Would love to see a whole playlist on setting up a serverless data lake with local development. With data coming from DynamoDB, permissions managed with. Lake house, processed with Glue jobs and query the data from Athena
If you needed to reprocess data in your raw zone to your process zone how would you do that? Is there a video on reprocessing data in a serverless data lake?
It all depends on how your pipelines were designed. What would happen if you retrigger your data pipeline for the time period you are interested in as it stands now?
@@DataEngUncomplicated I'm asking more from a theoretical stance, I want to build out a robust pipeline that will allow me to reprocess data at a certain point in time for a Streaming pipeline. I can handle it from after the processed zone, but am not sure how to handle duplication in a Streaming pipeline if I wanted to reprocess data from the last X days.
Hi Kannan, so as a user of these aws services you don't have to worry about the underlying infrastructure for it to work. For example, you don't have to worry about turning off the server or security patches after your glue job finishes. They could be on servers like an ec2 instance but you don't see that machine or have access to it, it is managed by Amazon.
Serverless just means that you abstract the underlying servers. It doesn't mean that there are none, it means you (the organization) don't have to worry about them (patching, deploying, maintaining etc.). Point of serverless services is to allow the organization to utilize their resources on solving business problems, and not to worry about the underlying infrastructure (as much as one would if an on-premise solution is used).
Great Introduction, can you pls create a set full length videos or full 10 hours or less I mean a use case for insurance data to build a data lake video
How can i directly ingest data in glue from source, is it necessary to first store data in s3 and then Giving the path of s3 , is there any way that i can directly ingest data into glue
Hi Rob, You can directly ingest data with glue from the source. You just need to add the database connection to the source so you can read it. Check out my video to connect to an rds postgres database: th-cam.com/video/UUoQAe_NzaA/w-d-xo.html
I'm confused about how these RAW/STAGE/PROCESSED zones need to be partitioned? We are trying to build a lakehouse and partitioning is dependent on a use case so how can we use a common framework to partition the data for lakehouses? also, do you write glue crawlers for each of these zones? it's so confusing to actual implement it ...in theory its so fun.
Hi Navin. Partitioned is use case dependent! I would checkout my video on optimizing data lake where I discuss partitioning strategies in more detail. th-cam.com/video/9Mm5l-l9OPo/w-d-xo.html . if you want your data to appear in the aws glue catalog, you can use glue crawlers or use some functions from aws data wrangler to add these automatically when your job runs...glue crawlers can be slow and expensive for what they do some people may say.
a lakehouse architecture extends the data lake concept by incorporating features like ACID transactions, schema enforcement, and unified processing, thereby combining the benefits of data lakes and data warehouses. Lakehouse architectures allow for updates on your files, this would include storing your data in formats like delta, hudi or iceberg.



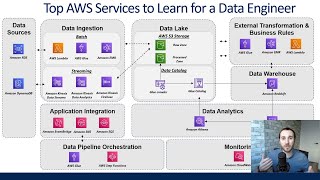






Great video! When's the next one coming out?
Tomorrow? Got a video on 3 ways to optimize your data lake! Also how to install pandas on aws lambda
Great video!
Please create more
Thanks Josh! Really appreciate the positive feedback 🙂
Would love to see a whole playlist on setting up a serverless data lake with local development. With data coming from DynamoDB, permissions managed with. Lake house, processed with Glue jobs and query the data from Athena
Hi Stephen, I really like this idea...this would make a great collection of related videos! Videos to come soon!
Very Good video. Great explanation.
Thank you!
can lakeformation be created from IaC? like cloudformation/terraform?
Yes lake formation has terraform resources!
If you needed to reprocess data in your raw zone to your process zone how would you do that? Is there a video on reprocessing data in a serverless data lake?
It all depends on how your pipelines were designed. What would happen if you retrigger your data pipeline for the time period you are interested in as it stands now?
@@DataEngUncomplicated I'm asking more from a theoretical stance, I want to build out a robust pipeline that will allow me to reprocess data at a certain point in time for a Streaming pipeline. I can handle it from after the processed zone, but am not sure how to handle duplication in a Streaming pipeline if I wanted to reprocess data from the last X days.
Thanks for the video. I have 2 (newbie) questions:
1. How is this a serverless?
2. Where do all these AWS services reside? Inside an EC2 instance?
Hi Kannan, so as a user of these aws services you don't have to worry about the underlying infrastructure for it to work. For example, you don't have to worry about turning off the server or security patches after your glue job finishes.
They could be on servers like an ec2 instance but you don't see that machine or have access to it, it is managed by Amazon.
Serverless just means that you abstract the underlying servers. It doesn't mean that there are none, it means you (the organization) don't have to worry about them (patching, deploying, maintaining etc.).
Point of serverless services is to allow the organization to utilize their resources on solving business problems, and not to worry about the underlying infrastructure (as much as one would if an on-premise solution is used).
@@DataEngUncomplicatedthanks for the response. so is EC2 considered serverless then?
No, Amazon EC2 is not serverless. You have to manage that server yourself.
Are you saying directly ingest data into glue from source and then storing data in s3
Yes correct.
Great Introduction, can you pls create a set full length videos or full 10 hours or less I mean a use case for insurance data to build a data lake video
Thanks! I wish I had the time to make a 10 hour video 😞
How can i directly ingest data in glue from source, is it necessary to first store data in s3 and then Giving the path of s3 , is there any way that i can directly ingest data into glue
Hi Rob, You can directly ingest data with glue from the source. You just need to add the database connection to the source so you can read it. Check out my video to connect to an rds postgres database: th-cam.com/video/UUoQAe_NzaA/w-d-xo.html
I'm confused about how these RAW/STAGE/PROCESSED zones need to be partitioned? We are trying to build a lakehouse and partitioning is dependent on a use case so how can we use a common framework to partition the data for lakehouses? also, do you write glue crawlers for each of these zones? it's so confusing to actual implement it ...in theory its so fun.
Hi Navin. Partitioned is use case dependent! I would checkout my video on optimizing data lake where I discuss partitioning strategies in more detail. th-cam.com/video/9Mm5l-l9OPo/w-d-xo.html . if you want your data to appear in the aws glue catalog, you can use glue crawlers or use some functions from aws data wrangler to add these automatically when your job runs...glue crawlers can be slow and expensive for what they do some people may say.
what is data lakehouse? how its different from data lake?
a lakehouse architecture extends the data lake concept by incorporating features like ACID transactions, schema enforcement, and unified processing, thereby combining the benefits of data lakes and data warehouses. Lakehouse architectures allow for updates on your files, this would include storing your data in formats like delta, hudi or iceberg.