
- 15
- 212 058
Afaque Ahmad
Singapore
เข้าร่วมเมื่อ 10 เม.ย. 2023
Hey, I’m Afaque Ahmad, Solutions Architect at Databricks. I've cracked offers @ Apple, Uber & Atlassian. Previously, I was a Senior Data Engineer at QB/McKinsey & Urban Company (formerly UrbanClap). This channel was created out of my endeavor for teaching and simplifying complex data engineering concepts and, in doing so, perhaps offer a fresh perspective on how we approach them.
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
What Nobody Tells You About ATLASSIAN Interview Rounds!
Are you looking forward to cracking the Atlassian Interview? In this video, I share complete details, tips and tricks and guidance regarding my interview journey for the Senior Data Engineer (P5) role at Atlassian. Here’s what I cover:
💡 Round Breakdown:
1️⃣ Technical Screening: SQL, DSA, and Spark scenario-based questions
2️⃣ Coding Round: DSA & SQL problems
3️⃣ Data Architecture & Design: Building data models, designing end-to-end architectures, handling slowly changing dimensions (SCDs)
4️⃣ Product Sense: Metrics analysis, troubleshooting techniques
5️⃣ Management & Values: STAR format storytelling, resonating with Atlassian's values
Chapters
0:00 - Coming Up
1:17 - Interview Rounds Overview
1:53 - Round 1: Technical Screening
3:00 - Round 2: Coding Round (SQL & Python)
4:44 - Round 3: Data Architecture & Design Round
6:12 - Round 4: Product Sense Round
7:48 - Round 5: Management & Values Round
9:00 - Offer & Final Thoughts
My Social Media Handles:
TH-cam Channel: www.youtube.com/@afaqueahmad7117
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
My Playlists:
Interview Preparation: th-cam.com/play/PLWAuYt0wgRcKtqUhfVbtPjULMdYq5drs8.html
Spark Performance Tuning: th-cam.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
Github:
github.com/afaqueahmad7117
Spark Performance Tuning Codes: github.com/afaqueahmad7117/spark-experiments
#DataEngineering #InterviewExperience #Atlassian
💡 Round Breakdown:
1️⃣ Technical Screening: SQL, DSA, and Spark scenario-based questions
2️⃣ Coding Round: DSA & SQL problems
3️⃣ Data Architecture & Design: Building data models, designing end-to-end architectures, handling slowly changing dimensions (SCDs)
4️⃣ Product Sense: Metrics analysis, troubleshooting techniques
5️⃣ Management & Values: STAR format storytelling, resonating with Atlassian's values
Chapters
0:00 - Coming Up
1:17 - Interview Rounds Overview
1:53 - Round 1: Technical Screening
3:00 - Round 2: Coding Round (SQL & Python)
4:44 - Round 3: Data Architecture & Design Round
6:12 - Round 4: Product Sense Round
7:48 - Round 5: Management & Values Round
9:00 - Offer & Final Thoughts
My Social Media Handles:
TH-cam Channel: www.youtube.com/@afaqueahmad7117
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
My Playlists:
Interview Preparation: th-cam.com/play/PLWAuYt0wgRcKtqUhfVbtPjULMdYq5drs8.html
Spark Performance Tuning: th-cam.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
Github:
github.com/afaqueahmad7117
Spark Performance Tuning Codes: github.com/afaqueahmad7117/spark-experiments
#DataEngineering #InterviewExperience #Atlassian
มุมมอง: 6 008
วีดีโอ


I Cracked The UBER Interview Here's What You Need to Know
มุมมอง 2.2Kหลายเดือนก่อน
In this video, I’m sharing my detailed interview experience at Uber and the key areas you need to prepare for. I’ve broken down each interview round, tips, and strategies to help you succeed. From SQL and DSA to System Design, Data Modeling and the Hiring Manager round, this video has all the details to help your prepare for Uber & FAANG interviews. My Social Media Handles: TH-cam Channel: www....

How I Cracked Interviews At Apple, Uber, Atlassian & Databricks
มุมมอง 19Kหลายเดือนก่อน
Want to crack interviews at top tech companies like Uber, Apple, Atlassian, and Databricks? In this video, I break down the exact steps, resources, and strategies I used to succeed in these interviews. From SQL, Spark, Data Modeling, System Design to Product Sense, this guide covers everything you need to know for acing Data Engineering interviews. My Social Media Handles: TH-cam Channel: www.y...

