What great content you have, truly, I'm glad I have found you. I really appreciate the raw narrative. I've passed the DP-900 and this is great hands on practice which I'm going to use on some data that I have. I was also thinking to use this project to learn terraform since I was using the azure CLI in a bash script to create things, and looking through your channel I've found great content for Terraform that I'm excited to check out. You definitely deserved more views, keep up the good work
I originally developed this project with your video . I came here because all the code is available for reviewing it if you get stuck. Which makes a huge difference. He also make great job attending sql server connections issues, creating the resources and other thing you fast forwaded.Therefore it took lots of hours to figure it out. WIshing success to both.
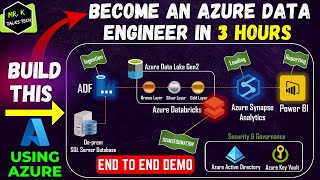
Hi Luke. I recently went through your End-End data engineer project. You explained it very well. Loved the content, was very easy to understand the whole process. i just have a small query, can we build the whole pipeline in synapse rather than ADF as Synapse is built on top of Data lakes?
Hey Harsha, thank you very much! :) Yes, exactly I believe you could as synapse integrates both data lake and data pipeline functionalities, making it an all-in-one platform for both data storage and orchestration.
Hi Luke, Thanks for this. Really well explained. In terms of the business request, if the company wants to understand the gap in customer demographics. What are the additional reasons of running this particular solution and utilising Azure Cloud as opposed to running automated pipelines on-prem? Thanks.
Thank you 🙏 With Azure, you get flexibility to scale up or down as needed, reach customers globally with reliable compliance, and use powerful analytics and AI tools for real-time insights. Plus, Azure's built-in security, backups, and DevOps tools make it way easier and faster to manage without the massive costs and hassle of on-prem setups. It’s like getting enterprise-level power without the usual infrastructure headaches!
Hey Faisal, try the below and let me know how you get on: 1. Create a Service Principal in Azure Active Directory (AAD): - Set up a Service Principal for Databricks to authenticate and access the Azure Data Lake Storage (ADLS). 2. Assign Permissions to the Service Principal: - Grant the Service Principal access to your ADLS account by assigning it the "Storage Blob Data Contributor" role through the "Access Control (IAM)" section in the Azure portal.
Hi bro , if you want more engagement , change titile Azure End-To-End Data Engineering Project for Beginners ( Free Account) | Real Time Tutorial So you are telling people without opening the video that this project is done on free account and make thumbnail like this also. thanks (^_-)
Hi Luke, Can I load my data directly in Azure Synapse without going through Databricks, considering that my data is already structured from SQL Server ?
Yes, absolutely - since you're data is already structured. Depending on your SQL Server version, you might use Azure Synapse Link for seamless integration.
I am struggling with the databricks quota. It keeps saying that I can't make any clusters using the free azure trial any idea how to fix that ? I tried a couple of ways but it says azure trial doesn't allow upgrade subscription etc.
Hi! Yes, of course: SELECT s.name AS SchemaName, t.Name AS TableName FROM sys.tables t INNER JOIN sys.schemas s ON t.schema_id = s.schema_id WHERE s.name = 'SalesLT'
Hi Luke, On 53:52 my debug step is failing with error - ErrorCode=Unknown,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=An unknown error occurred.,Source=Microsoft.DataTransfer.Common,''Type=JNI.JavaExceptionCheckException,Message=Exception of type 'JNI.JavaExceptionCheckException' was thrown.,Source=Microsoft.DataTransfer.Richfile.HiveOrcBridge,' I did search on internet but I am unable to understand whats the issue is. Can you please share what it might be. The data is being read from on prem sql but not being written in Datalake It works when I select the data format as CSV in Sink section
Hmmmm... The error you're encountering, JNI.JavaExceptionCheckException, often suggests an issue related to Java dependencies or the Java Runtime Environment (JRE) within your integration setup in Azure Data Factory (ADF) or Databricks, particularly when dealing with formats like ORC or Parquet for data transformations. This exception can stem from: Missing or Incorrect Java Version Integration Runtime Configuration ORC vs. CSV Compatibility Parquet and ORC Format Settings Try running the same operation using Databricks or another tool that provides more specific error logging to narrow down the cause. If the error persists, providing these logs might offer deeper insights into the Java exception.
I got the same error, and I don't have java installed on my machine. I went ahead and installed it, now the error is gone. Please check if JRE is installed on your machine.









What great content you have, truly, I'm glad I have found you. I really appreciate the raw narrative. I've passed the DP-900 and this is great hands on practice which I'm going to use on some data that I have. I was also thinking to use this project to learn terraform since I was using the azure CLI in a bash script to create things, and looking through your channel I've found great content for Terraform that I'm excited to check out. You definitely deserved more views, keep up the good work
Hey man, thank you - I really appreciate your comment. I'm glad it helped.
If you have anything else you wanna see just let me know :)
1st View, 1st Like. All the best. Your video Added to playlist and will be watched soon. Thanks for the project.
Thanks Rakshith 🙏 I hope it helps.
