
- 41
- 434 883
Kapil Sachdeva
United States
เข้าร่วมเมื่อ 26 ก.ย. 2013
"Work like Hell. Share all you know. Abide by your handshake. Have fun!" - Dan Geer
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
Eliminate Grid Sensitivity | Bag of Freebies (Yolov4) | Essentials of Object Detection
This tutorial explains a training technique that helps in dealing with objects whose center lies on the boundaries of the grid cell in the feature map.
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
th-cam.com/video/-nLJyxhl8bY/w-d-xo.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
th-cam.com/video/-nLJyxhl8bY/w-d-xo.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
มุมมอง: 1 238
วีดีโอ


GIoU vs DIoU vs CIoU | Losses | Essentials of Object Detection
มุมมอง 5Kปีที่แล้ว
This tutorial provides an in-depth and visual explanation of the three Bounding Box loss functions. Other than the loss functions you would be able to learn about computing per sample gradients using the new Pytorch API. Resources: Colab notebook colab.research.google.com/drive/1GAXn6tbd7rKZ1iuUK1pIom_R9rTH1eVU?usp=sharing Repo with results of training using different loss functions github.com/...
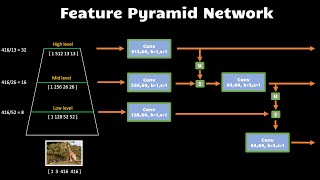
Feature Pyramid Network | Neck | Essentials of Object Detection
มุมมอง 14Kปีที่แล้ว
This tutorial explains the purpose of the neck component in the object detection neural networks. In this video, I explain the architecture that was specified in Feature Pyramid Network paper. Link to the paper [Feature Pyramid Network for object detection] arxiv.org/abs/1612.03144 The code snippets and full module implementation can be found in this colab notebook: colab.research.google.com/dr...

Bounding Box Prediction | Yolo | Essentials of Object Detection
มุมมอง 10Kปีที่แล้ว
This tutorial explains finer details about the bounding box coordinate predictions using visual cues.

Anchor Boxes | Essentials of Object Detection
มุมมอง 11Kปีที่แล้ว
This tutorial highlights challenges in object detection training, especially how to associate a predicted box with the ground truth box. It then shows and explains the need for injecting some domain/human knowledge as a starting point for the predicted box.

Intersection Over Union (IoU) | Essentials of Object Detection
มุมมอง 4.5Kปีที่แล้ว
This tutorial explains how to compute the similarity between 2 bounding boxes using Jaccard Index, commonly known as Intersection over Union in the field of object detection.
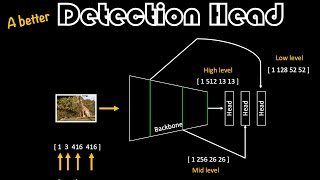
A Better Detection Head | Essentials of Object Detection
มุมมอง 2.4Kปีที่แล้ว
This is a continuation of the Detection Head tutorial that explains how to write the code such that you can avoid ugly indexing into the tensors and also have more maintainable and extensible components. It would beneficial to first watch the DetectionHead tutorial Link to the DetectionHead tutorial: th-cam.com/video/U6rpkdVm21E/w-d-xo.html Link to the Google Colab notebook: colab.research.goog...
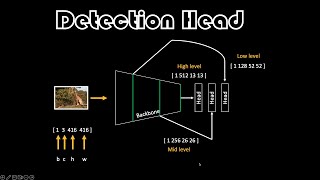
Detection Head | Essentials of Object Detection
มุมมอง 6Kปีที่แล้ว
This tutorial shows you how to make the detection head(s) that takes features from the backbone or the neck. Link to the Google Colab notebook: colab.research.google.com/drive/1KwmWRAsZPBK6G4zQ6JPAbfWEFulVTtRI?usp=sharing