Apache Spark Executor Tuning | Executor Cores & Memory
มุมมอง 18K9 หลายเดือนก่อน
Welcome back to our comprehensive series on Apache Spark Performance Tuning & Optimisation! In this guide, we dive deep into the art of executor tuning in Apache Spark to ensure your data engineering tasks run efficiently. 🔹 What is inside: Learn how to properly allocate CPU and memory resources to your Spark executors and the number of executors to create to achieve optimal performance. Whethe...
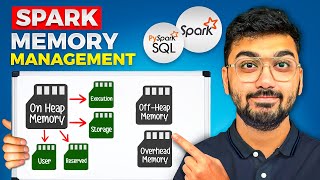
Apache Spark Memory Management
มุมมอง 17K9 หลายเดือนก่อน
Welcome back to our comprehensive series on Apache Spark Performance Tuning/Optimisation! In this video, we dive deep into the intricacies of Spark's internal memory allocation and how it divides memory resources for optimal performance. 🔹 What you'll learn: 1. On-Heap Memory: Learn about the parts of memory where Spark stores data for computation (shuffling, joins, sorting, aggregation) and ca...

Shuffle Partition Spark Optimization: 10x Faster!
มุมมอง 15Kปีที่แล้ว
Welcome to our comprehensive guide on understanding and optimising shuffle operations in Apache Spark! In this deep-dive video, we uncover the complexities of shuffle partitions and how shuffling works in Spark, providing you with the knowledge to enhance your big data processing tasks. Whether you're a beginner or an experienced Spark developer, this video is designed to elevate your skills an...

Bucketing - The One Spark Optimization You're Not Doing
มุมมอง 11Kปีที่แล้ว
Dive deep into the world of Apache Spark performance tuning in this comprehensive guide. We unpack the intricacies of Spark's bucketing feature, exploring its practical applications, benefits, and limitations. We discuss the following real-world scenarios where bucketing is most effective, enhancing your data processing tasks. 🔥 What's Inside: 1. Filter Join Aggregation Operations: A comparison...

Dynamic Partition Pruning: How It Works (And When It Doesn’t)
มุมมอง 6Kปีที่แล้ว
Dive deep into Dynamic Partition Pruning (DPP) in Apache Spark with this comprehensive tutorial. If you've already explored my previous video on partitioning, you're perfectly set up for this one. In this video, I explain the concept of static partition pruning and then transition into the more advanced and efficient technique of dynamic partition pruning. You'll learn through practical example...

