Spark Job, Stages, Tasks | Lec-11

ฝัง
- เผยแพร่เมื่อ 3 ต.ค. 2024
- In this video I have talked about how jobs, stages and task is created in spark. If you want to optimize your process in Spark then you should have a solid understanding of this concept.
Directly connect with me on:- topmate.io/man...
For more queries reach out to me on my below social media handle.
Follow me on LinkedIn:- / manish-kumar-373b86176
Follow Me On Instagram:- / competitive_gyan1
Follow me on Facebook:- / manish12340
My Second Channel -- / @competitivegyan1
Interview series Playlist:- • Interview Questions an...
My Gear:-
Rode Mic:-- amzn.to/3RekC7a
Boya M1 Mic-- amzn.to/3uW0nnn
Wireless Mic:-- amzn.to/3TqLRhE
Tripod1 -- amzn.to/4avjyF4
Tripod2:-- amzn.to/46Y3QPu
camera1:-- amzn.to/3GIQlsE
camera2:-- amzn.to/46X190P
Pentab (Medium size):-- amzn.to/3RgMszQ (Recommended)
Pentab (Small size):-- amzn.to/3RpmIS0
Mobile:-- amzn.to/47Y8oa4 ( Aapko ye bilkul nahi lena hai)
Laptop -- amzn.to/3Ns5Okj
Mouse+keyboard combo -- amzn.to/3Ro6GYl
21 inch Monitor-- amzn.to/3TvCE7E
27 inch Monitor-- amzn.to/47QzXlA
iPad Pencil:-- amzn.to/4aiJxiG
iPad 9th Generation:-- amzn.to/470I11X
Boom Arm/Swing Arm:-- amzn.to/48eH2we
My PC Components:-
intel i7 Processor:-- amzn.to/47Svdfe
G.Skill RAM:-- amzn.to/47VFffI
Samsung SSD:-- amzn.to/3uVSE8W
WD blue HDD:-- amzn.to/47Y91QY
RTX 3060Ti Graphic card:- amzn.to/3tdLDjn
Gigabyte Motherboard:-- amzn.to/3RFUTGl
O11 Dynamic Cabinet:-- amzn.to/4avkgSK
Liquid cooler:-- amzn.to/472S8mS
Antec Prizm FAN:-- amzn.to/48ey4Pj








Directly connect with me on:- topmate.io/manish_kumar25
last wala action hit hua then collect ke lia job bna th waha v toh ek stage bnayega woh include q ni hua
If you don't explicitly provide a schema, Spark will read a portion of the data to infer it. This triggers a job to read data for schema inference. If you disable schema inference and provide your own schema, you can avoid the job triggered by schema inference.
Thanks for your clarification
In Apache Spark, the spark.read.csv() method is neither a transformation nor an action; spark.read.csv() is a method used for initiating the reading of CSV data into a Spark DataFrame, and it's part of the data loading phase in Spark's processing model. The actual reading and processing of the data occur later, driven by Spark's lazy evaluation model.
Fir action jobs kaise ban rahe hai? Mtlb ager action is equal to jobs , to better way kya hai find out kerne ka?
If you don't explicitly provide a schema, Spark will read a portion of the data to infer it. This triggers a job to read data for schema inference.
bro next level ka explanation tha... thanks for sharing your great knowledge. keep up the good work. Thanks
1 job for read,
1 job for print 1
1 job for print 2
1 job for count
1 job for collect
total 5 jobs according to me but i have not run the code not sure
Yes I also got 5 jobs. Not sure how Manish got only 2
Really Awsome Explanation ! Esa Explanation kabhi or ni mil sakta hai Thank you so much
Bahot shandaar explanation
One of the best videos ever . Thank you for this . Really helpful.
One question:
after groupby by default 200 partitions will be created where each partition will hold data for individual key.
What happens if there are less keys like 100 , will it lead to formation of only 100 partition insted of 200?