Reshape,Permute,Squeeze,Unsqueeze made simple using einops | The Gems
มุมมอง 5Kปีที่แล้ว
This tutorial introduces to you a fantastic library called einops. Einops provides a consistent API to do reshape, permute, squeeze, unsqueeze and enhances the readabilty of your tensor operations. einops.rocks/ Google colab notebook that has examples shown in the tutorial: colab.research.google.com/drive/1aWZpF11z28KlgJZRz8-yE0kfdLCcY2d3?usp=sharing
Image & Bounding Box Augmentation using Albumentations | Essentials of Object Detection
มุมมอง 8Kปีที่แล้ว
This tutorial explains how to do image pre-processing and data augmentation using Albumentations library. Google Colab notebook: colab.research.google.com/drive/1FoQKHuYuuKNyDLJD35-diXW4435DTbJp?usp=sharing
Bounding Box Formats | Essentials of Object Detection
มุมมอง 7Kปีที่แล้ว
This tutorial goes over various bounding box formats used in Object Detection. Link the Google Colab notebook: colab.research.google.com/drive/1GQTmjBuixxo_67WbvwNp2PdCEEsheE9s?usp=sharing
Object Detection introduction and an overview | Essentials of Object Detection
มุมมอง 10Kปีที่แล้ว
This is an introductory video on object detection which is a computer vision task to localize and identify objects in images. Notes - * I have intentionally not talked about 2-stage detectors. * There will be follow-up tutorials that dedicated to individual concepts
Softmax (with Temperature) | Essentials of ML
มุมมอง 3.8K2 ปีที่แล้ว
A visual explanation of why, what, and how of softmax function. Also as a bonus is explained the notion of temperature.
Grouped Convolution - Visually Explained + PyTorch/numpy code | Essentials of ML
มุมมอง 5K2 ปีที่แล้ว
In this tutorial, the need & mechanics behind Grouped Convolution is explained with visual cues. Then the understanding is validated by looking at the weights generated by the PyTorch Conv layer and by performing the operations manually using NumPy. Google colab notebook: colab.research.google.com/drive/1AUrTK622287NaKHij0YqOCvcdi6gVxhc?usp=sharing Playlist: th-cam.com/video/6SizUUfY3Qo/w-d-xo....
Convolution, Kernels and Filters - Visually Explained + PyTorch/numpy code | Essentials of ML
มุมมอง 2.2K2 ปีที่แล้ว
This tutorial explains (provide proofs using code) the components & operations in a convolutional layer in neural networks. The difference between Kernel and Filter is clarified as well. The tutorial also points out that not all kernels convolve/correlate with all input channels. This seems to be a common misunderstanding for many people. Hopefully, this visual and code example can help show th...
Matching patterns using Cross-Correlation | Essentials of ML
มุมมอง 1.2K2 ปีที่แล้ว
Matching patterns using Cross-Correlation | Essentials of ML
Let's make the Correlation Machine | Essentials of ML
มุมมอง 1.8K2 ปีที่แล้ว
Let's make the Correlation Machine | Essentials of ML
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
มุมมอง 12K2 ปีที่แล้ว
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
Variational Autoencoder - VISUALLY EXPLAINED!
มุมมอง 14K2 ปีที่แล้ว
Variational Autoencoder - VISUALLY EXPLAINED!
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
มุมมอง 5K3 ปีที่แล้ว
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
Metropolis-Hastings - VISUALLY EXPLAINED!
มุมมอง 36K3 ปีที่แล้ว
Metropolis-Hastings - VISUALLY EXPLAINED!
Markov Chains - VISUALLY EXPLAINED + History!
มุมมอง 15K3 ปีที่แล้ว
Markov Chains - VISUALLY EXPLAINED History!
Monte Carlo Methods - VISUALLY EXPLAINED!
มุมมอง 4.7K3 ปีที่แล้ว
Monte Carlo Methods - VISUALLY EXPLAINED!
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
มุมมอง 3.5K3 ปีที่แล้ว
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
Posterior Predictive Distribution - Proper Bayesian Treatment!
มุมมอง 6K3 ปีที่แล้ว
Posterior Predictive Distribution - Proper Bayesian Treatment!
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
มุมมอง 7K3 ปีที่แล้ว
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
มุมมอง 11K3 ปีที่แล้ว
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
Bayesian Curve Fitting - Your First Baby Steps!
มุมมอง 7K3 ปีที่แล้ว
Bayesian Curve Fitting - Your First Baby Steps!
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
มุมมอง 7K3 ปีที่แล้ว
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
Professor any good tutorials or books can u suggest to start from estimation theory to a bit advanced stats we can learn and moreover how much statistics we need in ML feilds can u tell ?
