No, they come from the loss function. I explain this at 4:17. It might be a bit unclear so I’ll highly reccomend you watch the video from 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
I'm with @louissimion, you show how dL/dw1 is related to dz1/dw1+... (etc), but you never show/expain where dL/dz1 (etc) comes from. Poof - miracle occurs here. Having a numerical example would help a lot. This "theory/symbology" only post is therefore incomplete/useless from a learing/understanding standpoint.
@@rtpubtubeIt's quite literally what he wrote. He hasn't defined a loss function so that's just what it is from the chain rule. If you're asking how the actual value of dL/dz1 is computed, the last layer has its own set of weights besides the ones shown in the video, in addition to an activation function. You use that and a defined loss function to compute dL/dzi. It's similar to what you see in standard NNs. If you studied neural networks, you should know this. This is a video about CNNs not an intro to NNs. Go study that before this. It's not his job to point out every little thing.
Very well explanation, I search many videos but no body explained regarding change in filter's weight. Thank you so much for this animated simple explanation.
I have seen few videos before, this one is by far the best one. It breaks down each concept and answers all the questions that comes in the mind. The progression, the explanation is best
what an excellent demonstration of the backpropagation on CNN, you won my heart, literally no one on the internet explains it as clearly as you did but please try to make another video as a sequel to this one where you also use the biases, a more complex exampl
This is an exceptional explanation, and I can't thank u more... u have to keep going, u enlighten many student on the planet! that's the best thing a human can do!
your channel is a Hidden Gem..My suggestion is to start a discord and get some crowd functing and one on ones for people who want to learn from you..youa re gifted in teaching.
@@far1din I think I came up with a solution Here def backward(self, output_gradient, learning_rate): kernels_gradient = np.zeros(self.kernels_shape) input_gradient = np.zeros(self.input_shape) for i in range(self.depth): for j in range(self.input_depth): kernels_gradient[i, j] = convolve2d(self.input[j], output_gradient[i], "valid") input_gradient[j] += convolve2d(output_gradient[i], self.kernels[i, j], "same") self.kernels -= learning_rate * kernels_gradient self.biases -= learning_rate * output_gradient return input_gradient First i initialized the kernel gradient as an array of zeros with the kernel shape then I iterated through the depth of the kernels the the depth of the input then for each gradient withe respect to the kernel I did the same to compute the input gradients Your vid helped me understand the backward method better So I have to say thank you sooo much for it
Good job , the explanation is super, I hope you do not stop making videos in this calibre . Did you use manim to make this video or an other video editor?
I'm new to machine learning and neural networks. Your video is very helpful. I have built a small python script just using numpy and I can train numerous samples. So this is a big picture question. Let's say I've trained my program on thousands of inputs and I'm satisfied. Now I want to see if it can recognize a new input, one not used in training. What weight and bias values do I use? After I'm finished with training, how do I modify the script to 'guess?' It would seem to me that back propagation isn't used because I don't actually have a 'desired' value so I'm not going to calculate loss. What weight and bias values do I use from the training sessions? There are dozens of videos and tutorials on training but I think the missing piece is what to do with the training program to make it become the 'trained' program, the one that guesses new inputs without back propagation.
I've had no trouble learning about the 'vanilla' neural networks. Although your videos are great, I can't seem to find resources that delve a little deeper into the explanations of how CNNs work. Are there any resources you would recommend ?
1:15 why do you iterate in steps of 2? If you iterated by 1 then you could generate a 3x3 layer image. Is that just to save on computation time/complexity or is there something other reason for it?
The reason why I used a stride of two (iterations in steps of two) in this video is partially random and partially because I wanted to highlight that the stride when performing backpropagation should be the same as when performing the forward propagation. In most learning materials I have seen, they usually use a stride of one, hence a stride of one for the backpropagation. This could lead to confusion when operating with larger strides. The stride could technically be whatever you like (as long as you keep it within the dimensions of the image/matrix). I could have chosen another number for the stride as you suggested. In that case, with a stride of one, the output would be a 3 x 3 matrix/image. Some will say that a shorter stride will encapsulate more information than a larger one, but this becomes “less true” as the size of the kernel increases. As far as I know there are no “rules” for when to use larger strides and not. Please let me know if this notion has changed as everything changes so quickly in this field! 🙂
@@far1din I never considered how stride length could change depending on kernel size. I guess that makes sense, the larger kernel could cover the same data as a small kernel, just in fewer steps/iterations. I also figured you intentionally generated a 2x2 image since that’s a lot simpler than a 3x3 and this an educational video. Thanks for the feedback, that was really insightful!
