
ฝัง
- เผยแพร่เมื่อ 21 ก.ค. 2024
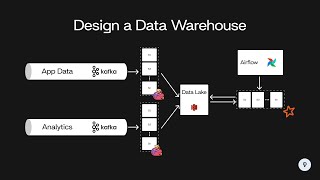
- One common topic that comes up in data engineering interviews is designing streaming architectures. In this video, our data engineering coaches, Rob and Jitesh, will solve a systems design question and walk through the solution using a system diagram tool.
Here's the question we're tackling: www.interviewquery.com/questi...
Follow Jitesh at www.canadiandataguy.com
Rob's company: www.remot.dev
👉 Subscribe to our data science channel: bit.ly/2xYkyUM
🔥 Get 10% off your next interview prep: www.interviewquery.com/pricin...
❓ Check out our data science interview course: www.interviewquery.com/course...
💵Find out more about Data Engineering Salary: www.interviewquery.com/salari...
🔑 Get professional coaching from Rob or Jitesh for your next interview: www.interviewquery.com/coachi...
🐦 Follow us on Twitter: / interview_query
📸Follow us on Instagram: / interview_query
Check out Jitesh's previous mock interviews:
Amazon SQL Mock Interview Question: Conversation Distribution: • Amazon SQL Mock Interv...
Uber Data Engineer Interview: Design a Ride-Sharing Schema: • Uber Data Engineer Int...
00:00- Introduction
00:40- Question
01:20- Clarifying Questions
05:34- Answer
37:20- Follow-up Questions
49:27- Question analysis
49:50- Tips
#dataengineer #amazon #streaming #analytics #dataengineering #datascience #apachespark #aws #apachekafka - วิทยาศาสตร์และเทคโนโลยี






![รวมเพลงลูกทุ่ง 6 หนุ่มไทบ้าน ฮิตติดกระแส ชุดที่ 1 l มนต์แคน ไมค์ ไผ่ เสถียร ไหมไทย พี [Longplay]](http://i.ytimg.com/vi/GD2v1OjMw5I/mqdefault.jpg)

Well, you can build a fact_transaction table which include purchase and return event all together, that way you can track both activities in one fact table
If your table is partitioned with vendor_id - - -> this will cause skewness as per the very early stage discussion, not every vendor will have sales. Wouldn't it better to bucket data by vendor_id and partition by date / interval?
Anyway, long time haven't saw that thorough data engineering interview question, keep it up!
Wow this was so insightful
Why do we need to have spark streaming between Kafka and landing table if the goal is just to copy data as is and there are no transformations required?
If you are not doing transformations you will not need it (just if you have connector issues). just kafka is more than enough.