AND
What happens if the individual keys are more than 200 in number, will it create more than 200 partitions?
Explained so well that too bit- by- bit 👏🏻
Wow Kya clear explanation tha,first time understood in.one.go
Ek question tha ki, order kya hona chahaye likhne ka, Mtlb ki ager hum filter/select/partition/group by/distinct/count ya or kuch bhi ker rahe hai to, sabsay pehla kya likhna chahaye…
Bro dekho agar optimized way me me likhna chah re ho then first apply filter and then apply transformations.
For example : agar Maan lo k mere pass data hai 100 employees ka or mujhe sirf 90000 se greater salary vaale employees chahiye or mujhe unn sabhi employees ko promotion Krna hai matlab k sabhi ka salary or badhaana hai. Toh suppose iss case me tu pehle transformation lagaoge k salary + vaala then filter kroge toh poora 100 employees ka data scan hoga but agar pehle hi filter laga loge or suppose 90000 se jyada salary vaale sirf 2 log hai toh agar pehle filter laga lenge then we just need to scan only 2 employees data.
Sorry example thoda kharab tha but shyd concept samajh aa gaya hoga.
By the way agar aap pehle transformation lagane k baad bhi filter laga re ho toh bhi koi dikkat nahi hoga kyuki Spark internally is designed in a way k vo optimized tareeke se hi run krega toh jab tumhaara poora operation perform ho gaya uske baad tum jab job hit kroge then it'll first do filter and then apply other transformations on top of it
Spark is very intelligent and will do in optimized way.
I hope this answers your question
very good content. Please make detail videoes on spark job optimization
I have one doubt there are 3 actions are there such as read,collect and count, but why it is creating 2 job only ?
In Apache Spark, the read operation is not considered an action; it is a transformation.
Great Manish. I am grateful to you for making such rare content with so much depth. You are doing a tremendous job by contributing towards the Community. Please keep up the good work and stay motivated. We are always here to support you.
Amazing explanation sir jii
nice explain ,each and every concept you clear keep it up
I really liked this video....nobody explained at this level
Didn't find such a detailed explanation, Kudos
Start a playlist with guided projects ,,so that we can apply these things in real life..
Bhai bahut sahi explain karte ho aap
Thanks Manish Bhai...Please keep continue your video
Thank you so much Manish
kya hota agar filter ke baad ek aur narrow transformation hota like filter --> flatmap--> select iska kitna task banta ?
great job bro, you are doing well.
This was so beautifully explained.
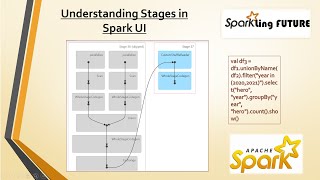
Num Jobs = 2
Num Stages = 4 (job1 = 1, job2 = 3)
Num Tasks = 204 (job1 = 1, job2 = 203)
great explanation :)
bhaiya you are grate
@manish_kumar_1 : correction - job2 - stage2 is till group by, and job2 - stage 3 is till collect
VERY VERY HELPFUL
Very well explained bhai.
When I ran in notebook, it gave 5 jobs like below, and not only 2 for this snippet of code. Can you explain.:
Job 80 View(Stages: 1/1)
Stage 95: 1/1
Job 81 View(Stages: 1/1)
Stage 96: 1/1
Job 82 View(Stages: 1/1)
Stage 97: 1/1
Job 83 View(Stages: 1/1, 1 skipped)
Stage 98: 0/1 skipped
Stage 99: 2/2
Job 84 View(Stages: 1/1, 2 skipped)
Stage 100: 0/1 skipped
Stage 101: 0/2 skipped
Stage 102: 1/1
Excellent explaination. One question, with groupBy 200 tasks are created but most of these tasks are useless right. How to avoid such scenarios. Coz it will take extra effort for spark for scheduling such empty partition task right...
