If you are running a GGUF model, ollama will split the process, putting as many layers as it can on GPU and the rest on CPU. IT will run slower, but faster than CPU only.
Mini PCs have revolutionized the boring PC market. The power they are able to squeeze inside these small boxes gives me hope for the future of computing.
While I agree that they are cool, they kind of become pointless once you add one of these giant eGPUs. You could build a mini itx pc instead and avoid the occulink restrictions while also gaining the increased upgradability of a full desktop.
Mini PCs are (for the most part) just laptop bowels transplanted in a little box. They have use cases, for sure (hospitals, HTPCs, schools, small clients, emulation boxes, offices) but as soon as you ramp up the performances the prices and drawbacks (mainly thermals) go up quickly too, at the point where it's better to stick to a custom build solution unless you REALLY need the small form factor. I admit that the mainstream pc market of today is VERY boring though, it peaked just around pre-covid and stayed there (I'm still using my ryzen 3600 + 6700 xt and I don't feel the need to upgrade to PCIx 5, while I bleeded money into my home server instead).
@@TheRaretunes true. But i hope the tech gets better and better for them. I find pc cases to be really ugly. Didn’t mind them back in the day but those aren’t best for airflow. Talking about airflow, just how much air do you need. I like small itx cases a lot more and surprisingly, they show that you don’t really need that much space for airflow and good temps. “Building computers” is also an overhyped genre. It’s really not all that it’s cracked up to be.
Serious question: why not just use the power directly if you're UPS isn't big enough? This isn't a mission critical server with important information, it doesn't need 24/7 operation during a power outage.
Some points here Alex: 1. The power cable that's split into three power plugs is a "dongle" that converts the 12V HPWR plug that's too recent for most power supplies out there, so they supply a splitter that is powered by 3 or 4 of the 8 pin PCI-E connectors. 2. The drivers for your GPU are provided by Nvidia themselves (just Google game ready drivers for RTX 4090), as the AIB drivers (Gigabyte's) are outdated. 3. All modern GPUs (from 2010 onwards) are all set to have zero fan revs at sub 60° C.
@@R1L1. You're talking about exceptions to the rule, I only recall the Vega VII that had it's fans running all the time because it ran hot as the sun. Apart from that point 3 is the rule.
@@blackhorseteck8381 that doesn't change the fact that you are wrong, you could have just said most modern GPUs not all GPUs . Even then my rx6500xt always keeps the fans on, same with my 3060, didn't change anything after buying so yeah... Idk.
Chinese modders transplanted a chip from RTX 4090D to a custom board or a 3090 board and soldered 48 GB of memory. Real beast for AI rig. However, I'm not sure about the warranty for such Frankenstein card.
It's honestly sad at this point neither nvidia, Intel or amd have come out with a $700 card that just has 48gb vram and a $900 model with 128GB. The memory is cheap as nvidia just wants to squeeze you to spend $2000 on 4090. With Ai now I think at least just 1x consumer model would be good from someone. I mean, you'd sell at least 2m units.
@@Larimussas far as I know nvidia has monopoly over AI due to their CUDA technology. Until amd or intel isn't capable of competing with nvidia in this space, there wouldn't be any card with such memory.
@cena777248 yeh they do for now. Intel has already created some inference with their tech I beleive. And since CPU models exist I'm sure if amd made a cheap 48gb vram card the internet will figure out how to convert models or whatever it is. I'm pretty sure you can run some models with amd too? Just much less support where nvidia just runs everything right now and most optimally I think.
@@Larimuss it’s not good business for the average consumer to have access to good, fast, general-purpose local AI. We’d pay, what, maybe $600 more for that at an enthusiast level, less for the average consumer. But as long as AI remains the domain of big cloud companies and startups backed by VCs with deep pockets, people will keep flocking to them for this seemingly exclusive godlike power, and they will keep paying enterprise money to Nvidia.
small advice regarding ollama: use verbose example: ollama run llama3.1:8b --verbose technically these commands, including what you ran, keeps the model loaded. You have to manually unload it, or you can tell the model to unload after you go /bye: ollama run llama3.1:8b --verbose --keepalive 10s the verbose will tell you the tokens per second generated. the keepalive 10s will drop the model from memory after 10s
I experienced the same VRAM problems. I have a i9-32 thread and 128GB system RAM and runs the large models in slow motion but works. Small models run fast enough to use on the i9, but if it fits the gpu 16GB its really fast and enough to use as a service for a few clients. I'm using 4090 mobile=4080 desktop. Large models, these days, seems the Mac unified ram is the way to go for running large models but slower, but at least it runs and the wait is not too long.
