This explanation is excellent. It is crystal clear to explain why is the inverse relationship between variance and second derivative, and why is second derivation, and plus why it is negative! Bravo, Prof.Ben!
Studying for actuarial exams and the material just throws Fisher Information at you with no context. This will help me understand exactly what we are expected to do in the calculations. Thank you
This was my intuition when studying ML estimators in statistics, but never got a straight answer about it from my teachers. Happy to see others think of it through a geometric lens! Great video
This video makes me very clear about one thing, that I find it strange how hard it obviously is for professors to provide some clear intuition. Why must it be so hard to be pedagogical when you really know something, which I expect a professor does. This is a working day of headache over horrible handouts made understandable in 5 mins.
Really appreciate videos like this where the aim is to provide an intuitive explanation of the concepts as opposed to going into detail on the maths behind them. Thanks.
Hi Mr. Lambert, I just want to take a moment to thank you for taking the time to make these videos on TH-cam. They are very easy to understand and by watching your videos I have been able to understand my statistical theory and bayesian statistics courses more as an undergrad. Thanks a lot and I wish you all the best!
OK 3 months ago, I thought I understood this video. After I learned more statistic. Now I understand what is going on. I didn't quite understand the concept 3 months ago.
Thank you for this video. I have watched this video many times over the years. The simplicity, intuition, visuals, clarity, and ease, are nothing less than brilliant. It has always helped whenever things get fuzzy. Just a small request or a question if you may: Calling vertical axis "likelihood of the data" makes it a bit confusing! Instead, should it not be "likelihood of the parameter" that is L( theta; data). And this "likelihood of the parameter" then happens to be equivalent to f(data|theta)? So, y axis should not be called L(data|theta)?
you said we add the negative sign, because the second derivative is negative after a certain value, and the negative sign is added to correct for that negative. what about when the second derivative is positive? doesn't the negative sign make the second derivative negative then? of what use will that be?
Hi ben, thank you so much for your videos, i am studying quantitative ecology and do not have a strong mathematical background - your lessons really help! May I ask how the different values of theta are generated (along the x axis)? I assume the MLE expression stays constant and that the parameter estimates vary due to sample variation but in my case I only have one sample. I am a bit confused whether variance of the MLE is actually referring to variance in the parameter estimate due to sampling error. Secondly, in order to calculate the variance, must the 2nd derivative be evaluated for the value of theta which gives the MLE? I hope these questions make sense!
i dont know hat he is using but I sometimes use app.liveboard.online/ . It also allows you to chose different backgrounds for a board and different colors and to livestream your drawing from your tablet/smartphone to PC which i often use as it is better to draw by hand/pen then by mouse.




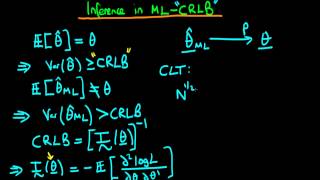





THIS MAKES SO MUCH SENSE!! Thank you so much for explaining this more clearly in a few minutes than my textbook could do in a few hours!
I think this small video worth few 2hrs lectures in a university.
lmao true
I just watched a 1 hour lecture about Cramer-Rao Lower Bound and you are totally right :P this was waaay more informative.
In 7m and 59s you explained it better and more clearly than many 2h university lectures combined.
This explanation is excellent. It is crystal clear to explain why is the inverse relationship between variance and second derivative, and why is second derivation, and plus why it is negative! Bravo, Prof.Ben!
Studying for actuarial exams and the material just throws Fisher Information at you with no context. This will help me understand exactly what we are expected to do in the calculations. Thank you
This was my intuition when studying ML estimators in statistics, but never got a straight answer about it from my teachers. Happy to see others think of it through a geometric lens! Great video
Like everyone else said, very well explained. I feel way less jittery about this whole entire concept. Thank you in 2019!
This video makes me very clear about one thing, that I find it strange how hard it obviously is for professors to provide some clear intuition. Why must it be so hard to be pedagogical when you really know something, which I expect a professor does. This is a working day of headache over horrible handouts made understandable in 5 mins.