You can repartition it to less number of partition or you can tweak the spark.sql.shuffle.partition config by setting it to desirable number.
Your channel will grow immensely bro. Keep it up❤
Very good explaination bro
I have a question, if one job has 2 consecutive wide dependency transformation then 1 narrow dependency and again 1 wide dependency how many stages will be created. Suppose repartition, after that groupby, then filter and then join, how many stages will this create?
same question
excellent!!
aapne video me 4 stage bnaya but spark ui me 3 hi stage kaise bnane, read me hi toh ek stage bna th
I remember wide dependency you explained in shuffling.
Bhai was eagerly waiting for your videos
count is also a action, so there would be 3 jobs?
good job man
Count bhi ek action hoga na means 3 job create hua
Great Explanation ❤
nice explanation.
glad to see you brother
Nicely explained
thank you sir..
Hi Manish,
in the second job there were 203 tasks and 1st job there was 1, so in total 204 tasks are there in complete application? i am bit confused between 203 and 204.
Kindly clarify..
After repartition(3)
Still 200 default partition will show there on dag Sir
7:40
print is an action ,so it should be 4 job in given code. ryt????correct me if i am wrong
Hi bhaiya. Why havent we considered collect() as a job creator here in the program you discussed?
Hi Manish,
Count() is also an action right ? If not can you please explain what is count()
Hi @manish_kumar_1,
I have one question in wide transformation you said that in groupBy stage3 there will be 200 tasks according to the 200 partitions. But can you tell me why these 200 partitions happened in the first place.
Manish bhai total kitne videos rhenge theory or practical wale series mein?
Sir, in line 14 - we have .groupby and .count
.count is an action, right? Not sure if you missed it by mistake or if it doesn't count as an action? 🙁
I had the same doubt,Did you get the answer to this question? As per the UI also it has mentioned only 2 jobs whereas count should be an action :(
Sir make playlist for other data engineer tools also
Glad to see you manish... Bhai any update on project details?
Bro amazing explanation
An Executor can have 2 partitions or is it like that partitions means it will be there on two different machines.
.count on group dataset is transformation not action, correct ? if it was like employee_df.count() then it would be action
bro, how many more days will spark series take and will you make any complete DE project with spark at last.
BTW watched and implemented all your theory and practical videos. Great sharing❤
what if the spark.sql.shuffle.partitions is set to some value, in this case what will be the no of tasks after/in groupby stage ?
pls enable subtitle bro
@manish_kumar_1 In the previous videos you said like count() as action, but in these video you are not taking that as action, WHY ??
could you please upload the required files, I just want to run and see by myself.
I have been waiting for your video how many more days will it take spark series to complete
df.rdd.getNumPartitions(): Output = 1
df.repartition(5)
df.rdd.getNumPartitions(): Output = 1
Using community databricks sir
Yes I don't see any issue. If you won't assign your repartition df to some variable then you will get same result
why not stage 4, becuse you say each job has minimum one stage and one task so why job 3 don't included to stage and task ?
Same example I tried and in my case, 4 jobs are created. Is there any other config needed?
pls enable subtite in all video bro
bhai job 2 to collect se chalu hoga na? to read ke bad se collect tak job 1 hi chalega na?
Can i know about executors.
How many executors will be there in worker node?
And
Is the no.of executors depend on no.of cores in worker node?
Hii sir, i have one doubt like collect will create the task and stage or not because you mentioned like 203 task
waah
One query @Manish , spark.read is a transformation and not an action right?
df=spark.read.parquet()
print(df.rdd.getNumPartitions())
df=df.repartition(2)
print(df.rdd.getNumPartitions())
df=df.groupby("AccountId").count()
df.collect()
Why this code creates 5 Spark jobs in Databricks?
I've also used 2 actions only
Is 200 default task in group by even if only 3 distinct ages are there?If so what will be there in rest of the 197 task (which age group will be there)
Nice explanation 👌 👍 👏 but can you please explain in English. Every one can see all over the world 🌎 ✨
What command did you use to run the job?