I'm not convinced about the Mac's unified RAM. What all these Mac youtubers don't show you is the impact of larger prompts. While you may be fine with 5tokens/s, it's gonna suck if you have to wait a minute before it even starts to generate something.
ollama is smart enough to use two gpus simultaneously, so for that 40GB LLM you really have to use two gpus with 24GB vram each, once you get over gpu vram capacity, things go into ram and though cpu which is terribly slow - at such point Apple Silicon Macs have advantage of utilizing shared ram, so something like 64GB Mac Studio "outperforms" and PC with lack of gpu vram
I've got a 1080 ti from 2017, and a PC I built in 2016 overclocked to almost 5Ghz, 6 cores 12 threads, with 64 GB Ram I am currently running Llama 3.2 7B models lightning fast with my PC
running "ollama ps" will show you how much of the model is loaded on system ram vs GPU ram. You want 2x4090s for enough VRAM to run a 70b at a good speed.
Also ISTA-DASlab (on huggingface) managed to squeeze original Llama 70B 140Gb model into 22Gb remaining 90+% quality ratio, so it can run on one 3090 card. 8B model they've made possible to run on smartphones.
Thanks for the demo. Now i understand how the llm work, especially the part where it consume power and how it consume the memory. With this info, i can manage the usage properly.
@@AZisk You are confusing it with the older RTX A6000 of the previous generation. I got the Ada one and it was nearly 8k€ on a good day.... so my car has to somehow surive for some years more now. :-|
You can see additional stats on model performance like tokens per second by using the --verbose flag with Ollama run. So Ollama run llama3.1 --verbose. Love the videos!
From a computer engineering background I’m 200% sure that your spikes comes from the bottlenecking of the GPU, basically it only gets the load for some milliseconds, then it is waiting for the data transfer in the pipeline, and keep looping in that, you are only using 63Gbps/ 1008GBps transfer rate
@@MultiMojo As they say in the boat business, isn't that 63Gbps "a hole below the waterline?" If Oculink still is the limited factor, why have such a beefy GPU if you can't integrate it for full effect?
Yea pretty sure that's the case, it's waiting for the next inference, which is bottlenecked by the CPU passing the latest context (with the last tokens appended) across to the GPU.
I'm just guessing this is the case, and presumably this could be made a lot faster if it was able to feed the output back into the context for the next inference within the GPU memory. It's doable with CUDA or whatever but I'm not sure where in the AI stack it would be implemented. But the GPU needs to be told to write output into the location on the GPU where the context window is stored for next inference
The white video cards are usually purchased by people building a "snow blind" PC - white case, white video card, white power supply, white cables, etc. These white video cards can be difficult to source and during periods of short supply they command a premium price with no other benefit than matching the color of the build. Larger LLMs yield very poor performance when spilling over from the maximum RAM of the nVidia RTX 4090 into the 128 Gb RAM in my tower PC. I get much better performance running up to 70 billion parameter LLMs on my MacBook Pro M3 Max. This is why I will be purchasing a Mac Studio M4 Ultra with maximum RAM installed when it is available.
My best guess about the gpu spikes: the whole LLM does not fit into the vram. And this means the gpu has to load new parts into vram. 13B models run fine on GPU but beyond that it’s CPU+GPU
Thx for the content. But as you pointed out, as long as consumers CUDA video card will be limited to 24 go, speed don't matter if you are that limited in model size.
If you want to run larger model's on that card look for a Mixture of Experts model, otherwise stick with models smaller than 10-12gb in size, especially if you choose one that has a large context length. I recently sold my 4090 to help finance a second A6000, I can get Llama 70 q8 models to run with a 98k context length but only just barely. That eats up about 56gb of vRAM the rest goes to the context window weights and all sorts of other stuff.
Of course it just work.. oculink is just pcie over a cable. That's why it's not hot swappable. So it work just as easily than plugging a gpu in a regular pc, with the bandwidth limitation.
Actually LLM inference doesn't need too much power. Just limit GPU max power with nvidia-smi or afterburner to ~250w per GPU and be happy. It's has very very low impact on tokens / sec.
Ollama on linux is even more performant. If the model is too large to fit on the vram it will normally "overflow" to the system memory but still use the gpu, normally you would get arround 30% gpu utilization depending on the "ratio" of vram usage vs system memory. I like this sort of videos please go deeper into this. This is out of experience and I did not search in this in the documentation as it just worked like I wanted it too.
11:00 Ollama has this feature (?) that makes it so that when you exceed a certain percentage the GPU vRAM, it meets the rest of its requirements from the system memory and CPU. That is why it is significantly slower. But it makes sure that you get an output unlike others that net you an OutOfMemoryError.
Wow Alex, that's surprising! Even the RTX 4090 seems to struggle, but as someone suggested in the comments, try updating your Nvidia drivers to see if it helps. I ran the same model on an AMD graphics card, and most of the time, it defaults to the CPU, with 0% GPU utilization. Since AMD lacks CUDA cores, I assumed that's why it ignores the GPU. Seeing this happen with your Nvidia card makes me wonder if we can force GPU usage. However, running models locally on our PCs doesn’t seem practical right now, as online models often deliver better results. Local setups might still be useful for generating small code snippets, though.
