TH-cam
US
FindingFive: An online, non-profit platform for behavioral research
1:26:18
Miika Aittala: Elucidating the Design Space of Diffusion-Based Generative Models
52:46
Learning to Generate Data by Estimating Gradients of the Data Distribution (Yang Song, Stanford)
1:03:15
🔴LIVE สด! PGC 2024 ศึกชิงแชมป์โลกพับจี Circuit 3 วันที่ 2
5:17:45
How to treat Acne💉
00:31
【พากย์ไทย】สาวใช้ในวังจะถูกประหารชีวิต แต่เธอมีฐานะที่ไม่ธรรมดา คือพระราชบุตรีแท้ๆ ของพระราชา!
1:31:16
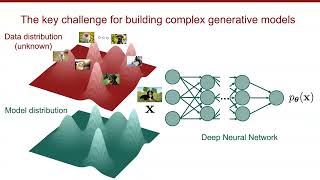
Diffusion and Score-Based Generative Models
MITCBMM
ติดตาม
58K
ดาวน์โหลด
โหลดลิงค์.....
มุมมอง 87 035
0
0
เพิ่มลงใน
เพลย์ลิสต์ของฉัน
ดูภายหลัง
แชร์
แชร์
ฝัง
ขนาดวิดีโอ:
1280 X 720
853 X 480
640 X 360
แสดงแผงควบคุมโปรแกรมเล่น
เล่นอัตโนมัติ
เล่นใหม่
เผยแพร่เมื่อ 24 ม.ค. 2025
ความคิดเห็น • 57
ต่อไป
เล่นอัตโนมัติ
1:26:18
FindingFive: An online, non-profit platform for behavioral research
MITCBMM
มุมมอง 2.5K
52:46
Miika Aittala: Elucidating the Design Space of Diffusion-Based Generative Models
Finnish Center for Artificial Intelligence FCAI
มุมมอง 15K
1:03:15
Learning to Generate Data by Estimating Gradients of the Data Distribution (Yang Song, Stanford)
Yingzhen Li
มุมมอง 20K
5:17:45
🔴LIVE สด! PGC 2024 ศึกชิงแชมป์โลกพับจี Circuit 3 วันที่ 2
PUBG: BATTLEGROUNDS THAILAND
มุมมอง 169K
00:31
How to treat Acne💉
ISSEI / いっせい
มุมมอง 101M
1:31:16
【พากย์ไทย】สาวใช้ในวังจะถูกประหารชีวิต แต่เธอมีฐานะที่ไม่ธรรมดา คือพระราชบุตรีแท้ๆ ของพระราชา!
Fresh Thailand Pro
มุมมอง 177K
12:08
#อึ้ง!เหลือจะเชื่อ!ไทยพลิกนรกดับสิงคโปร์คาบ้าน ทะลุเข้ารอบรองชนะเลิศ! คารวะอิชิอิโคตรการเปลี่ยนแปลง!
# จัน ฑาล
มุมมอง 194K
38:11
Diffusion Models From Scratch | Score-Based Generative Models Explained | Math Explained
Outlier
มุมมอง 24K
56:16
Flow Matching for Generative Modeling (Paper Explained)
Yannic Kilcher
มุมมอง 61K
51:39
David Duvenaud - Latent Stochastic Differential Equations: An Unexplored Model Class
JumpTrading ELLIS UCL CSML Seminar Series
มุมมอง 3.2K
1:00:40
Jeffrey Fessler - An Introduction to Score Based Generative Models
Michigan Institute for Data Science
มุมมอง 7K
3:46:15
Tutorial on Denoising Diffusion-based Generative Modeling: Foundations and Applications
Arash Vahdat
มุมมอง 142K
20:18
Why Does Diffusion Work Better than Auto-Regression?
Algorithmic Simplicity
มุมมอง 437K
16:25
How I Understand Flow Matching
Jia-Bin Huang
มุมมอง 22K
59:40
Flow Matching: Simplifying and Generalizing Diffusion Models | Yaron Lipman
VantAI
มุมมอง 17K
44:42
The Debate Over “Understanding” in AI’s Large Language Models
MITCBMM
มุมมอง 9K
5:25:16
ทัวร์สตรีมเมอร์ ROV ชิงเงินรางวัลรวม 25,000 บาท 8 ทีม : รอบ 8 ทีม
Chicken V
มุมมอง 215K
00:17
Mache leckere Lutscher mit diesem PRO-Gadget! 🚽🍭
Chill Thesoul Out German
มุมมอง 8M
00:29
ถ้าม้าโดนแกล้งที่โรงเรียน ม้าจะฟ้องครูว่าอะไร #แต้มเซน #การ์ตูน #tamzen #ตลก #shortvideo #การ์ตูน
TAMZEN
มุมมอง 19K
33:22
แมนยู Corner : คุยหลังเกม แมนฯซิตี้ 1-2 แมนฯยู ชัยชนะมาจากอโมริมกล้าตัด แรชฟอร์ด , การ์นาโช
Fluke Family
มุมมอง 274K
00:15
ตรวจหวยงวดวันที่ 16 ธันวาคม 2567 พร้อมรางวัล N3 รางวัลพิเศษ รางวัล 2 ตัว : Matichon Online
Matichon Online
มุมมอง 38K
00:55
ไม่มีใครรักหนูเลย #shorts #แม่สุน้องซูกัส
HeHaa TV
มุมมอง 2.6M
42:36
“โดนัท มนัสนันท์” ไหว้ขอสามีมีอีหนูเถอะ!! “หนุ่ม กรรชัย” พร้อมช่วยเหลือ! | 3 แซ่บ (Full) 15 ธ.ค. 67
Polyplus Entertainment
มุมมอง 280K
1:23:46
【หนังพากย์ไทย】ยอดฝีมือสังหารนักโทษ แต่นักโทษเป็นปรมาจารย์กังฟูที่ซ่อนอยู่ เขาจัดการทั้งหมดในทันที
Fresh Thailand
มุมมอง 468K