Thank you so much analytics Vidhya. I must commend you all for my improvement in deploying ML algorithms in solving problems. Just an observation please, I think it would be better if we can get the slide for all the data sets used in all lectures. thank you. Much love from Nigeria.
thank you so much miss. my question is can I use the undersampling technique before splitting the dataset into training and testing sets because there is not any data leakage when we use this method
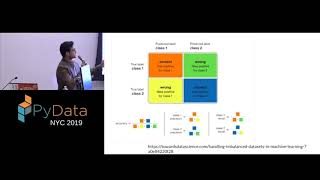
You're absolutely right that undersampling can be done before splitting the dataset in imbalanced classification problems. In fact, it's generally considered the preferred approach to avoid data leakage! Here's why: ➡️ Data leakage: If you undersample after splitting, some minority class instances might accidentally leak into the test set, making your model's performance seem better than it truly is on unseen data. ➡️ Preserving real-world distribution: Undersampling before the split ensures the training set reflects the actual imbalance in your real-world data, leading to a model that generalizes better. However, keep in mind that undersampling also has drawbacks like losing potentially valuable minority class data. It's always a good idea to compare different techniques like oversampling or SMOTE before making a final decision.









Thank you so much analytics Vidhya. I must commend you all for my improvement in deploying ML algorithms in solving problems. Just an observation please, I think it would be better if we can get the slide for all the data sets used in all lectures. thank you. Much love from Nigeria.
Dear Learner, Refer to our DataHack Platform for DataHour Material and Speaker Coordinates: datahack.analyticsvidhya.com/contest/all/
Great tutorial on imbalanced data 👍Analytics Vidya Can you please share the notebook.
Dear Shreyashi, here's the download link: drive.google.com/drive/folders/1KV-CNZmuy8sqYDc1Jri-hCvYCeHSbYxs?usp=sharing
@@Analyticsvidhya Thank you so much! 👍
thank you so much miss. my question is can I use the undersampling technique before splitting the dataset into training and testing sets because there is not any data leakage when we use this method
You're absolutely right that undersampling can be done before splitting the dataset in imbalanced classification problems. In fact, it's generally considered the preferred approach to avoid data leakage!
Here's why:
➡️ Data leakage: If you undersample after splitting, some minority class instances might accidentally leak into the test set, making your model's performance seem better than it truly is on unseen data.
➡️ Preserving real-world distribution: Undersampling before the split ensures the training set reflects the actual imbalance in your real-world data, leading to a model that generalizes better.
However, keep in mind that undersampling also has drawbacks like losing potentially valuable minority class data. It's always a good idea to compare different techniques like oversampling or SMOTE before making a final decision.
Great seminar. Is the code publicly available?
Dear Learner, Refer to our DataHack Platform for DataHour Material and Speaker Coordinates: datahack.analyticsvidhya.com/contest/all/
The talk fails to cover how to deal with imabalnced datasets using SMOTE, and also using Focal Loss for Neural Nets
DataHour Resources 🔗 bit.ly/3xUaue4
Can I use oversampling , if I have multi label text for classification purpose??
Dear Learner, Refer to our DataHack Platform for DataHour Material and Speaker Coordinates: datahack.analyticsvidhya.com/contest/all/