Feature Pyramid Network | Neck | Essentials of Object Detection

ฝัง
- เผยแพร่เมื่อ 13 ต.ค. 2024
- This tutorial explains the purpose of the neck component in the object detection neural networks. In this video, I explain the architecture that was specified in Feature Pyramid Network paper.
Link to the paper [Feature Pyramid Network for object detection]
arxiv.org/abs/...
The code snippets and full module implementation can be found in this colab notebook:
colab.research...
The torchvision has a more flexible implementation which would take more than 3 feature layers from backbone
pytorch.org/vi...








Keep the pearls of wisdom dropping sir..Privilage to learn from you miles across...
🙏 thanks for the kind words.
very helpful! I really like that you're explaining it with an example with concrete numbers!
🙏
Sir, I have a lot of to say after finding your video on TH-cam but just ❤ , respect and thank you. 🙏🙏
🙏
Incredible explanatory skills!
I am so happy I found this video. Really good content!
🙏
Thank you for sharing your knowledge!
🙏
This is excellent! I just love it.
🙏
Excellent tutorial. Thank you very much.
🙏
I like your videos, which are easy and fun to learn. Thanks a lot!
🙏
I have 2 questions. How are the 1X1 and 3X3 CNN used trained to obtain the weight parameters? Also shouldn't 3X3 with stride 1 change the dimension, though it keeps the number of channels the same the size of the output feature would have changed and reduced by 2
How is this different from U-net? I think they're pretty similar if you think that in the U-net you're going down in the encoder, up in the decoder and sideways with the skip connections. It's like an upside-down U-net
is useful to add channel and spatial attention in conv layers to improve
Thank you... excellent clarity... please try to make a tutorial on anchor free detectors like FCOS..
🙏 yup. First need to implement it :)
If done with UNet, it won't require upsampling as we concatenate the layers right?
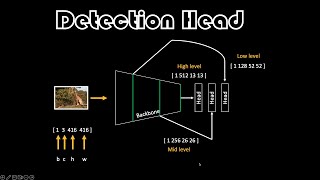
This is quite informative and helpful. Can you please create a video on prediction heads in fpn as in how to assign a predicted bbox to a particular feature map. That would be quite helpful.
Yes, thinking to make some videos about different label assignment techniques.
Now about your question - the right terminology or phrasing of your request would be how to assign an anchor box to a particular feature map.
amazing explanation Dr.
🙏
Could you give a tutorial of diffusing model to your VAE series? Its related and would like to see your explanation!
Though I understand the theory it’s just that I have never implemented/used them myself. I prefer to share those concepts that I have implemented myself and applied on some real world problem.
But not saying no :) maybe one day. Thanks for the ask though.
I don't know if I got this wrong but if I take a 1x64x26x26 feature through a convolution that has a K=3 and S=1, I will definitely not end up with a 1x64x26x26, but with a 1x64x24x24. To achieve the desired shape would require a P=1.
If I'm not correct, would someone please explain how the dimensions would work in this case?
Thanks for sharing the knowledge
Could you give a tutorial on the vision transformer model for object detection?
in some time. have been preoccupied with some stuff but would try my best
Thanks a lot! would be the following videos soon?
🙏 yes.
Do you know how to combine AFPN with the YOLO v8 algorithm? If you know, please tell me. Thanks
what about height and width are odd number (415), sir? In that case, the size after conv and after upsample is miss match. How to fix that, please!
Resize the image to 416 or any other size (e.g. 640) before feeding it to the network.
Instead of doing the upsampling via pytorch module and being angry about it, would it be any more useful to train an additional layer to do the upsampling instead? I'm thinking of a layer analogous to the decoder layer in an autoencoder.
No need to be angry at it :) … yes you could do that. As a matter of fact the additional layers after upsampling is to reduce it effects. The cost would be number of parameters. So it is always a trade off.
@@KapilSachdeva Thank you! informative video btw
🙏
Excellent
thankyou sir !
🙏
thank you for the content , next video soon?
🙏 … yes. Most likely tomorrow. Thanks for keeping me accountable.
@@KapilSachdeva thank you again for the content, looking forward for more of these videos
Still working on the next video; not yet happy with it hence not published yet.
209 Lisandro Ridge
new video when ?
today ... very late sorry :(
Clement Landing
Can you make the video in Urdu language
There are urdu subtitles and may be that will be of some help!
Hernandez Betty Lewis Kenneth Gonzalez Christopher
Haley Corner
Garcia Larry Lewis Charles Hernandez Carol
Walker William Moore Patricia Perez Anthony
Pagac Road
Hernandez Michael Taylor Donald Walker Richard
Wilson Jose Lewis Matthew Smith Matthew
Moore Kevin Moore Sharon Lewis Richard
Thompson Cynthia Martin Frank Brown Jason
8831 Osvaldo Heights