This is the best SIMD intro I've seen. And the bonus (relevant) humor really helped give the topics some breathing room to let them sink in. Just an overall outstanding presentation.
This video and your channel generally needs much much more attention! I'm just starting out on SIMD and man, the serious yet funny and very clear explanation of how everything works is amazing! I rarely subscribe to channels just by watching one video... I think it has happened less than the number of fingers I have on one hand but your channel was one of them! Amazing job! Keep it up!
This was such an awesome video! I assume this is for some kind of university course (which I'm not part of) but I never used AVX instructions before and yet I could easily follow the video. I enjoyed all the jokes and the examples really helped. It really didn't feel like an entire hour video! I might give AVX a try in the future :)
Thanks for your wonderful video. I'm a newly CPU engineer and responsible for the uach of FP aprt. This vedio truly provides me a new aspect to understand vectorization and SIMD. Thank u!!!
Hello, Joel! I have one issue for u. When u mentioned FMA3 instruction and its calculation ordering, I found it's not matched with the Intel manual when meets VFMADD231PS. The "231" in mnemonics indicates that O1 should be a multiplier, O2 should be adding part and O3 should be a multiplicand according to the Intel Developer's Manual. It seems right for the O1*O3+O2=O1 formulation, but your slide and the intel manual say it should be O2*O3+O1=O1. I want to figure out why?
This was entertaining and insightful at the same time! Cleared so many confusions I had since I mainly work with Python and deep learning. The production quality (audio+video) too is outstanding! Looking forward to more videos :)
Glad to hear it. Different topic from most of my videos. The official Intel intrinsics guide is comprehensive, but it's pretty intimidating when you're first starting out. Especially for the more complicated instructions, and especially given the guide has no diagrams.
This is great! Any chance you could make an intrinsics best practices video? I can't really find anything like that on TH-cam or elsewhere. All I've been able to find is stackoverflow sample code with no explanations of why things are done the way they are. ie why its common to group similar intrinsics together: load, load, load, load, add, add add, add, store, store, store store. Why not load, add, store, load, add, store, load, add, store, load, add, store? The tip about creating an array of __mm256d is pretty interesting. I am going to have to try that in my current project where I'm trying to ensure all 16 AVX2 vector registers (or as close as possible) are in use in a 3GB+ matrix MaxPlus algorithm. In some quick test code I wrote, using an element in the array disassembles to a vmovupdy just like a regular _mm256_load_pd does. I'm surprised it doesn't use vmovapdy since the memory is aligned. Adding __assume_aligned didn't help either I'm using the Intel icc compiler. Hmmm...
The handling of the return values-which are an array for vector output and a single number for regular scalar output-is not covered. Put differently, how are you handling the outcome and what are you doing during accumulation?
Nothing wrong with those intrinsics, I use them sometimes, I just couldn't get through all the instructions because there's so many. Mostly I just wanted to give people a taste of the most common ones and what kinds of operations exist. Also should be a good start-off point for learning the other intrinsics that I didn't cover.
Not aware of any fundamental reason, but I think it's just to keep with convention of how you normally write numbers from least significant digit to most significant digit right-to-left. Think of it as one big 256-digit binary number, just like you'd write a decimal number '1234' meaning one thousand, two hundred and thirty-four, with the least significant digit is on the right, and then you work to the left with each digit being a higher-power of 10. Same idea, except this is binary. Or in C/C++, if you were writing a binary number it'd be 0b1101010101, with the least significant bits on the right. The confusion can be if you're thinking of it like an array in C/C++, where you'd define it left-to-right, A = {0,1,2,3} where the first element is on the left. Don't get me wrong, you can also think of the AVX blocks as little arrays, it's just the way they're normally illustrated is such that the significance of the bits in the whole block increase from right-to-left, like one big number (even if you address them as blocks of individual numbers). Then no matter how you slice it, every chunk would just read like it's own binary number right-to-left.