5:24 does this just mean we divide z1 by w1 and ultiply by L divided by z1 and do that for all z'S to get the partial derivative of L in respect to w1?
It’s not that simple. Doing the actual calculations is a bit more tricky. Given no activation function, Z1 = w1*pixel1 + w2*pixel2 + w3*pixel3… you now have to take the derivative of this with respect to w1, then y = z1*w21 + z2*w22… take the derivative of y with respect to z1 etc. The calculus can be a bit too heavy for a comment like this. I’ll highly reccomend you watch the video by 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
I explain the term at 4:17. It might be a bit unclear so I’ll highly reccomend you watch the video from 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
You have nices videos, that helped me better understand the concept of CNN. But, from this video, it is not really obvious that matrix dL/dw - is convolution of image matrix and dL/dz matrix, as showed here th-cam.com/video/Pn7RK7tofPg/w-d-xo.html. The stride of two is also a little bit confusing
Thank you for the comment! I believe he is doing the exact same thing (?) I chose to have a stride of two in order to highlight that the stride should be similar to the stride used during the forward propagation. Most examples stick with a stride of one. I now realize it might have caused some confusion :p

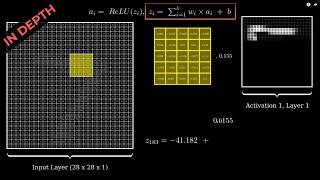








great video, but i don't understand how we can find the value of the dL/dzi terms. At 7:20 you make it seem like dL/dzi = zi, is that correct?
No, they come from the loss function. I explain this at 4:17.
It might be a bit unclear so I’ll highly reccomend you watch the video from 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
I'm with @louissimion, you show how dL/dw1 is related to dz1/dw1+... (etc), but you never show/expain where dL/dz1 (etc) comes from. Poof - miracle occurs here. Having a numerical example would help a lot. This "theory/symbology" only post is therefore incomplete/useless from a learing/understanding standpoint.
@@rtpubtubeIt's quite literally what he wrote. He hasn't defined a loss function so that's just what it is from the chain rule. If you're asking how the actual value of dL/dz1 is computed, the last layer has its own set of weights besides the ones shown in the video, in addition to an activation function. You use that and a defined loss function to compute dL/dzi. It's similar to what you see in standard NNs. If you studied neural networks, you should know this. This is a video about CNNs not an intro to NNs. Go study that before this. It's not his job to point out every little thing.
Why is this channel so underrated? You deserve more subscribers and views.
Perhaps developers use ad blockers, and as a result, TH-cam needs to ensure revenue by not promoting these types of videos (that's my opinion)
Very well explanation, I search many videos but no body explained regarding change in filter's weight. Thank you so much for this animated simple explanation.
Been trying to understand backpropogation in CNN for years until today! Thanks a ton mate!
it was obvious primitive algo dude... people like you are being called "data scientists" now, which is really sad...
@@yosukesharpget off your high horse
This channel is a hidden gem. Thank you for your content
I have seen few videos before, this one is by far the best one. It breaks down each concept and answers all the questions that comes in the mind. The progression, the explanation is best
Thank you! 🔥
This is gold. Watching this after reading Michael Nielsen makes the concept crystal clear
Fantastic explanation!! Very clear and detailed, thumbs up!
Please do not stop making these videos!!!
I won’t let you down Joker 🔥🤝
what an excellent demonstration of the backpropagation on CNN, you won my heart, literally no one on the internet explains it as clearly as you did but please try to make another video as a sequel to this one where you also use the biases, a more complex exampl
Best video to understand what is going on the under the hood of CNN.