Yepp, that is why I saved my money and only got a 3060 12GB GPU. I still get about half of the speed of the top cards and most models are 8B. Next step is usually too much for 24GB anyways. Better to save money for now and buy something in a few years when VRAM probably is a lot cheaper or more specialised cards gets released.
"Next step is usually too much for 24GB" Sorry but no, you CAN put those 24GB to good use, you just have to use quantized models. You can squeeze every bit of performance from a 3090 or 4090 by finding models that are around 20 GB, leaving some headroom for the rest of the OS/UI and your context window.
@@reezlaw With that logic, I can use a quantized model to fit in 12GB too. 70B models quantized down to under 24GB will simply not perform well, so it's useless in my opinion. The prices for such cards are simply insane, unless you are lucky with a used one.
Thunderbolt 5, announced by Intel, brings significant improvements over Thunderbolt 4. It supports data transfer speeds of up to 80 Gbps, which can double to 120 Gbps in certain configurations (using a feature called “Bandwidth Boost” for high-bandwidth applications like displays). Key improvements in Thunderbolt 5 include: • Increased Bandwidth: Standard 80 Gbps, with the ability to dynamically boost up to 120 Gbps. • Display Support: Enhanced support for multiple high-resolution displays, including up to 3 x 4K displays or 2 x 8K displays. • Expanded PCIe Bandwidth: 3x the PCIe data bandwidth of Thunderbolt 4, enabling faster external storage and support for high-performance peripherals like GPUs. • Backward Compatibility: It remains backward compatible with Thunderbolt 4, Thunderbolt 3, USB4, and USB3. Thunderbolt 5 is expected to appear in devices starting in 2024.
@@f.iph7291 before you open your mouth please fist research what you are talking about, the only thing in the 4090 that runs close to that band width is the memory at 1008 GB/s. It has nothing to do with thunderbolt 5.
Come on Alex, the fact that you bought a 4090 and don't have a home built PC is crazy lol. Bring that in as your next project Mr. Laptop / Mini PC guy 😂
For a moment near the beginning of the video I was thinking you found a way to run a GPU on a Mac. I do have one quick question, if you are running a Linux box, can you use more than one GPU to increase the amount of RAM?
I have a laptop with TB4 and a watercooled egpu with a 3090 in it. It works perfectly as i always offload the llm to my vram anyway. With TB5 starting to show Oculink will need an oculink v2 to compete :)
I'm not sure why you chose a mini-computer and occulink, when you could have used an itx mb with full 16 lane PCIe5 capabilities? It's not smaller, or more convenient or efficient just doesn't make a lot of sense.
The issue that you see with over 24gb is not because it’s running on the CPU. It’s because ollama uses your RAM as a buffer for the vram. Only your ram is at best 55GBps while Vram in that 4090 is probably 650GBps. Add to that your using the oculink symmetrically- i’m assuming you have around 20GBps each way? (Dunno the oculink standard) Also note you are changing the latency by magnitudes. From ns to just under miliseconds (due to distance, several standards translation etc) and in a case of a huge matrix made of very small chunks of dara, that the algorithm needs constant access to it’s entirety.. So your left with a processor moving around lots of data but can’t keep feeding the parallel units of the g card.
Amazing vid and helpful to understand how to set up our private computing. The 4090 is limited by VRAM, as you demonstrated. Why not attempt this with an A6000 (48MB VRAM) model? The A6000 is optimized for AI performance, whereas the 4090 is optimized for gaming and 3D rendering. Thoughts?
sure there are better gpus for AI, but i would say they are a bit out of the budget of most consumers. even the 4090 is at the top end of what the consumer market can bear.
Alex - are you sure Ollama is running on the CPU? When I train Pytorch models, and accidentally exceed the GPU dedicated memory, the system starts to use the "virtual video memory" (or whatever Windows calls it). I get crazy high CPU usage, as I assume that the CPU is managing the data transfer down the busses from the GPU to system RAM. It is significantly slower than keeping it in GPU memory alone, but it faster than running on the CPU.. but the computation is still on the GPU I'd love to see a test when you disconnect the GPU as a control test!
"I was expecting a lot more noise from the 4090 to be honest. It's not that loud." Maybe that's because there's literally 0% load on the GPU? Who knows.
One of the things I love about hardware is there is zero need for instructions "Does this fit in there? It does. Well that's where it's supposed to go!". Brilliant. I laughed out loud when the UPS kicked in.
llama.cpp and everything based on it can offload layer of the model to system memory. Meaning you can run larger model at a huge performance penalty. Strong rec for LMStudio!!!
In the 90s we quickly went from PCs with 32MB RAM to 1GB...with AI we really need a 2nd coming of that boom lol. Image having affordable PCs with 1TB RAM, GPUs with 512GB, one can only dream
at 9:56, the Cudaz Device to Host is fluctuating, its relative to the spikes at 10:07 means gpu is sending something large data to the system causing cuda-z showing slower available bandwidth,
I wonder if the bandwidth limitations of oculink are just minor since the llm is first loaded into memory instead of a constant data stream like games require? Also you should look at aoostar as they have a egpu dock with power and both oculink and usb4.