Could u please put the github link for the projects in the description because i want to see the documentation
In description now mate!
LOL, you didn't even watch the video and said you were the view and like. Shameless!
thank you so much, seeing you covering the sql server parts, i was like confusing and dont knwo what to do
Would've been nice to get some credit for using my video as a reference. Please do it in the future. Good luck with yours, though :)
Hi, at 00:20 I give you credit. Not having your vid in description was simply an oversight - in there now. Likewise :)
@@cloudconsultant Thank you :)
I originally developed this project with your video . I came here because all the code is available for reviewing it if you get stuck. Which makes a huge difference. He also make great job attending sql server connections issues, creating the resources and other thing you fast forwaded.Therefore it took lots of hours to figure it out. WIshing success to both.
@@MexiqueInc That's great to know, happy his video is adding more value :)
@@MexiqueInc Thank you 🙏
Hi Luke.
I recently went through your End-End data engineer project. You explained it very well. Loved the content, was very easy to understand the whole process.
i just have a small query, can we build the whole pipeline in synapse rather than ADF as Synapse is built on top of Data lakes?
Hey Harsha, thank you very much! :)
Yes, exactly I believe you could as synapse integrates both data lake and data pipeline functionalities, making it an all-in-one platform for both data storage and orchestration.
Hi Luke,
Thanks for this. Really well explained.
In terms of the business request, if the company wants to understand the gap in customer demographics. What are the additional reasons of running this particular solution and utilising Azure Cloud as opposed to running automated pipelines on-prem?
Thanks.
Thank you 🙏
With Azure, you get flexibility to scale up or down as needed, reach customers globally with reliable compliance, and use powerful analytics and AI tools for real-time insights. Plus, Azure's built-in security, backups, and DevOps tools make it way easier and faster to manage without the massive costs and hassle of on-prem setups. It’s like getting enterprise-level power without the usual infrastructure headaches!
I can't load data from Data lake to Data bricks. What did you do for databricks to give the access of data lake?
Hey Faisal, try the below and let me know how you get on:
1. Create a Service Principal in Azure Active Directory (AAD):
- Set up a Service Principal for Databricks to authenticate and access the Azure Data Lake Storage (ADLS).
2. Assign Permissions to the Service Principal:
- Grant the Service Principal access to your ADLS account by assigning it the "Storage Blob Data Contributor" role through the "Access Control (IAM)" section in the Azure portal.
Hi bro , if you want more engagement , change titile Azure End-To-End Data Engineering Project for Beginners ( Free Account) | Real Time Tutorial
So you are telling people without opening the video that this project is done on free account and make thumbnail like this also.
thanks (^_-)
Let's give it a try ;)
After 4 days, new title and thumbnail with "FREE" in it got 90% of watch time vs. 10% without. Thanks bro 🙏
Hi Luke,
Can I load my data directly in Azure Synapse without going through Databricks, considering that my data is already structured from SQL Server ?
Yes, absolutely - since you're data is already structured. Depending on your SQL Server version, you might use Azure Synapse Link for seamless integration.
I am struggling with the databricks quota. It keeps saying that I can't make any clusters using the free azure trial any idea how to fix that ? I tried a couple of ways but it says azure trial doesn't allow upgrade subscription etc.
Hey, try when you make a new compute cluster using the single node option at the top of the page, not multi node
Hi Luke on 57.13 i can't see the sql script , can you please assist to write it down here on the comments.
Hi! Yes, of course:
SELECT
s.name AS SchemaName,
t.Name AS TableName
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE s.name = 'SalesLT'
wirte or paste the scripts in discription
thanks
Hey Mohammed scripts are on GitHub
Hi bro , can this project be done with azure free account
Sure can mate, I done it all on free account
😍🦸🦸🥰 captivating and outclass. thanks so much
Thank you v much! Glad you enjoyed 😁
Hi Luke, On 53:52 my debug step is failing with error -
ErrorCode=Unknown,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=An unknown error occurred.,Source=Microsoft.DataTransfer.Common,''Type=JNI.JavaExceptionCheckException,Message=Exception of type 'JNI.JavaExceptionCheckException' was thrown.,Source=Microsoft.DataTransfer.Richfile.HiveOrcBridge,'
I did search on internet but I am unable to understand whats the issue is. Can you please share what it might be.
The data is being read from on prem sql but not being written in Datalake
It works when I select the data format as CSV in Sink section
Hmmmm...
The error you're encountering, JNI.JavaExceptionCheckException, often suggests an issue related to Java dependencies or the Java Runtime Environment (JRE) within your integration setup in Azure Data Factory (ADF) or Databricks, particularly when dealing with formats like ORC or Parquet for data transformations. This exception can stem from:
Missing or Incorrect Java Version
Integration Runtime Configuration
ORC vs. CSV Compatibility
Parquet and ORC Format Settings
Try running the same operation using Databricks or another tool that provides more specific error logging to narrow down the cause. If the error persists, providing these logs might offer deeper insights into the Java exception.
I got the same error, and I don't have java installed on my machine. I went ahead and installed it, now the error is gone. Please check if JRE is installed on your machine.