+1)/2 mustn't be even, and (3((3n+1/2))+1)/2 can't be as well, and so on and so forth. But this is soo specific that even if this number exists, it's huge and would be so hard to find that it would take a millenia or more.
Euler's conjecture is just flat-out false. It's not unsolved, it's completely solved to everyone except the biggest of idiots.
for the colatz conjuction it's safe to say that it is true for all even numbers because logically, if it's even it can be devided by two and will give you two option, another even number, which goes on untill you get 1, or an uneven number which then you multiply by three to get another uneven number and then add 1 so it gets even, and the devide it by two, i don't see where is the problem in this conjuction? why do we have to prove it for every single number if we know the same rules will apply for every single number?
For example, there might be a starting number that is always only once divisible by 2 after the 3n+1 step, this number would never be able to fall below itself, meaning it would rise forever off to infnity.
There is no proof that such a number can't exist.
your presentation has errors "complex plain" should be "complex plane". Also, your description of P vs NP shows no understanding whatsoever.
I think the "P vs NP" explanation was close to be a good analogy, but not quite. You wouldn't have to finish the burger when veryfying if it's really a burger.
All of those problems sounds to me like P = NP. 🧐
All of these math problems are super easy. The answer to all of them is 42!
True I got that same answer right away lol and I'm saying this as someone who struggles with math
What do you mean the answer is 1,405006117752879899e51 ?
@@luizguilherme8416 yeah bro I did it when i was 5
The scientists are just lackin'
Will quantum computers be useful in solving any of these?
I'm trying to understand the confusion that is the Riemann hypothesis.
Does Euler's conjecture exclude 1 as a valid power? Also, examples, I want examples for every one of these.
My math teacher at school could probably solve all these, like you should see how difficult his tests are at school, I barely passed my table of 9 multiplication exam
Nawww, this is literally like comparing albert einstein to a dolphin (or ur math teacher)
1/10 rage bait make it more believable buddy
What I learned: ABSOLUTELY NOTHING! EXCEPT THAT MATHEMATICS IS STILL NOT MUCH DIFFERENT THAN CHINESE CHARACTERS TO A NON-NATIVE SPEAKER/READER(?!). FOR EXAMPLE: WTF?! ARE THERE DIFFERENT CHARACTERS FOR "MANDARIN" AND DIFFERENT CHARACTERS FOR "CANTONESE"?! HUH?!?! WTF?! ARE YOU EVEN SAYING?!?!😂😂😂😂😂🎉❤
you're in luck bcuz im currently working on the p vs np problem
Good luck bro
Crank.
Youre trying to solve a problem after seeing a video on it?
There aint no party like a number party.
10:30 even worse, the pieces change because you are looking
Decimals exist
Why not use principle of mathematical induction to try and prove collate donjecture
Because it doesnt work here
I mean it could work maybe, but how to prove it?
Never forget there's much easier ways become a millionaire.
Complex Plane, not plain.
I've been studying maths at an above-average level for eleven years, and I can't understand any of these. Please leave explaining mathematical problems to mathematicians.
Tasks from the Mathematic- Olympia be like:
Its always the prime numbers.
You are wrong with the riemann hypothesis, there are infinitely many zeros that fall outside, these are the "trivial zeros" and they all are of the from -2n
I think I found a solution to P vs. NP
Clash of Clan gold mine collecting sound is class
Honest to God.
If Euler could not figure it out, nobody can !
he died in 1973, and if he was alive today, and had access to the knowledge and PC's we have today , he might have solved 1/2 of these or more.
More like 1783
Complex pla-i-n ? Really ?!!
Could you expla-n-e ? 😅
7÷3,5=1
Dude since there are no even primes so that means all primes are odd and sum of all odds are always even .
No. The sum of an even number of odds is always even. Let's say that we only know the three smallest positive odd numbers, 1, 3 and 5. Now add them up, and wow, it's 9.
But i can solve Rubik's cube blindfolded
perfect prime?
Navier-Stokes enters the chat
1:07 says exlusive instead of exclusive. 😢
Now do this video for real math nerds with every detail
Yes! I want it.
this has to be the worst video I’ve ever watched
Imagine quantum computer works perfectly 😊
Eh, why I always have to explain, it’s not that we do not have enough computational power. It’s that you cannot have “infinite” computational power.
I have a proof of all the problems but the comment section is too small.
Complex "plain"? Ugh...why are math people so bad at spelling?
Those are homophones
Oh, i just saw nvm
navier-stokes equations :(
Change the title to:
Some unsolved math problems poorly explained
GREAT VIDEO! Liked and subscribed ❤
why do people do this