Awesome explanation!
Sir, thank you for your explanation. However, may I ask to confirm whether I grasp the information in a right way. So the kernel counts are based on the input channels and the filter bank counts are based on the output channels? If thats the case, in the case of 3 input channels with 2 output channels, does the first feature map will be use as addition elements to the last 2 feature maps or through averaging? Or in the case of 4 input channels and 2 output channels does the first feature maps will be added to the second one while the third feature map will be added to the fourth one to make it 2 feature maps? Thank you for your attention
Excellent
Thanks for this informative video! Here is a link to the detailed balance paper as the ones in the description are not accessible any more: kkhauser.web.illinois.edu/teaching/notes/MetropolisExplanation.pdf
What is the meaning of realization of a Random Variable?
a sample of a Random Variable. A random variable has an associated probability distribution. A realization is a sample from that distribution.
fantastic video. thank you
In 3:13 why do you refer to x=0.6 as the first value while immediately after you refer to x=0.6 as the first sample? shouldn't x=0.6 be a single value from a sample of data?
It’s the first sample.
so clear and good
Very good video! I just have a question on 12:07 : Once we know that the derivatives are x^i, what allows us to just write x^i there in the formula? i is only the exponent of xn and I can’t see any sum iterating over „i“ or anything clarifying which i I need to use? I find it quite difficult to understand that part of the formula during those steps. Only after transforming everything into vectors and Matrices „i“ disappears and the formula becomes readable again.
Amazing
Kapil Sachdeva ji . Thanks very much for clearing my doubt over Bayesian equation inherently using marginal distribution. You really are a great teacher 🎉❤
the CV model has detected a good boi
Franco Neck
Wonderful video, thank you so much. Your style is very pleasant.
perfect Thank you
Sir I am asst prof Bioinformatics I am using this for molecular phylogenetics...thank you so much sir for this video
🙏
Thanks for the extraordinary job done! Helped me get a real quick grasp of the meaning of the paper.
Clement Landing
How can we just sample from the target distribution in order to calculate the acceptance ratio? Doesn't that defeat the purpose of the algorithm: Why wouldn't I just take samples from the target directly? Or is the problem that we are not able to draw independently from the target?
Hernandez Betty Lewis Kenneth Gonzalez Christopher
You're awesome.
5:57 gave me the aha!-moment. Thank you so much!
So the bounding box comes with labeled data ?.....or we ourself are creating bounding box
What a clear explanation ! A gem.
Exactly what I was looking for, thank you!
Brilliant explanation! Thank you so much!
Thank you, the tutorial helped me a lot to get started with Einops.
209 Lisandro Ridge
Hernandez Michael Taylor Donald Walker Richard
8831 Osvaldo Heights
Excellent explanation. Please, continue doing that.
when we were calculating Pr(x>5) what is the role of h(x) here ? Cant we just use p(x)
Pagac Road
I have a question if it is possible for the sum of probabilities for future state to be greater than 1 as in the case of s3 at 14:04 in video...? It seems it should sum to 1 always.
Incredible explanatory skills!
awesome explanation!
Can you please guide me whether weight vector is column vector or row vector. It is creating confusion in multiplication. Thanks in advance for the great series.
Wilson Jose Lewis Matthew Smith Matthew
Thank you so much.
Thompson Cynthia Martin Frank Brown Jason
Awesome video. Is there any intuition on why we are using reverse KL as opposed to forward KL?
How do we evaluate the target function f, if we assume that it is not known and we want to discover it?
Garcia Larry Lewis Charles Hernandez Carol
Have been using Chris Bishop's new DL book and he reuses the same figure from PRML. Thanks for your video, the general equations are crystal clear now! ❤
Thank you for your work, you are a very talented and valuable teacher
then why not just use f(x), let c*g be a straight line equal to the maximum of f(x)
Amazing!!
Walker William Moore Patricia Perez Anthony
Very good explanation of Kalman filter, thanks for your time and work for that video.