Jon Barron - Understanding and Extending Neural Radiance Fields

ฝัง
- เผยแพร่เมื่อ 15 มิ.ย. 2024
- October 13, 2020. MIT-CSAIL
Abstract: Neural Radiance Fields (Mildenhall, Srinivasan, Tancik, et al., ECCV 2020) are an effective and simple technique for synthesizing photorealistic novel views of complex scenes by optimizing an underlying continuous volumetric radiance field, parameterized by a (non-convolutional) neural network. I will discuss and review NeRF and then introduce two works that closely relate to it: First, I will explain why NeRF (and other CPPN-like architectures that map from low-dimensional coordinates to intensities) depend critically on the use of a trigonometric "positional encoding", aided by insights provided by the neural tangent kernel literature. Second, I will show how NeRF can be extended to incorporate explicit reasoning about occluders and appearance variation, and can thereby enable photorealistic view synthesis and photometric manipulation using only unstructured image collections.
Bio: Jon Barron is a staff research scientist at Google, where he works on computer vision and machine learning. He received a PhD in Computer Science from the University of California, Berkeley in 2013, where he was advised by Jitendra Malik, and he received a Honours BSc in Computer Science from the University of Toronto in 2007. He received a National Science Foundation Graduate Research Fellowship in 2009, the C.V. Ramamoorthy Distinguished Research Award in 2013, the PAMI Young Researcher Award in 2020, and the ECCV Best Paper Honorable Mention in both 2016 and 2020.


![An Overview of Neural Radiance Fields [+Discussion]](http://i.ytimg.com/vi/pJiMc07iD2A/mqdefault.jpg)





What an incredible time we live in where one of the authors of the paper can explain it to the masses via a public forum like this! Incredible and mind expanding work guys! Thankyou so much :)
Very good explanation! Thanks for the talk.
Very nice work !! keep it up Drs.
popping the link to the videos in the description of the video would make a lot of sense. Enjoyed the nerf paper.
brilliant explaination!
Excellent explanation!!!
thanks for sharing this presentation
Awesome talk!
This is super helpful Thank you so much
very good explanation
I'm curious to know - when he said at the end that he only has 3 scenes ready to show... considering he mentioned only using 'normal' random public photos - why would this be?
Is this related to the computational time required to render the finished product, or for some other reason?
If the software works, then surely, give the required amount of time and computational resources, this technique could be used on a potentially infinite number of scenes, using high quality photos sourced online.
Is there a manual element to this process that I've missed here, or is the access to the rendering / processing time and resources the limitation?
Do you see any use for this with drone imagery and fields of crops? This wouldnt work for stitching images im guessing….
Great explanation indeed. I have one question: is it ray tracing or ray marching? From the talk, I seemed to find it to be ray marching, but the actual phrasing in the talk was ray tracing.
Marching
nice talk. keep going
Could you please tell how to make NeRF representation meshable?
Nerf outputs transparency but all the demo videos seem to only have opaque surfaces. Does it actually work with semi-transparent objects?
The colour output will be constant along a freely propagating ray. Seems you waste time recomputing the whole network when you really are just interested in the density
works that come after vanilla nerf deal with opaqueness better than the vanilla nerf does
@24:42 he says "you can see the relu activations in the image"- what is he pointing to in the image?
I think he might be referring to the flat areas (which would be the flat part of the relu)
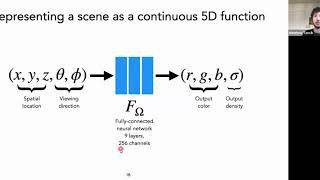
a practical question: how do people figure out the viewing angle and position for a scene that's been captured without that dome of cameras? the dome of cameras makes it easy to know the exact viewing angle and position, but what about just a dude with one camera walking around the scene taking photos of it from arbitrary positions? how do you get theta and phi in practice?
These papers usually use COLMAP to estimate the camera position for every captured image for real-world datasets. For the synthetic dataset (e.g. the yellow tractor), they just take the camera positions from Blender, or whatever software they use to render the object.
Glad to see Seth Rogan successful with this career change.
What's the difference between this and the 3d scans you get on an ipad pro? Apart from the fact this looks better. Just trying to get my head around it.
Hi, I'm just wondering how to know the ground truth RGB color for each (x,y,z) spatial location ?
Hi, You don't need that data. The neural net produces the RGB and alpha for each point along the ray (that was emitted from the pixel along the view direction), then when we have all of ray points RGBA, we can obtain the final pixel RGB color using ray-marching (so all of the parameters along the ray results in the RGB of the pixel). And now we can compare the actual pixel from the obtained pixel and learn from it to produce better parameters along the ray.
@@wishful9742 hi, may I ask how does exactly ray marching work? I am not sure how does MLP know that the scene is occluded at certain distance. Does it also learn sigma values from MLP? Or does the distance to the occluded point calculated from camera intrinsic and extrinsic properties? (I am new to nerf )
@@miras3780 Hello, for each point along the ray, MLP predicts the color and the opacity value. The final pixel is simply the weighted sum of colors (weighted by its opacity value). This is one way of raymarching and there are other algorithms of course. please watch 10:35 to 13:50
Can someone give a link to the Colab discussed around 12:00
The English subtitles are not in-sync with the video !! someone please help 😭
where is that notebook speaker is talking about
Please provide the link if you have it already.. Thanks in advance!
I like it😃
cc is a bit offset but overall is great!
whats the difference between this and photogrammetry?
Intuitively the main difference is that photogrammetry tries to build an actual 3D model based on given images, while NeRF model learns what the images from different view points will look like without actually building an explicit 3D model. Not sure about this point, but Nerfs are probably better given a certain number of images
45:32 - "were never going to get real time NeRF" and then came Instant-NeRF ... never say never
I hit the 1Kth like!
Noice 👍
One day these algorithms will be so good that you can simply feed all the photos on the internet (including Google Street View and Google images) and out comes a 3d digital twin of the planet. Fully populated by NPCs and driving cars. Essentially GTA for the entire planet....
With enough compute power there is no reason this will not work when combined with generative AI that fills in stuff that is missing by drawing experience from trillions of images/video/3d capture. Imagine giving a photo to a human 3d artist. He will be able to slowly make the scene in 3d from just the photo by using real world experience he has had.
Here is a rule of thumb with AI: Everything a human can do (even if it is super slow), AI will eventually be able to do much much faster. Things are going to speed up a lot from here. Cancer research, alzheimer cures, aging reversal etc... Exciting times.