At 11:02, instead of "the first rows of the first four channels will be for box coordinates", do you intend to say "the first cells of the first four channels will be for box coordinates"?
Hi ! Thank you for the great tutorial. I understand why we use the detection head and how it works. But I dont get, how we would combine the 3 outputs of the 3 heads. How would we know, which output/head (highleve, lowlevel, midlevel) is responsible for which ground truth box ? So that we can calculate the loss. Or is there a way to combine the output of the 3 heads to a single one ? Thank you
Assuming you are familiar with the notion of anchor boxes. The anchor boxes are assigned to different levels and during training you associate the ground truth box with an anchor box. This is how a particular level becomes responsible for predicting for the ground truth box.
@@KapilSachdeva Thank you for the response and your awesome videos ! I think I get it now. I never found a good explantation for it. Do we consequently use bigger anchor boxes for the higher up levels and smaller ones for the lower level bounding boxes ? And therefore we know which ground truth box to assign to which layer using the IuO score ?

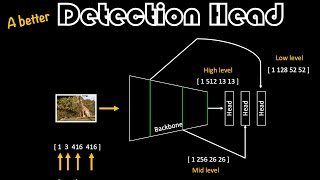








At 11:02, instead of "the first rows of the first four channels will be for box coordinates", do you intend to say "the first cells of the first four channels will be for box coordinates"?
At 5:01 could you please explain why is it [1,5] and not [5,1]? Shouldn't the coordinates be in (x,y) format?
No the coordinates are in [y,x] … nothing specific about it as such, just a convention used in all object detection models.
this channel is amazing!!!!
🙏 not sure if there is anything for you to learn from my channel but sincerely appreciate your kind words.
Very nice lecture sir. Thank you!
Isn't the cell position [1][5] at the 19th cell (not the 15th cell) ?
Yes it will be the 19th cell, do I say it 15th cell in the tutorial?
@@KapilSachdeva Yes, no worries. Please keep on doing your magnificent work.
Awesome 🤩, thank you so much sir.
🙏
clean explanation !
🙏
Hi ! Thank you for the great tutorial. I understand why we use the detection head and how it works. But I dont get, how we would combine the 3 outputs of the 3 heads. How would we know, which output/head (highleve, lowlevel, midlevel) is responsible for which ground truth box ? So that we can calculate the loss. Or is there a way to combine the output of the 3 heads to a single one ? Thank you
Assuming you are familiar with the notion of anchor boxes.
The anchor boxes are assigned to different levels and during training you associate the ground truth box with an anchor box. This is how a particular level becomes responsible for predicting for the ground truth box.
@@KapilSachdeva Thank you for the response and your awesome videos ! I think I get it now. I never found a good explantation for it. Do we consequently use bigger anchor boxes for the higher up levels and smaller ones for the lower level bounding boxes ? And therefore we know which ground truth box to assign to which layer using the IuO score ?
Yes
hi, amzing explanations, bravo
how can i contact you sir ?
🙏 if you have questions you can always ask them in comments.
Thank you❤
🙏
nice...
🙏