How Partitioning Works In Apache Spark?
มุมมอง 9Kปีที่แล้ว
Welcome back to our comprehensive series on Apache Spark performance optimization techniques! In today's episode, we dive deep into the world of partitioning in Spark - a crucial concept for anyone looking to master Apache Spark for big data processing. 🔥 What's Inside: 1. Partitioning Basics in Spark: Understand the fundamental principles of partitioning in Apache Spark and why it's essential ...
Speed Up Your Spark Jobs Using Caching
มุมมอง 7Kปีที่แล้ว
Welcome to our easy-to-follow guide on Spark Performance Tuning, honing in on the essentials of Caching in Apache Spark. Ever been curious about Lazy Evaluation in Spark? I’'ve got it broken down for you. Dive into the world of Spark's Lineage Graph and understand its role in performance. The age-old debate, Spark Persist vs. Cache, is also tackled in this video to clear up any confusion. Learn...
How Salting Can Reduce Data Skew By 99%
มุมมอง 12Kปีที่แล้ว
Spark Performance Tuning Master the art of Spark Performance Tuning and Data Engineering in this comprehensive Apache Spark tutorial! Data skew is a common issue in big data processing, leading to performance bottlenecks by overloading some nodes while underutilizing others. This video dives deep into a practical example of data skew and demonstrates how to optimize Spark performance by using a...
Broadcast Joins & AQE (Adaptive Query Execution)
มุมมอง 9Kปีที่แล้ว
Spark Performance Tuning Welcome back to another engaging apache spark tutorial! In this apache spark performance optimization hands on tutorial, we dive deep into the techniques to fix data skew, focusing on Adaptive Query Execution (AQE) and broadcast join. AQE, a feature introduced in Spark 3.0, uses runtime statistics to select the most efficient query plan, optimizing shuffle partitions, j...
Why Data Skew Will Ruin Your Spark Performance
มุมมอง 8Kปีที่แล้ว
Spark Performance Tuning Welcome back to my channel. In this tutorial to dive into this comprehensive Apache Spark tutorial, where we will cover Apache Spark optimization techniques. Are you struggling with Data Skew and uneven partitioning while running Spark jobs? You're not alone! In this video, we dive deep into the world of Spark Performance Tuning and Data Engineering to tackle the common...
Master Reading Spark DAGs
มุมมอง 23Kปีที่แล้ว
Spark Performance Tuning In this tutorial, we dive deep into the core of Apache Spark performance tuning by exploring the Spark DAGs (Directed Acyclic Graph). We cover the Spark DAGs (Directed Acyclic Graph) for a range of operations from reading files, Spark narrow and wide transformations with examples, aggregation using groupBy count, groupBy count distinct. Understand the differences betwee...
Master Reading Spark Query Plans
มุมมอง 51Kปีที่แล้ว
Spark Performance Tuning Dive deep into Apache Spark Query Plans to better understand how Apache Spark operates under the hood. We'll cover how Spark creates logical and physical plans, as well as the role of the Catalyst Optimizer in utilizing optimization techniques such as filter (predicate) pushdown and projection pushdown. The video covers intermediate concepts of Apache Spark in-depth, de...
Great video... Will dynamic partiton pruning work if both the datasets are partitioned on a column and same column is the joining key?? I have seen that in such cases, spark does a full shuffle , so was curious to understand why is spark behaves like this when both tables are partitioned on the joining key
Hi Afaque, what if i found the size from Optimized plan :: catalyst_plan = df._jdf.queryExecution().optimizedPlan() df_size_in_bytes = catalyst_plan.stats().sizeInBytes() df_size_in_bytes_in_mb = df_size_in_bytes / (1024 * 1024) print(f"DataFrame size in MB: {df_size_in_bytes_in_mb}") -- will that be accurate replication?
These are gold standard advices... specially on the part on how to keep practicing for data modelling. It will be really great if you can also point towards some resources for other topics
Thanks for sharing.. 🎉
Thank you for the kind words, means a lot. I'll be making a detailed video on the resources soon :)
Hi Afaque, I have doubt over here When you mention memory which memory it holds cached data and also disk means where it holds data exactly? can you elaborate
Crisp and simple explanation
This is the most detailed video I found on salting. Afaque, are you on TopMate ? Would love to get your mentorship
Glad you found it helpful Praveen. Unfortunately I'm not on Topmate at the moment, however feel free to shoot questions on `dataengineer7117@gmail.com`
how much they were offering you for this role ?
If you're looking for a detailed answer - checkout Leetcode Compensation
Hi, was this role Data engineer 2 or senior data engineer. Kindly confirm.
Data Engineer II
Hi great video. I have a confusion about something the partition of the original parquet files was based on timestamp and not date, that is why you create a date out of that but after reading the parquet, but because the filter was based on a date (not a timestamp), how spark manage to achieve this dynamic parition pruning ?
Have you worked on building microservices and rest apis ? and do they ask them in interview ?
I've worked w/ REST APIs, but haven't worked on building microservices. If you've a project on your resume, they may ask
Thanks for the amazing video. Very well explained. Great Job !
Hi, apart from Spark, SQL, DSA, DM/DWH & System design, do they ask other stuffs as well like jenkins, github, scala, flink, kakfka etc?
I haven't been asked in almost all interviews I've given so far - they stick to foundations mostly; However, these may pop up in the System Design interview where you're drawing an architecture and you prefer to use Kafka for streaming or if you've a project / previous work experience that uses this technology
@@afaqueahmad7117 Thanks.
Hi Afaque, in this video you talked about the GC cycle, basically when on heap memory is full, then GC happens. From where can we get to know that GC cycle has happened and now its time to use some Off heap memory? I mean do we check DAG/Query Plan or somewhere else.
how much ctc apple was offering ?
Check Leetcode Compensation for a detailed answer
share some good books which you read for data engineeing
I've a detailed video on the resources and roadmap I followed coming up soon :)
