Your videos are really such great source of knowledge, especially for me as a beginner. I'm trying to find the roadmap to become an NLP engineer, pls don't stop making videos.
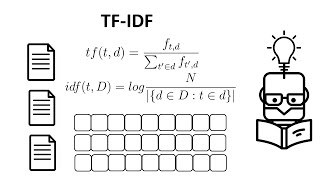
According to the explanation at 10:15 , log is used in IDF formula to dampen the effect of term occurring too often. But isn't the effect of frequency of term captured in the TF(Term Frequency) part of the formula(& not the IDF part). IDF, instead captures the value of each term based on WHETHER it occurs in most documents or not. So even if the term occurs 1 million times in one document and never in other documents, its IDF value would be same as if the term occurs only 1 time in one document and never in other documents - since we are checking for number of docs that have term present & not how many times the term occurs. Hence, for my example, both the scenarios will assign the same high IDF value to the term. Hence, I dont see the dampening of the importance of the term that has very high frequency caused due to higher term frequency. Please clarify. Thank you for the practical lessons that are free and easy to understand.
Mehn! You just take things in a gradual and relaxed manner. No rush. Thank you so much. I feel and know that I'm learning a lot here. By the way, I love your most powerful weapon. Lol.
Nice and simple explanation. Pls perform checking the model with new text data in the tutorial. Because I tried to check the model with new text data while practicing, it shows an error.
ok, actually I have made model deployment videos before in my data science projects. Search "codebasics data science projects" and in those project series you will find deployment videos. I will add separate videos for deployment in this series too when I post videos on end to end NLP projects.
I am facing a issue . I had a dataset which had 60398 test description rows and i cleaned the text did lamitization and stemming . After that i used TFID vectorization to convert text into matrix form.and the matrix shape it is showing (60398x104757). It is getting trained well using SVC . But when i am creating a predictive system and trying to predict same label column for a new data which has less number of rows (10000) after cleaning the new data and transforming into matrix form using TFID. When i am trying to predictict using. Model. Predict(X) i am facing a error " X has 10525 features, but SVC is expecting 104757 features as input". How to correct this error.




![เป็นไปได้ไหม - WanMai [Performance Video]](http://i.ytimg.com/vi/Eh5hItD4Mr0/mqdefault.jpg)




Check out our premium machine learning course with 2 Industry projects: codebasics.io/courses/machine-learning-for-data-science-beginners-to-advanced
Your videos are really such great source of knowledge, especially for me as a beginner. I'm trying to find the roadmap to become an NLP engineer, pls don't stop making videos.
According to the explanation at 10:15 , log is used in IDF formula to dampen the effect of term occurring too often. But isn't the effect of frequency of term captured in the TF(Term Frequency) part of the formula(& not the IDF part). IDF, instead captures the value of each term based on WHETHER it occurs in most documents or not. So even if the term occurs 1 million times in one document and never in other documents, its IDF value would be same as if the term occurs only 1 time in one document and never in other documents - since we are checking for number of docs that have term present & not how many times the term occurs. Hence, for my example, both the scenarios will assign the same high IDF value to the term. Hence, I dont see the dampening of the importance of the term that has very high frequency caused due to higher term frequency. Please clarify. Thank you for the practical lessons that are free and easy to understand.
A big thank you sir for explaining the concepts in simple ways.
Thank you so much for this in-depth explanation!
thannnnnnnnnnnnk you very much dear Dhaval, the way you're teaching is amazing..., really beneficial for us, hope you continue the series till end.
Mehn! You just take things in a gradual and relaxed manner. No rush.
Thank you so much. I feel and know that I'm learning a lot here.
By the way, I love your most powerful weapon. Lol.
such a great explanation . thank you Dhaval sir.
It could not better than this 🙏
Thanks a lot sir and please keep making more videos!!
Thank you so much for such a clear explanation.
Thank you very much. Great explanation!
AMAZING !! 😍😍
Thanks for your great effort !
We have to convert it into lowercase also in pre processing
Great tutorial. But the explanation for using log in IDF gives a wrong reason..please check..
Thank you. You are the best
Nice and simple explanation. Pls perform checking the model with new text data in the tutorial. Because I tried to check the model with new text data while practicing, it shows an error.
which error had occurred? if u can give the description of the error will try to figure out
Ecommerce and emotions(exercise) datasets are so different from what I see in git hub. pls help
Hi Dhaval, it would be of great, if you explain how to deploy this model in your upcoming videos.
ok, actually I have made model deployment videos before in my data science projects. Search "codebasics data science projects" and in those project series you will find deployment videos. I will add separate videos for deployment in this series too when I post videos on end to end NLP projects.
@@codebasics hope you ll use Streamlit for deployment :) .. always thanks for your precious tutorials ..🙏🙏
Sir big fan!
22:33 It's False. machine learning models are versatile tools that can process and learn from various data formats.
nice work, where is the TF score computed?
I am facing a issue . I had a dataset which had 60398 test description rows and i cleaned the text did lamitization and stemming . After that i used TFID vectorization to convert text into matrix form.and the matrix shape it is showing (60398x104757). It is getting trained well using SVC . But when i am creating a predictive system and trying to predict same label column for a new data which has less number of rows (10000) after cleaning the new data and transforming into matrix form using TFID. When i am trying to predictict using. Model. Predict(X) i am facing a error " X has 10525 features, but SVC is expecting 104757 features as input". How to correct this error.
Here why are we not using one hot encoding instead of labeling?It could be much better right
15:14 why "already" has 0, if its non existent in the corpus, how is it being added to the vocabulary?
0 is the index, not the count
how can i apply tfidf to only one colum means in your dataset, to df['text']?
you used different dataset from kaggel
Anyone willing to help me with ml project?