What a masterpiece.
You are a great example of fluidity of thought and words..great explanation
Thank you my friend. Hope you got some value! :)
@@far1din sure did
great video, underrated channel , please keep it up with CNN videos!
Couldn’t explain it better myself … absolutely amazing and comprehensible presentation!
what i was looking for. well explained
please continue your videos !!
This is an exceptional explanation, and I can't thank u more... u have to keep going, u enlighten many student on the planet! that's the best thing a human can do!
Thank you brother, very much appreciate it! 🔥
Great explanation. Thank you sir
Great Explanation, helped me understand the background working
your channel is a Hidden Gem..My suggestion is to start a discord and get some crowd functing and one on ones for people who want to learn from you..youa re gifted in teaching.
Well explained now I need to code it my self
Haha, that’s the hard part
@@far1din I think I came up with a solution Here
def backward(self, output_gradient, learning_rate):
kernels_gradient = np.zeros(self.kernels_shape)
input_gradient = np.zeros(self.input_shape)
for i in range(self.depth):
for j in range(self.input_depth):
kernels_gradient[i, j] = convolve2d(self.input[j], output_gradient[i], "valid")
input_gradient[j] += convolve2d(output_gradient[i], self.kernels[i, j], "same")
self.kernels -= learning_rate * kernels_gradient
self.biases -= learning_rate * output_gradient
return input_gradient
First i initialized the kernel gradient as an array of zeros with the kernel shape
then I iterated through the depth of the kernels the the depth of the input then for each gradient withe respect to the kernel
I did the same to compute the input gradients
Your vid helped me understand the backward method better
So I have to say thank you sooo much for it
@@far1din I'll document the solution and but it here when I do please pin the comment
@@SolathPrime That’s great my friend. Will pin 💯
great explanation, clear direct and understandable, sub!
Really intuitive and great animations.
This is a topic which is rarely explained online, but it was very clearly explained here. Well done.
Great explanation with cool visual. Thanks a lot.
Thank you my friend 😃
really clear explanation and good pacing. I felt I understood the math behind back propagation for the first time after watching this video!
excellent. the exact video i was looking for.
Great explanation and visualization
Thank you my friend 🔥🚀
Amazing!
I was looking for some material like this a long time ago and only found it here, beautiful :D
Thank you my brother 🔥
This was really helpful....Thank you so much for the vizualization...Keep up the good work...Looking forward to your future uploads.
Thanks for sharing!
great job. this explanation is really intuitive
Beautiful🙌
Thank you 🙌
great stuff man, crystal clear!
excellent explanation thanks
Glad it was helpful!
Thank you so much!!! This video is so so so well done!
Thank you. Hope you got some value out of this! 💯
the animations were super useful, thanks!
Good job , the explanation is super, I hope you do not stop making videos in this calibre . Did you use manim to make this video or an other video editor?
Best explanation
really beautiful, thanks.
Amazing video!! :D
Thanks! 😄
Masterpiece 💕💕
Thanks a lot!
Nicely put, thank you so much.
Great example thanks a lot
great explanation
Sehr gut
Great video!! Your explanation is the best I have found.
Could you please tell me what software you use for the animations ?
I use manim 😃
www.manim.community
amazing video thanks!
I'm new to machine learning and neural networks. Your video is very helpful. I have built a small python script just using numpy and I can train numerous samples. So this is a big picture question. Let's say I've trained my program on thousands of inputs and I'm satisfied. Now I want to see if it can recognize a new input, one not used in training. What weight and bias values do I use? After I'm finished with training, how do I modify the script to 'guess?' It would seem to me that back propagation isn't used because I don't actually have a 'desired' value so I'm not going to calculate loss. What weight and bias values do I use from the training sessions? There are dozens of videos and tutorials on training but I think the missing piece is what to do with the training program to make it become the 'trained' program, the one that guesses new inputs without back propagation.