13:19 Did you mean to write sumTotal256 = _mm256_add_ps(*A256++, sumTotal256); assuming __m256 *A256 = (__m256 *)A; ? Otherwise this only will work if all elements of array A are equal.
yeah I think what I was probably trying to write was sumTotal256 = _mm256_add_ps(A256[i],sumTotal256); and then the for loop itself should iterates, i++ instead of i+=8, and then the loop runs to i
@@joelacarpenter Thank you for responding and making this video! You have given a nice overview of the intrinsics available and your visualizations have been very helpful to me in deciphering the operation syntax on the Intel intrinsics guide
@@joelacarpenter again at 13:19 shouldn't the integers be 32 bits in size ? 8 integers * 32 bits = 256 bits but the ints on the slides are 64 bits, 8 ints * 64 = 512 bits
@@olegpatraschku3736 Are you talking about the int64, 'i' that I've used as the index? That's just for addressing the array (rather than the number format of the data inside the array itself). Normally I'd use 'size_t' rather than '__int64' for the index for potentially large arrays. The arrays themselves in this case as 'ps' which are 'packed singles' which are 8xfloat32
@@joelacarpenter my mistake, it all made sense later on as I continued to watch the video :), content is very good ! (my personal "struggle" was about this "lane" concept, I don't think I understood it fully why is it designed like this...)









This is the best SIMD intro I've seen. And the bonus (relevant) humor really helped give the topics some breathing room to let them sink in. Just an overall outstanding presentation.
This video and your channel generally needs much much more attention! I'm just starting out on SIMD and man, the serious yet funny and very clear explanation of how everything works is amazing!
I rarely subscribe to channels just by watching one video... I think it has happened less than the number of fingers I have on one hand but your channel was one of them!
Amazing job! Keep it up!
At the moment, this is the best SIMD video I've seen! Thank you very much!
Educational, funny, and engaging for such a topic. I don't know what more one could ask for.
Literally the best SIMD video ong
Literally the best lecture I've ever seen in my entire life. Very good job, and a very big thank you for this!
This was such an awesome video! I assume this is for some kind of university course (which I'm not part of) but I never used AVX instructions before and yet I could easily follow the video. I enjoyed all the jokes and the examples really helped. It really didn't feel like an entire hour video! I might give AVX a try in the future :)
Was stuck on the alignment issue since yesterday. Finally understood what the issue was and solved it. Thank you so much my friend.
Thanks for your wonderful video. I'm a newly CPU engineer and responsible for the uach of FP aprt. This vedio truly provides me a new aspect to understand vectorization and SIMD. Thank u!!!
Hello, Joel! I have one issue for u. When u mentioned FMA3 instruction and its calculation ordering, I found it's not matched with the Intel manual when meets VFMADD231PS. The "231" in mnemonics indicates that O1 should be a multiplier, O2 should be adding part and O3 should be a multiplicand according to the Intel Developer's Manual. It seems right for the O1*O3+O2=O1 formulation, but your slide and the intel manual say it should be O2*O3+O1=O1. I want to figure out why?
I think I was misguided by the gramar. But anyway, u are right! Thanks a lot!
This was entertaining and insightful at the same time! Cleared so many confusions I had since I mainly work with Python and deep learning. The production quality (audio+video) too is outstanding! Looking forward to more videos :)
You got my subscription at the illustration of the composition of two vectors. Thanks :)
This is exactly what I was looking for! Thank you so much.
Amazing video - I appreciate the work that went into this, thank you.
Amazing video. Keep it up!
Amazing, Incredible, Fantastic work!! Wow!
This helps me a lot, thanku!
Glad to hear it. Different topic from most of my videos. The official Intel intrinsics guide is comprehensive, but it's pretty intimidating when you're first starting out. Especially for the more complicated instructions, and especially given the guide has no diagrams.
Best thing on this subject. Thank you very much
actually so helpful, cheers from Berkeley ◡̈
Really good video, found it to be very thorough in the explanation of the basics.
This is great! Any chance you could make an intrinsics best practices video? I can't really find anything like that on TH-cam or elsewhere.
All I've been able to find is stackoverflow sample code with no explanations of why things are done the way they are. ie why its common to group similar intrinsics together: load, load, load, load, add, add add, add, store, store, store store. Why not load, add, store, load, add, store, load, add, store, load, add, store?