I prefer another mini PC also from Minis Forum, the GTi4 Mini PC with EX Docking, which includes a 600W power supply. The mini PC can work independently or be plugged into the EX Docking to use a 4090 graphics card. It looks much cleaner since there are no extra cables.
It would be interesting to see how this compares to full size PC with a 4090. I am starting to build a system around a 4090 tomorrow. I went the more traditional route with a full size case, i9-13900, Asus Tuff Gaming MB, Corsair 1200 PS, 64GB, etc. Something smaller might be nice so I am watching closely.



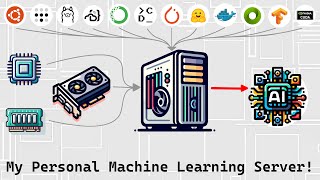






If you are running a GGUF model, ollama will split the process, putting as many layers as it can on GPU and the rest on CPU. IT will run slower, but faster than CPU only.
👍
@@paulhorn24 yeah I think a 4090 paradoxically is not as good choice as let's say gpu with no graphical capabilities but way more vram right?
Mini PCs have revolutionized the boring PC market. The power they are able to squeeze inside these small boxes gives me hope for the future of computing.
While I agree that they are cool, they kind of become pointless once you add one of these giant eGPUs. You could build a mini itx pc instead and avoid the occulink restrictions while also gaining the increased upgradability of a full desktop.
@@kroeken but you cant over clock your cpu
@@rochester3 huh? Yes you can. A proper ITX or mATX build is better in every way to these mini PCs with external GPUs.
Mini PCs are (for the most part) just laptop bowels transplanted in a little box.
They have use cases, for sure (hospitals, HTPCs, schools, small clients, emulation boxes, offices) but as soon as you ramp up the performances the prices and drawbacks (mainly thermals) go up quickly too, at the point where it's better to stick to a custom build solution unless you REALLY need the small form factor.
I admit that the mainstream pc market of today is VERY boring though, it peaked just around pre-covid and stayed there (I'm still using my ryzen 3600 + 6700 xt and I don't feel the need to upgrade to PCIx 5, while I bleeded money into my home server instead).
@@TheRaretunes true. But i hope the tech gets better and better for them. I find pc cases to be really ugly. Didn’t mind them back in the day but those aren’t best for airflow. Talking about airflow, just how much air do you need. I like small itx cases a lot more and surprisingly, they show that you don’t really need that much space for airflow and good temps. “Building computers” is also an overhyped genre. It’s really not all that it’s cracked up to be.
Serious question: why not just use the power directly if you're UPS isn't big enough? This isn't a mission critical server with important information, it doesn't need 24/7 operation during a power outage.
Some points here Alex:
1. The power cable that's split into three power plugs is a "dongle" that converts the 12V HPWR plug that's too recent for most power supplies out there, so they supply a splitter that is powered by 3 or 4 of the 8 pin PCI-E connectors.
2. The drivers for your GPU are provided by Nvidia themselves (just Google game ready drivers for RTX 4090), as the AIB drivers (Gigabyte's) are outdated.
3. All modern GPUs (from 2010 onwards) are all set to have zero fan revs at sub 60° C.
point 3 is not right.
@@R1L1. You're talking about exceptions to the rule, I only recall the Vega VII that had it's fans running all the time because it ran hot as the sun. Apart from that point 3 is the rule.
@@blackhorseteck8381 that doesn't change the fact that you are wrong, you could have just said most modern GPUs not all GPUs . Even then my rx6500xt always keeps the fans on, same with my 3060, didn't change anything after buying so yeah... Idk.
@@R1L1. my 970 also has always on fans
@@R1L1. are you using 2 monitors?
Haven't seen anyone do a video using multiple video cards in parallel to run a large model. So that is my humble request. Love the content.
👍
Chinese modders transplanted a chip from RTX 4090D to a custom board or a 3090 board and soldered 48 GB of memory. Real beast for AI rig. However, I'm not sure about the warranty for such Frankenstein card.
It's honestly sad at this point neither nvidia, Intel or amd have come out with a $700 card that just has 48gb vram and a $900 model with 128GB. The memory is cheap as nvidia just wants to squeeze you to spend $2000 on 4090.
With Ai now I think at least just 1x consumer model would be good from someone. I mean, you'd sell at least 2m units.
@@Larimussas far as I know nvidia has monopoly over AI due to their CUDA technology.
Until amd or intel isn't capable of competing with nvidia in this space, there wouldn't be any card with such memory.