Well done.
thanku you so much for this
Amazing
fab video! help me a lot
Glad to hear that you got some value out of this video! :D
I've had no trouble learning about the 'vanilla' neural networks. Although your videos are great, I can't seem to find resources that delve a little deeper into the explanations of how CNNs work. Are there any resources you would recommend ?
tks u very much for this video, but it's probably more helpful if you also add a max pooling layer.
perfect, one suggestion make videos a little longer 20-30 is a good number
Haha, most people don't like these kind of videos too long. Average watchtime for this video is about 3minutes :P
@@far1dinoh shii! 3 minutes, that was very unexpected, maybe it's because people revisit the video to revise specific topic.
Must be 💯
1:15 why do you iterate in steps of 2? If you iterated by 1 then you could generate a 3x3 layer image. Is that just to save on computation time/complexity or is there something other reason for it?
The reason why I used a stride of two (iterations in steps of two) in this video is partially random and partially because I wanted to highlight that the stride when performing backpropagation should be the same as when performing the forward propagation. In most learning materials I have seen, they usually use a stride of one, hence a stride of one for the backpropagation. This could lead to confusion when operating with larger strides.
The stride could technically be whatever you like (as long as you keep it within the dimensions of the image/matrix). I could have chosen another number for the stride as you suggested. In that case, with a stride of one, the output would be a 3 x 3 matrix/image. Some will say that a shorter stride will encapsulate more information than a larger one, but this becomes “less true” as the size of the kernel increases. As far as I know there are no “rules” for when to use larger strides and not. Please let me know if this notion has changed as everything changes so quickly in this field! 🙂
@@far1din I never considered how stride length could change depending on kernel size. I guess that makes sense, the larger kernel could cover the same data as a small kernel, just in fewer steps/iterations. I also figured you intentionally generated a 2x2 image since that’s a lot simpler than a 3x3 and this an educational video. Thanks for the feedback, that was really insightful!
Great explanation. Can you please tell which tool do you use for making these videos.
Thank you my friend! I use manim 😃
www.manim.community
Thanks.
“Beautiful, isn’t it?”
What is the loss function here, and how are the values in the flattened z matrix used to compute yhat ?
Is the stride only along the rows, and not along columns? Is is common or just simplified?
+1 sub, excellent video
Thank you! 😃
5:24
does this just mean we divide z1 by w1 and ultiply by L divided by z1 and do that for all z'S to get the partial derivative of L in respect to w1?
It’s not that simple. Doing the actual calculations is a bit more tricky. Given no activation function, Z1 = w1*pixel1 + w2*pixel2 + w3*pixel3… you now have to take the derivative of this with respect to w1, then y = z1*w21 + z2*w22… take the derivative of y with respect to z1 etc. The calculus can be a bit too heavy for a comment like this.
I’ll highly reccomend you watch the video by 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
thx
What about the weights of the fully connected layer
No point in adding it to this video since that's something you should know from neural networks. That's why he just leaves it as dL/dzi.
dL/dzi = ??
I explain the term at 4:17.
It might be a bit unclear so I’ll highly reccomend you watch the video from 3blue1brown: th-cam.com/video/tIeHLnjs5U8/w-d-xo.htmlsi=Z6asTm87XWcW1bVn 😃
Hello well explained. I need your presentation
Just download it 😂
You have nices videos, that helped me better understand the concept of CNN. But, from this video, it is not really obvious that matrix dL/dw - is convolution of image matrix and dL/dz matrix, as showed here th-cam.com/video/Pn7RK7tofPg/w-d-xo.html. The stride of two is also a little bit confusing
Thank you for the comment! I believe he is doing the exact same thing (?)
I chose to have a stride of two in order to highlight that the stride should be similar to the stride used during the forward propagation. Most examples stick with a stride of one. I now realize it might have caused some confusion :p
original is a matrix of 5x5, kernel is a matrix of 3x3, then output must be a matrix of (5-3+1) x (5-3+1) or 3x3, not 2x2 as your video
The stride used on the example in this video is 2, hence the 2x2 output. You would have been correct if the stride was 1 😄
I think it's spelled "Convolution"
Haha thank you! 🚀
w^* is an abuse of math notation, but it's convenient.