Hi Nick, I do not have a question but I would like to highlight again that your channel is remarkable. As far as I know, only by following your channel one can capture in a consistent way the latest achievements in SW, especially in excellent C++. It is a huge distinction to be here. Additionally, I appreciate your effort used for the preparation video each day. I have been using C++ for over 2 decades mostly within the robotics domain. Your impressive work gives all of us (the community) a new look at this beauty and encourages us to study more. Thank you so much. Have a nice day!
Thank you for the kind words! Always nice to hear when others enjoy the content. Autonomous robotics was where I got my start in research many years ago (primarily with SLAM) before moving more into the architecture/performance side of things. Cheers, --Nick
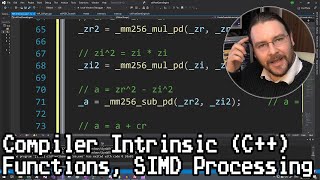
Hey Nick, amazing videos as always! Compiling with -ffast-math seems to unlock intrinsics for the transform_reduce baseline as well. Btw your videos are very inspirational, keep it up!
The performance benefit of using SIMD intrinsics is really impressive! I wonder how often the use of SIMD instructions could speed up every day computing tasks. My really blind guess would be that they are very underused even in computing intensive software. Thanks Nick for this fantastic series so far!
Glad you enjoyed it! For many cases, the auto-vectorizer code is good enough. There can be an incredibly high software development cost for using low-level intrinsics (programming in assembly can be tricky work). There are great examples though of code written entirely/almost entirely in assembly. Intel's MKL (math kernel library) is a great example (along with many high-performance linear algebra libraries out there). Cheers, --Nick
Hi nick, I just read about the alignment, and I would like to know why is it an improvement to align at 32 and not 64.. because 64 alignment (on 64bit system) would mean worst case of 4 cache misses and read of 64 bytes, while alignment of 32 would mean worst case of 6 cache misses. Unless we are talking in 32bit system. again, I might be wrong with how I perceived the cache, but I figured I will just ask while I still read about it. Thanks alot
Thanks for the suggestion, and glad you enjoyed the video :^) I would like to do more ARM-based performance videos, but unfortunately, I don't have an ARM proc at this moment, so it's a non-starter until that changes. Cheers, --Nick
Why was it that the compiler did not recognize that it could use the vdpsp instruction? you did mention something about the compiler implementation, but dot product seems like something it should be able to figure out...
If I recall correctly, it's because of the compiler's guarantees about the floating point arithmetic. Compilers will guarantee floating point results (regarding the ordering and precision being used) to give repeatable results across platforms. Vector dot product I believe uses a higher precisions for intermediate operations, and only rounds the final results, therefore giving a different result than if you were to do a dot product in a standard way, floating point standard compliant way. That result will often be more accurate than the standard calculation, but it is non-portable (because intrinsics are hardware specific)
SIMD should be designed like a GPU kernel, to execute one stream of instructions on arbitrary amounts of independent data, instead of simply making a normal program that operates on 4 or 8 or 16 values at once. It just doesn't lend itself well to arbitrary processing the way it is currently common.









Hi Nick, I do not have a question but I would like to highlight again that your channel is remarkable. As far as I know, only by following your channel one can capture in a consistent way the latest achievements in SW, especially in excellent C++. It is a huge distinction to be here. Additionally, I appreciate your effort used for the preparation video each day. I have been using C++ for over 2 decades mostly within the robotics domain. Your impressive work gives all of us (the community) a new look at this beauty and encourages us to study more. Thank you so much. Have a nice day!
Thank you for the kind words! Always nice to hear when others enjoy the content. Autonomous robotics was where I got my start in research many years ago (primarily with SLAM) before moving more into the architecture/performance side of things.
Cheers,
--Nick
Hey Nick, amazing videos as always! Compiling with -ffast-math seems to unlock intrinsics for the transform_reduce baseline as well. Btw your videos are very inspirational, keep it up!
The performance benefit of using SIMD intrinsics is really impressive! I wonder how often the use of SIMD instructions could speed up every day computing tasks.
My really blind guess would be that they are very underused even in computing intensive software.
Thanks Nick for this fantastic series so far!
Glad you enjoyed it! For many cases, the auto-vectorizer code is good enough. There can be an incredibly high software development cost for using low-level intrinsics (programming in assembly can be tricky work).
There are great examples though of code written entirely/almost entirely in assembly. Intel's MKL (math kernel library) is a great example (along with many high-performance linear algebra libraries out there).
Cheers,
--Nick
@@CoffeeBeforeArch Well, that is true. I guess there are many libraries for common algorithms that make good use of SIMD instructions. Good point!
Hi nick, I just read about the alignment, and I would like to know why is it an improvement to align at 32 and not 64.. because 64 alignment (on 64bit system) would mean worst case of 4 cache misses and read of 64 bytes, while alignment of 32 would mean worst case of 6 cache misses.
Unless we are talking in 32bit system.
again, I might be wrong with how I perceived the cache, but I figured I will just ask while I still read about it.
Thanks alot
Is it possible for you to also cover Arm Neon intrinsics if its possible?
This is a good topic and a good video :)
Thanks for the suggestion, and glad you enjoyed the video :^)
I would like to do more ARM-based performance videos, but unfortunately, I don't have an ARM proc at this moment, so it's a non-starter until that changes.
Cheers,
--Nick
Why was it that the compiler did not recognize that it could use the vdpsp instruction? you did mention something about the compiler implementation, but dot product seems like something it should be able to figure out...
If I recall correctly, it's because of the compiler's guarantees about the floating point arithmetic.
Compilers will guarantee floating point results (regarding the ordering and precision being used) to give repeatable results across platforms.
Vector dot product I believe uses a higher precisions for intermediate operations, and only rounds the final results, therefore giving a different result than if you were to do a dot product in a standard way, floating point standard compliant way. That result will often be more accurate than the standard calculation, but it is non-portable (because intrinsics are hardware specific)
@@CoffeeBeforeArch great, thank you fir the explanation and the content!
It’s unfortunate that SIMD doesn’t fit so may practical scenarios.
SIMD should be designed like a GPU kernel, to execute one stream of instructions on arbitrary amounts of independent data, instead of simply making a normal program that operates on 4 or 8 or 16 values at once. It just doesn't lend itself well to arbitrary processing the way it is currently common.