@cena777248 yeh they do for now. Intel has already created some inference with their tech I beleive. And since CPU models exist I'm sure if amd made a cheap 48gb vram card the internet will figure out how to convert models or whatever it is. I'm pretty sure you can run some models with amd too? Just much less support where nvidia just runs everything right now and most optimally I think.
@@Larimuss Agreed. Everyone wants more vram, not more speed. But monopolists do monopoly stuff.
@@Larimuss it’s not good business for the average consumer to have access to good, fast, general-purpose local AI. We’d pay, what, maybe $600 more for that at an enthusiast level, less for the average consumer. But as long as AI remains the domain of big cloud companies and startups backed by VCs with deep pockets, people will keep flocking to them for this seemingly exclusive godlike power, and they will keep paying enterprise money to Nvidia.
small advice regarding ollama:
use verbose
example: ollama run llama3.1:8b --verbose
technically these commands, including what you ran, keeps the model loaded. You have to manually unload it, or you can tell the model to unload after you go /bye:
ollama run llama3.1:8b --verbose --keepalive 10s
the verbose will tell you the tokens per second generated.
the keepalive 10s will drop the model from memory after 10s
@@serikazero128 or if you already "inside" Ollama type /set verbose
👍
@@Lemure_Noah👍
The UPS going off was hilarious! 😂
I thought it was mine for a sec 😅
I experienced the same VRAM problems. I have a i9-32 thread and 128GB system RAM and runs the large models in slow motion but works. Small models run fast enough to use on the i9, but if it fits the gpu 16GB its really fast and enough to use as a service for a few clients. I'm using 4090 mobile=4080 desktop. Large models, these days, seems the Mac unified ram is the way to go for running large models but slower, but at least it runs and the wait is not too long.
I'm not convinced about the Mac's unified RAM. What all these Mac youtubers don't show you is the impact of larger prompts. While you may be fine with 5tokens/s, it's gonna suck if you have to wait a minute before it even starts to generate something.
This was a crazy video!! One of your best!!!
Glad you liked it!!
i love this man, never bored watching
I think you meant 40Gigabits/s for Thunderbolt 4 - instead of gigabytes.
ollama is smart enough to use two gpus simultaneously, so for that 40GB LLM you really have to use two gpus with 24GB vram each,
once you get over gpu vram capacity, things go into ram and though cpu which is terribly slow - at such point Apple Silicon Macs have advantage of utilizing shared ram, so something like 64GB Mac Studio "outperforms" and PC with lack of gpu vram
I've got a 1080 ti from 2017, and a PC I built in 2016 overclocked to almost 5Ghz, 6 cores 12 threads, with 64 GB Ram
I am currently running Llama 3.2 7B models lightning fast with my PC
running "ollama ps" will show you how much of the model is loaded on system ram vs GPU ram. You want 2x4090s for enough VRAM to run a 70b at a good speed.
2 used 3090s would do a more than decent job for a fraction of the price
@@reezlaw but it wont be a mini PC anymore
@@soumyajitganguly2593 indeed
@@soumyajitganguly2593 How much of a minipc is it with a 4090 and that psu hanging off of it? adding another card won't change shit.
that ups sound in the perfect moment 🤣.doing a nice job. keep it up
I have a 3090 with 24GB and yes you can run 13b. Nice setup
Also ISTA-DASlab (on huggingface) managed to squeeze original Llama 70B 140Gb model into 22Gb remaining 90+% quality ratio, so it can run on one 3090 card. 8B model they've made possible to run on smartphones.
this is so cool, thanks for showing us
Thanks for watching!
Thanks for the demo. Now i understand how the llm work, especially the part where it consume power and how it consume the memory. With this info, i can manage the usage properly.
I can’t understand why I find unboxing all this stuff was so interesting.
Me too, I’m addicted to these videos 😅
Well there is always the RTX 6000 Ada that is essentially a 4090 with 48GB VRAM but it costs around 10.000 USD I believe 😅
only $5000 😝
@@AZisk The Ada is $7200 at the cheapest. Where are you finding it for $5k? Or are you mixing it up with the previous gen RTX A6000?
@@samizdat_eth the previous gen A6000 is not that bad.. it's a 3090 with 48GB and you can get it for ~4k.
@@AZisk You are confusing it with the older RTX A6000 of the previous generation. I got the Ada one and it was nearly 8k€ on a good day.... so my car has to somehow surive for some years more now. :-|
Loving the LLM testing videos! Now I need a 4090 😁
"the reason it fits is because that's where it belongs"
amazing
Love your videos
Thanks
You can see additional stats on model performance like tokens per second by using the --verbose flag with Ollama run.
So Ollama run llama3.1 --verbose.
Love the videos!
This is a great way to benchmark new local LLMs. Just use a common prompt and compare.