The tip about creating an array of __mm256d is pretty interesting. I am going to have to try that in my current project where I'm trying to ensure all 16 AVX2 vector registers (or as close as possible) are in use in a 3GB+ matrix MaxPlus algorithm. In some quick test code I wrote, using an element in the array disassembles to a vmovupdy just like a regular _mm256_load_pd does. I'm surprised it doesn't use vmovapdy since the memory is aligned. Adding __assume_aligned didn't help either I'm using the Intel icc compiler. Hmmm...
Thank you for this video! And very good sense of humor 😂
excellent lecture with great meme. Thx for sharing!
Amazing video! thankyou so much for this
Things is mysterious till someone _hero_ unveiled
Thank you! I love you
Great Lecture!
Such a wonderful video. Thank you!
Awesome video! Thank you!
The handling of the return values-which are an array for vector output and a single number for regular scalar output-is not covered.
Put differently, how are you handling the outcome and what are you doing during accumulation?
Not sure what you're asking, but if you look near the end where I do a complex dot product, you can see some code examples.
8:10 Other than John Ham, Kevin Bacon is one of the best smelling actors around
Does SIMD have a reverse Polish notation similar to the FPU era to optimize performance?
best lecture ever lmao
great work , thanks very much
please where can I find this presentation ???
Hi, could we have access to your wonderful slides?
Why weren't _mm_testz_si128 and _mm_movemask_ps covered? They look pretty useful, are you saying that they should be avoided?
Nothing wrong with those intrinsics, I use them sometimes, I just couldn't get through all the instructions because there's so many. Mostly I just wanted to give people a taste of the most common ones and what kinds of operations exist. Also should be a good start-off point for learning the other intrinsics that I didn't cover.
Is there a reason we are reading the memory bits from right to left?
Not aware of any fundamental reason, but I think it's just to keep with convention of how you normally write numbers from least significant digit to most significant digit right-to-left.
Think of it as one big 256-digit binary number, just like you'd write a decimal number '1234' meaning one thousand, two hundred and thirty-four, with the least significant digit is on the right, and then you work to the left with each digit being a higher-power of 10. Same idea, except this is binary. Or in C/C++, if you were writing a binary number it'd be 0b1101010101, with the least significant bits on the right.
The confusion can be if you're thinking of it like an array in C/C++, where you'd define it left-to-right, A = {0,1,2,3} where the first element is on the left. Don't get me wrong, you can also think of the AVX blocks as little arrays, it's just the way they're normally illustrated is such that the significance of the bits in the whole block increase from right-to-left, like one big number (even if you address them as blocks of individual numbers). Then no matter how you slice it, every chunk would just read like it's own binary number right-to-left.
@@joelacarpenter Thank you so much for explaining!!
Lmao awesome lecture! Thanks!
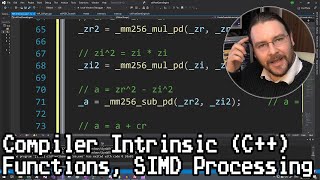
13:19 Did you mean to write
sumTotal256 = _mm256_add_ps(*A256++, sumTotal256);
assuming
__m256 *A256 = (__m256 *)A;
? Otherwise this only will work if all elements of array A are equal.
yeah I think what I was probably trying to write was
sumTotal256 = _mm256_add_ps(A256[i],sumTotal256);
and then the for loop itself should iterates, i++ instead of i+=8, and then the loop runs to i
@@joelacarpenter Thank you for responding and making this video! You have given a nice overview of the intrinsics available and your visualizations have been very helpful to me in deciphering the operation syntax on the Intel intrinsics guide
@@joelacarpenter again at 13:19 shouldn't the integers be 32 bits in size ? 8 integers * 32 bits = 256 bits but the ints on the slides are 64 bits, 8 ints * 64 = 512 bits
@@olegpatraschku3736 Are you talking about the int64, 'i' that I've used as the index? That's just for addressing the array (rather than the number format of the data inside the array itself). Normally I'd use 'size_t' rather than '__int64' for the index for potentially large arrays. The arrays themselves in this case as 'ps' which are 'packed singles' which are 8xfloat32
@@joelacarpenter my mistake, it all made sense later on as I continued to watch the video :), content is very good !
(my personal "struggle" was about this "lane" concept, I don't think I understood it fully why is it designed like this...)
memes were always on point
Everything you said is written in Intel and AMD documentation.
Amazingly useful video thank you!!!