File ka data kaha se lu.. aapne data kaha diya hai
Hi Manish, In databricks also when groupby() invoke it create 200 task by default ? How to reduce 200 task when using group by() for optimizing spark job ?
There is a configuration which can be set. Just google how can I set fix number of partition after join
Count is also an action.
And transformation too
And transformation too
Great explanation manish!!
As per my understanding from the video, total 2 jobs,4 stages,204 tasks will be created
job 1 - Read - which consist 1 stage and 1 task
from job1 -> till job 2 gets created we have 3 stages and 203 tasks
stage 2 - Repartition (wide dependency transformation) - 1 task is created
stage 3 - select and filter(narrow dependency transformation) - 2 tasks are created - > 1 for each transformation
stage 4 - group by(wide dependency transformation) - 200 tasks are created
Plz correct me,if i am wrong
do you have English version of videos
Bhai, I'm using Spark 3.4.1 and in that when I group data using groupby (I have 15 records in dummy dataset) it create 4 jobs to process 200 partitions why ? Is this the latest enhancement ? and not only in latest version but also in spark 3.2.1 I observed same thing. Could you please explain this ?
bhai job action pe create hota h but no. of action != no of jobs. kyonki jobs create hota h jab new rdd ka jarurat hota h. in groupby we need shuffling of data aur rdd immutable hota h to naya rdd banana hi padta h after shuffling. isliye jab bhi naya rdd banane ka jarurat hota h to ek job create hota.aapke case 1 job read ke liye, 1 job schema ke liye,1 job shuffling ke liye aur ek job display ke liye.
jo code snipet suru m dikhaya h usme count bhi ek job h right?
Nhi aage ke lecture me aapko pata chalega why
count is also an action , why job not created for it??
Count is an action and transformation both. Aage ke lectures me pata chal jayega
Hi manish, i have a doubt in groupby count is also a action then why it is not counted as a action?
Aage kuch videos me clear ho jayega
koi baat nhi bhaia, bs ye series poora khatam kr dena kyoki etne detail me yt pe kisi nhi nhi btaya hai.
Hi Manish , count is also an action and you have written count just after group by in code snippet,why count is not considered as job here.
Aage me videos me iska explanation mil jayega. Count action v hai and transformation v. Kab kon sa hoga uske liye aage videos me detailed me explain kara hai
why was count() not counted as action while countuing in jobs ?
Aage ke lecture me samjh me aayega
Thanks Sir
count() bhi to action h na sir?
Aage ke lecture me aapko pata chalega. It is both action and transformation.
Bhai mujhe toh ye 3 jobs, 3 stages and 4 tasks dikha raha. Job 0 for load with 1 task --> Job 1 for collect with 2 task --> Job 3 for collect with 1 task but is showing skipped. Didn't get whats wrong used the same code data but used different data 7MB size.
No need to get to rigid here. Spark bahut saare optimization karta hai and multiple time some jobs get skipped. Maine controlled environment me Kiya tha to show how does that work. During project development you are not going to count how many jobs,stages or task are there. So even if you don't get the same number just chill
I have executed the same job, but it created 4 jobs with each having 1 stage and 1 task.
I think for every wide transformation, it created a new job. Please please confirm and guide.
bhai job action pe create hota h but no. of action != no of jobs. kyonki jobs create hota h jab new rdd ka jarurat hota h. in groupby we need shuffling of data aur rdd immutable hota h to naya rdd banana hi padta h after shuffling. isliye jab bhi naya rdd banane ka jarurat hota h to ek job create hota.
203 task or 204 task plz clear this
So if any group by is there we have to consider 200 task?
Yes if aqe is disabled. If it is enabled then count depends on data volume and default parallelism
Hi Manish, can you make same content in English
I am planning to shoot whole spark series in English too. But not yet finalized when will I start
@@manish_kumar_1thanks