Can you list all the ollama commands/flags Thanks
From a computer engineering background I’m 200% sure that your spikes comes from the bottlenecking of the GPU, basically it only gets the load for some milliseconds, then it is waiting for the data transfer in the pipeline, and keep looping in that, you are only using 63Gbps/ 1008GBps transfer rate
Oculink is limited to 63Gbps transfer rate
@@MultiMojo As they say in the boat business, isn't that 63Gbps "a hole below the waterline?" If Oculink still is the limited factor, why have such a beefy GPU if you can't integrate it for full effect?
Yea pretty sure that's the case, it's waiting for the next inference, which is bottlenecked by the CPU passing the latest context (with the last tokens appended) across to the GPU.
I'm just guessing this is the case, and presumably this could be made a lot faster if it was able to feed the output back into the context for the next inference within the GPU memory. It's doable with CUDA or whatever but I'm not sure where in the AI stack it would be implemented. But the GPU needs to be told to write output into the location on the GPU where the context window is stored for next inference
Definitely need to build something! Awesome video 😍
Yo your surge protector gonna explode. Haha.
The GPU spike is normal. It's likely just the model going back and forth.
Beeeeeeep!!!
The white video cards are usually purchased by people building a "snow blind" PC - white case, white video card, white power supply, white cables, etc. These white video cards can be difficult to source and during periods of short supply they command a premium price with no other benefit than matching the color of the build.
Larger LLMs yield very poor performance when spilling over from the maximum RAM of the nVidia RTX 4090 into the 128 Gb RAM in my tower PC. I get much better performance running up to 70 billion parameter LLMs on my MacBook Pro M3 Max. This is why I will be purchasing a Mac Studio M4 Ultra with maximum RAM installed when it is available.
My best guess about the gpu spikes: the whole LLM does not fit into the vram. And this means the gpu has to load new parts into vram. 13B models run fine on GPU but beyond that it’s CPU+GPU
Hi, nice test. Did It works also with a card like A6000 or h100?
Thx for the content.
But as you pointed out, as long as consumers CUDA video card will be limited to 24 go, speed don't matter if you are that limited in model size.
seasonic is definitely an amazing power supply. ive used them for all of my builds
What keyboard are you using😅?
this one: www.keychron.com/products/keychron-q1-max-qmk-via-wireless-custom-mechanical-keyboard?ref=azisk
Thanks for replying btw i just saw gear links in description @@AZisk
If you want to run larger model's on that card look for a Mixture of Experts model, otherwise stick with models smaller than 10-12gb in size, especially if you choose one that has a large context length. I recently sold my 4090 to help finance a second A6000, I can get Llama 70 q8 models to run with a 98k context length but only just barely. That eats up about 56gb of vRAM the rest goes to the context window weights and all sorts of other stuff.
Of course it just work.. oculink is just pcie over a cable. That's why it's not hot swappable. So it work just as easily than plugging a gpu in a regular pc, with the bandwidth limitation.
Is it possible to chain the external dock for multiple gpu?
unfortunately no
That PSU will work great to go in an entire desktop with the one 4090. Not really enough for 2x 4090s, though. That really needs a 1600W psu.
Actually LLM inference doesn't need too much power. Just limit GPU max power with nvidia-smi or afterburner to ~250w per GPU and be happy.
It's has very very low impact on tokens / sec.
LM Studio can split the model between CPU and GPU. You can tweak the split between them in the UI. Try that.
Ollama does this automatically as well. If you look at the task manager while the 70b model is running, the vram is filled up.
11:15 It automatically offloads some layers of the llm to the system RAM so it uses both gpu and cpu
Check ollama logs, there you will see a "xx/yy layers ofloaded to GPU".
Which monitor are you using?
Great video! But, didn't you do something similar before and your macs destroyed NVIDIA?
I did it with the rtx4090 in a laptop
Ollama on linux is even more performant. If the model is too large to fit on the vram it will normally "overflow" to the system memory but still use the gpu, normally you would get arround 30% gpu utilization depending on the "ratio" of vram usage vs system memory. I like this sort of videos please go deeper into this. This is out of experience and I did not search in this in the documentation as it just worked like I wanted it too.
WOW. How much did this cost? I’m sensing an Amex Black Card in the vicinity.
🤣 the dock was only $99
Hey which keyboard is that ?
this one: www.keychron.com/products/keychron-q1-max-qmk-via-wireless-custom-mechanical-keyboard?ref=azisk
If you went with a 750W PS you have:
- plenty of power
- save $100
- NO alarm bells going off. 😂
i got greedy with power
11:00 Ollama has this feature (?) that makes it so that when you exceed a certain percentage the GPU vRAM, it meets the rest of its requirements from the system memory and CPU. That is why it is significantly slower. But it makes sure that you get an output unlike others that net you an OutOfMemoryError.
Isn’t it a llama.cpp port to go?
@@anuragshas Ollama is built based on llama.cpp, but everything about Ollama is automatically handled (in this case the CPU/GPU allocation).
That powersupply is completely overkill.