how did you apply for this role, careers or referral ?
Referral
@@afaqueahmad7117 uber india or uber singapore ?
How much they were offering ? location india or singapore ? also, does apple singapore hire from india , please tell !
This was for Singapore. Apple does have roles in India but I'm not sure if they would hire from India for a role located in Singapore as there are quite a lot of visa complications
How did you apply for this role ? careers or referral ?
Careers
Thank you for this Series! Exactly what I needed, Amazing tutor!
Appreciate it, thank you, this means a lot :)
Thanks for the informative video. I have one major doubt: We are doing 25KB and 9KB of IO operation consecutively to use the bucketing and writing the data into tables. Spark is meant to use in memory processing. If we compare the duration of this bucketing IO operation with shuffling what will the cost and the execution time difference we'll get. Is it worth to use bucketing as it comprise IO operation.
Amazing video!
Thanks man :)
wow
Congratulations man🎉 Keep posting these kind of videos with more source of resources which would helpful to get into those positions. You guys are real light house in the sea of job searchers ❤
Appreciate the kind words, glad it's been of help :)
You explains these concepts very easily. Thanks you so much
Thanks man, glad it's been easy to understand :)
Thanks a lot for the video. Afaque. Just have a quick question: you weren't asked anything related to the cloud?
Thank you! No, I didn't have any questions relating to Cloud; If you think, the interview process has been nicely designed to test how you "think" vs what you just "know"
You are simply amazing for sharing these tutorials, thank you very much!
Thanks man, glad it's been helpful :)
There are some cases where we have huge data in a day or week or month. In that case we make partition and then bucket. So in that case there can be shuffling but still a better performance. Am I correct?
Good but would have been more appropriate to cover the join , how to parition data before join to make sure join works properly.
Congratulations Afaque.....doing a great job sharing all this precious information👍🙌
Glad it's been helpful - thank you :)
Hi @Afaque , Is atlassian still supporting WFH model or have shifted back to WFO i..e specifically for DE roles?
It's still supports WFH for DE roles :)
Is it possible to shift from QA backgroung to DE ?
If there's a will, there's a way. It's really not difficult to make a change to DE. You have a handful of things to get in place :)
I switched from QA to DE 5 years ago.
This has been really insightful, Thank you!!
Thank you @Rarchit, glad it's been helpful :)
can you please add sql questions somewhere in description?
Hey, as I mentioned I cannot share the exact questions due to NDA, but I believe I shared the type of questions you can expect and they should take you in the right direction because exact questions never help!
can you list sql questions?
Hey, as I mentioned I cannot share the exact questions due to NDA, but I believe I shared the type of questions you can expect and they should take you in the right direction because exact questions never help!
@@afaqueahmad7117 Yeah no worries
This playlist is awesome, watched all the videos on the trot. Keep producing great content bro!
Appreciate it, this means a lot, thank you! :)
What will happen to the bucketed tables which were created during the spark execution?, is it going to drop once after execution completes or do we need to drop it and how ?
really great videom thanks! can you also explain how bucketing works with several columns
Wonderful video, first of all. I have a question. I understand that 5 cores per executor is better for HDFS throughput. I don't understand how is this beneficial in any way. Because whether I have 100 cores per executor in just one node or 5 cores per executor across 20 different nodes, if I want to read 1 TB of data from HDFS, it will read 1 TB itself right? How does 5 cores per executor keep throughput in place?
Finally re-watched the whole playlist after a year for my spark revision :) I can surely say these are the best videos on these topics. Please keep making such in-depth videos on important concepts and other DE trending technologies as well based on your experience, that you feel are important for DEs. I really appreciate your work Afaque!
Hey Piyush, super glad to know that you watched the complete playlist 2 times - that gives me a lot of joy! Really appreciate the kind words. Many thanks and this means a lot :)
Awesome 👍
Great in depth information
Hi Afaque, can you please tell why GC increases in case of FAT Executors?
Fat executors means more resources, more resources means more cores and ram. If several cores are running concurrently, the rate at which they're creating and destroying objects is quick, which means the heap is getting filled up quickly and in order to keep it usable it needs to be cleaned quickly too - hence GC would increase. Plus, with fat executors, the heap space is large, it ends up doing a larger heap scan to clear up unwanted objects which in turn pauses the job for longer than usual for the cleaning activity to complete. So it's ideal to have a sweet spot for both cores and memory. Hope this clarifies :)
This is amazing content, so helpful. You gained a subscriber!
Appreciate it, thank you :)
I love your videos man, I'm watching these again after a year to revise the concepts. Please keep making such in-depth videos, these are really helpful, noone explains these concepts at this level like you. :)
Appreciate it, this means a lot. Thank you for the kind words Piyush :)
It is very descriptive and can you pls share the roadmap and proper materials and how much python and SQL required for cracking product based companies
and yes if snowflake , kafka, microservies and ware housing concepts required then how much required? , which leetcode sections for python and SQL and how much practice required
I've a ROADMAP video coming up where I discuss each aspect in details, stay tuned :)
When can we expect more videos on Spark ;)
I love to work
Inspiring and informative.
Appreciate it :)
please share some resources you follow for preparation
Will create a separate video specifically on the resources :)
But u recently joined DataBricks i think