the output of the EEG Devices not looks like what you showed in the video, Can you explain more what did you do in per-processing & feature extraction process ? Also what and how many channels used for this dataset ?
Hi, I have some questions, how many channels and at which sampling frequency it was recording. Do you know which channel show the most accuracy? Did you do any processing steps? How many people was recorded for the dataset?
I think this tutorial did not explain the preprocessing of EEG data, rather it explains how to classify emotions using RNN. Did you apply any techniques to extract features from EEG data?
Hello, Does someone know to what correpond the features of the data set plz ?! There are more than 2000 features. Can it be the measures of the signal at any time t for t in range (1,2000) for example? Or is there a transformation of the data ? Calculate the mean of each signal, the energy, and then find 2000 transformations.
Mir Ali I need your help. I have multiple EEG files as CSV. Each csv file for one subject and contains 64 rows which are the channels and more than 5000 columns which are the electrodes readings from each channel with no labels. Part of the files for patient with pain and the other are without pain. The questions are: 1. Do I need to lable each row in the file because I want to use them for classification. 2. If yes how can I do the labeling? 3. Do I need to merge the file in one single csv file. 4. Are the lables for all the file the same let's say the pain file? Thansk in advance I hole you answe my questions I know they're too much but really I'm new to this feild.
yes youll be needing to label them and you can do by first creating groups of patients with pain and patients with no pain. For labels for example you can label patients with pain as 0 and the other with 1.
I don't know if you were able to get an answer but I'm answering for other people who might need this: 1. Normally channels are in columns and the data for each data point recorded is in row, so the data should look like 5000 rows and 64 columns. I'm assuming you can load csv into dataframe then you can do this by using transpose function in Pandas which is basically df = df.T 2. You can then label the channels with df.columns= ['ch1', 'ch2', ... , 'ch64'] 3. Its better to have a single dataframe of all the participants so that you can input the data into the model for classification, also helps with shuffle, normalize, etc if the data is in a single df 4. In this video the data shown is already preprocessed, so the column names that you see (eg. fft_740_b) are the features extracted from raw channel data. You can check eeglib library which extracts some of the features in a very easy format

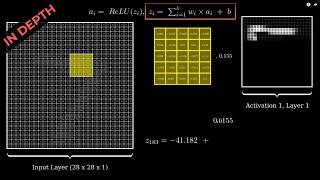








excellent explanation! please share more videos about emotion recognition based on EEG.
Thanks very much for the video for doing awesome job.. Hope you make more videos about EEG
the output of the EEG Devices not looks like what you showed in the video, Can you explain more what did you do in per-processing & feature extraction process ?
Also what and how many channels used for this dataset ?
Sir can I know what does the label name indicate???(mean_0_a, mean_0_b,......etc)
Thanks a lot for explaining the code.
Hi, I have some questions, how many channels and at which sampling frequency it was recording. Do you know which channel show the most accuracy? Did you do any processing steps? How many people was recorded for the dataset?
I think this tutorial did not explain the preprocessing of EEG data, rather it explains how to classify emotions using RNN. Did you apply any techniques to extract features from EEG data?
Did you get any answer about preprocessing? how did he get mean, covmat and all those values?
hello can you post the data again because it is not downloading properly.
Hello,
Does someone know to what correpond the features of the data set plz ?!
There are more than 2000 features. Can it be the measures of the signal at any time t for t in range (1,2000) for example? Or is there a transformation of the data ?
Calculate the mean of each signal, the energy, and then find 2000 transformations.
How did you arrange your dataset?
Could anyone explain the features(columns) in the dataset
did you get any answer?
@@vanessaclavijo5073 no not yet still searching in many sources but no use
Hi, Pls help me with the following error (AttributeError: module 'keras.api._v2.keras.callbacks' has no attribute 'Earlystooping')
its EarlyStopping not 'Earlystooping'
Sir while i am running the epoch line it is showing alla error
is it DEAP dataset?
Mir Ali I need your help. I have multiple EEG files as CSV. Each csv file for one subject and contains 64 rows which are the channels and more than 5000 columns which are the electrodes readings from each channel with no labels. Part of the files for patient with pain and the other are without pain.
The questions are:
1. Do I need to lable each row in the file because I want to use them for classification.
2. If yes how can I do the labeling?
3. Do I need to merge the file in one single csv file.
4. Are the lables for all the file the same let's say the pain file?
Thansk in advance I hole you answe my questions I know they're too much but really I'm new to this feild.
I also need know something like this. Can you help me. Tks
@@vuhathanh4623 did you find the way of doing that ?
read Pandas documentation u will be able to it, it's pretty easy
yes youll be needing to label them and you can do by first creating groups of patients with pain and patients with no pain.
For labels for example you can label patients with pain as 0 and the other with 1.
I don't know if you were able to get an answer but I'm answering for other people who might need this:
1. Normally channels are in columns and the data for each data point recorded is in row, so the data should look like 5000 rows and 64 columns. I'm assuming you can load csv into dataframe then you can do this by using transpose function in Pandas which is basically df = df.T
2. You can then label the channels with df.columns= ['ch1', 'ch2', ... , 'ch64']
3. Its better to have a single dataframe of all the participants so that you can input the data into the model for classification, also helps with shuffle, normalize, etc if the data is in a single df
4. In this video the data shown is already preprocessed, so the column names that you see (eg. fft_740_b) are the features extracted from raw channel data. You can check eeglib library which extracts some of the features in a very easy format
sir, can you help me please in this rnn.