Wow Alex, that's surprising! Even the RTX 4090 seems to struggle, but as someone suggested in the comments, try updating your Nvidia drivers to see if it helps. I ran the same model on an AMD graphics card, and most of the time, it defaults to the CPU, with 0% GPU utilization. Since AMD lacks CUDA cores, I assumed that's why it ignores the GPU. Seeing this happen with your Nvidia card makes me wonder if we can force GPU usage.
However, running models locally on our PCs doesn’t seem practical right now, as online models often deliver better results. Local setups might still be useful for generating small code snippets, though.
Yepp, that is why I saved my money and only got a 3060 12GB GPU. I still get about half of the speed of the top cards and most models are 8B. Next step is usually too much for 24GB anyways. Better to save money for now and buy something in a few years when VRAM probably is a lot cheaper or more specialised cards gets released.
you can run very big 70B models on your card with 90% quality, like from ISTA-DASlab austrian EU research team on huggingface
"Next step is usually too much for 24GB" Sorry but no, you CAN put those 24GB to good use, you just have to use quantized models. You can squeeze every bit of performance from a 3090 or 4090 by finding models that are around 20 GB, leaving some headroom for the rest of the OS/UI and your context window.
@@reezlaw yes! like ISTA-DASlab on huggingface incredible work with models
@@reezlaw With that logic, I can use a quantized model to fit in 12GB too. 70B models quantized down to under 24GB will simply not perform well, so it's useless in my opinion. The prices for such cards are simply insane, unless you are lucky with a used one.
Thunderbolt 5, announced by Intel, brings significant improvements over Thunderbolt 4. It supports data transfer speeds of up to 80 Gbps, which can double to 120 Gbps in certain configurations (using a feature called “Bandwidth Boost” for high-bandwidth applications like displays). Key improvements in Thunderbolt 5 include:
• Increased Bandwidth: Standard 80 Gbps, with the ability to dynamically boost up to 120 Gbps.
• Display Support: Enhanced support for multiple high-resolution displays, including up to 3 x 4K displays or 2 x 8K displays.
• Expanded PCIe Bandwidth: 3x the PCIe data bandwidth of Thunderbolt 4, enabling faster external storage and support for high-performance peripherals like GPUs.
• Backward Compatibility: It remains backward compatible with Thunderbolt 4, Thunderbolt 3, USB4, and USB3.
Thunderbolt 5 is expected to appear in devices starting in 2024.
this is clearly AI and doesn't know wtf is TB5
Lmao. Even then the bandwidth is much lower than the 4090 which is arounf 1tb/s
@@johnpp21 „Clearly“, and thats why?
@@f.iph7291 Yeah, but faster than Oculink
@@f.iph7291 before you open your mouth please fist research what you are talking about, the only thing in the 4090 that runs close to that band width is the memory at 1008 GB/s. It has nothing to do with thunderbolt 5.
Power suppllies often hit peak efficiency around 40-60% loading so thats a justification for 1200w
Really cool, wondering if there are dual or Quad GPU solutions
really killing that poor ups
Can you explain the downsides of quantizing models?
What are the disadvantages of running a 70B model on a 4090 with increased quantization?
Quantizing lowers the actual resolution of the model, it is less precise, but can still create good results unless quantized to oblivion.
Come on Alex, the fact that you bought a 4090 and don't have a home built PC is crazy lol. Bring that in as your next project Mr. Laptop / Mini PC guy 😂
idk man, i just don’t want a big box standing around heating up the place.
@@AZisk don't worry the new 4090 will do that itself haha. Great video!
@@purian23My 4080 is a heater already lol
It is nice when the room is cold
NOWAY he installing nvidia drivers from GIGABYTE
You should have bought a AMD Radeon™ PRO W7900 Dual Slot, which has 48 GB of GDDR6.
ORAC. Coming into reality!!!😂
For a moment near the beginning of the video I was thinking you found a way to run a GPU on a Mac.
I do have one quick question, if you are running a Linux box, can you use more than one GPU to increase the amount of RAM?
Awesome video can’t watch it with volume up with your ups freaking due to it making my dogs bark they think it’s the fire alarms
I have a laptop with TB4 and a watercooled egpu with a 3090 in it. It works perfectly as i always offload the llm to my vram anyway. With TB5 starting to show Oculink will need an oculink v2 to compete :)
I'm not sure why you chose a mini-computer and occulink, when you could have used an itx mb with full 16 lane PCIe5 capabilities? It's not smaller, or more convenient or efficient just doesn't make a lot of sense.
Yes, it will run on whatever has enough memory to run into. 4090's are extremely good for Stable Diffusion, but not for big LLMs.
The issue that you see with over 24gb is not because it’s running on the CPU. It’s because ollama uses your RAM as a buffer for the vram. Only your ram is at best 55GBps while Vram in that 4090 is probably 650GBps. Add to that your using the oculink symmetrically- i’m assuming you have around 20GBps each way? (Dunno the oculink standard)
Also note you are changing the latency by magnitudes. From ns to just under miliseconds (due to distance, several standards translation etc) and in a case of a huge matrix made of very small chunks of dara, that the algorithm needs constant access to it’s entirety..