Really appreciate videos like this where the aim is to provide an intuitive explanation of the concepts as opposed to going into detail on the maths behind them. Thanks.
Hi Mr. Lambert, I just want to take a moment to thank you for taking the time to make these videos on TH-cam. They are very easy to understand and by watching your videos I have been able to understand my statistical theory and bayesian statistics courses more as an undergrad. Thanks a lot and I wish you all the best!
Damn. You explained this so well. I never have any idea what my professor is talking about, but videos like this help SO MUCH. Thank you!
Beautifully explained my friend- intuition is almost always as important as the actual proof itself
This was a fantastic intuitive explanation - thank you!
this is the best video ive seen on this topic, very well done
The point of view in curvature is soooo great!
Wow! This clarifies a good week or two from last year's lectures. I wish I had seen these videos when I was taking the course last year.
This makes so much more sense now, thank you!
High curvature -> sharp -> concentrated -> low variance. Makes sense.
This helps so much. very simple explanation
wow finally get the idea about this relationship between covariance matrix and hessian
so in otherowords the covariance matrix is hessian of maximum likellihood?
Those tangents illustrate the convexity... Jensen!
Wow, that makes things so much clearer. Thank you.
OK 3 months ago, I thought I understood this video. After I learned more statistic. Now I understand what is going on. I didn't quite understand the concept 3 months ago.
Kudos man! most intuitive explanation ever!
Thank you so much. This explains so much.
Thank you for this video. I have watched this video many times over the years. The simplicity, intuition, visuals, clarity, and ease, are nothing less than brilliant. It has always helped whenever things get fuzzy.
Just a small request or a question if you may: Calling vertical axis "likelihood of the data" makes it a bit confusing!
Instead, should it not be "likelihood of the parameter" that is L( theta; data). And this "likelihood of the parameter" then happens to be equivalent to f(data|theta)? So, y axis should not be called L(data|theta)?
Awesome awesome awesome video....Thankyou so much!
Excellent video, congratulations!
thanks. Good explanation. I guess you saved me hours of searching.
Ben, you are amazing!
You just saved my semester (again) GGWP
Well explained man!!! Thanks a million 🙏
you said we add the negative sign, because the second derivative is negative after a certain value, and the negative sign is added to correct for that negative. what about when the second derivative is positive? doesn't the negative sign make the second derivative negative then? of what use will that be?
Great video, as always. Helped me out a lot!
Wonderful video. Thank you very much!
Thank u Ben, it was quite helpful
Isn't the variance of theta hat also dependent on n, the number of observations which constitute the likelihood function?
wonderful video, thank you!
Awesome video!!
Many thanks, much appreciated!
wonderful video
Thanks, very intuitive.
[Subscribed]
Excellent many thanks
Thank you very much!
Hi ben, thank you so much for your videos, i am studying quantitative ecology and do not have a strong mathematical background - your lessons really help! May I ask how the different values of theta are generated (along the x axis)? I assume the MLE expression stays constant and that the parameter estimates vary due to sample variation but in my case I only have one sample. I am a bit confused whether variance of the MLE is actually referring to variance in the parameter estimate due to sampling error. Secondly, in order to calculate the variance, must the 2nd derivative be evaluated for the value of theta which gives the MLE? I hope these questions make sense!
great intuitive :)
In wich playlist ı can find this topics in a ordered manner
Very good.
Hi Ben find your tutorials very easy to follow- thanks. What software are you using? Especially like the coloured pens on black background.
i dont know hat he is using but I sometimes use app.liveboard.online/ . It also allows you to chose different backgrounds for a board and different colors and to livestream your drawing from your tablet/smartphone to PC which i often use as it is better to draw by hand/pen then by mouse.
You can check his website for info.
You da best!
My student finance payment should be going to people like you, not these institutions.
شكرا و لكن و الله مفهمت 😂😂😂
نتمنى وضع ترجمة لاحقا
I want to know the meaning of penalized mle
Are you learning that for Machine Learning?
WOW!
Jon Plaza
ily
Kane Park
Lydia Stream
Thank you so much!