So your left with a processor moving around lots of data but can’t keep feeding the parallel units of the g card.
Amazing vid and helpful to understand how to set up our private computing. The 4090 is limited by VRAM, as you demonstrated. Why not attempt this with an A6000 (48MB VRAM) model? The A6000 is optimized for AI performance, whereas the 4090 is optimized for gaming and 3D rendering. Thoughts?
sure there are better gpus for AI, but i would say they are a bit out of the budget of most consumers. even the 4090 is at the top end of what the consumer market can bear.
Alex - are you sure Ollama is running on the CPU?
When I train Pytorch models, and accidentally exceed the GPU dedicated memory, the system starts to use the "virtual video memory" (or whatever Windows calls it).
I get crazy high CPU usage, as I assume that the CPU is managing the data transfer down the busses from the GPU to system RAM.
It is significantly slower than keeping it in GPU memory alone, but it faster than running on the CPU.. but the computation is still on the GPU
I'd love to see a test when you disconnect the GPU as a control test!
why doesn't it run on the NPU?
Also why did you ever use laptops for serious computing??
any plans to test Beelink GTi14?
no but i got a beelink ser9 that looks pretty amazing
@@AZisk AFAIK, ser9 doesn't have pcie slot and gti14 does (4.0, x8.) would be nice to see it's performance on llm-specific tasks vs oculink
@@borisitkis3724yes, that’s right. the direct pcie connection is nice
"I was expecting a lot more noise from the 4090 to be honest. It's not that loud." Maybe that's because there's literally 0% load on the GPU? Who knows.
literally?
@@AZisk And figuratively.
Llama 3.2 3b is fantastic for text summarisation.
My Kizer is ALSO my faverit knife!!
Just saw the news with thunderbolt 5 able to transfer up to 120 Gbps 😮
Alex по красоте! Теперь прикуплю ✌️
Wow, cool video, Thank You 👍
One of the things I love about hardware is there is zero need for instructions "Does this fit in there? It does. Well that's where it's supposed to go!". Brilliant.
I laughed out loud when the UPS kicked in.
My Mac heated up by just watching this in 4k lolz
llama.cpp and everything based on it can offload layer of the model to system memory. Meaning you can run larger model at a huge performance penalty. Strong rec for LMStudio!!!
Why do you need ups for dev machine?
i have a bunch of stuff on my desk that’s not just laptops
In the 90s we quickly went from PCs with 32MB RAM to 1GB...with AI we really need a 2nd coming of that boom lol. Image having affordable PCs with 1TB RAM, GPUs with 512GB, one can only dream
I use a 4070ti, a 1080ti, a 1060 6g, and a 5700xt.
Works fine. if i pay that much for anything its going to be a new threadripper first.
USB4 2.0 80Gbps transfer speed should be pretty sweet when it lands.
thank god you god that ATX 3.0 to prevent the meltdown stuff on the 4090
@@zerogravityfallout4228 having an ATX 3.0 PSU doesn’t mean you’re protected against the meltdown unfortunately…
Didn’t realize that was a Kizer; we all have the same hobbies lmfao.
love that knife!
How would you feel about doing some fine-tuning? Maybe your fastest Mac Studio vs. This thing?
Wait why did you buy a white one?
OMG, that UPS is waaaaaaaay too small for that load. What was this guy thinking?
haha, this guy forgot he even had a ups
eGPUs are the future, best of all worlds.
Plug it into an oculink laptop though, like a GPD winmax, then you just need 1 machine.
Would love to see you do fine-tuning and inference tests on a 16" 2019 MacBook Pro with an eGPU.
woah that's sick
at 9:56, the Cudaz Device to Host is fluctuating, its relative to the spikes at 10:07
means gpu is sending something large data to the system causing cuda-z showing slower available bandwidth,
I wonder if the bandwidth limitations of oculink are just minor since the llm is first loaded into memory instead of a constant data stream like games require? Also you should look at aoostar as they have a egpu dock with power and both oculink and usb4.
I always get platinum or titanium PSUs cause I love overkill 😁
I prefer another mini PC also from Minis Forum, the GTi4 Mini PC with EX Docking, which includes a 600W power supply. The mini PC can work independently or be plugged into the EX Docking to use a 4090 graphics card. It looks much cleaner since there are no extra cables.
It would be interesting to see how this compares to full size PC with a 4090. I am starting to build a system around a 4090 tomorrow. I went the more traditional route with a full size case, i9-13900, Asus Tuff Gaming MB, Corsair 1200 PS, 64GB, etc. Something smaller might be nice so I am watching closely.
Need to know how M4 max compares to a proper 4090!
What connection is this?
10:00 a MiB =/= Megabit. 6100 MiB is just under 6GB or 48Gb or 5100 Mb.