### How Self-Attention Works 1. **Input Representation**: - Consider an input sequence of words, each represented by a vector. For example, in a sentence "The cat sat on the mat", each word is converted into a vector through embedding. 2. **Query, Key, and Value Vectors**: - For each word in the sequence, self-attention computes three vectors: Query (Q), Key (K), and Value (V). - These vectors are derived by multiplying the input vector with three different weight matrices that are learned during training. 3. **Attention Scores**: - The attention score for a word is computed by taking the dot product of its query vector with the **key vectors of all words** in the sequence. This score indicates **the importance of other words to the current word**. - Mathematically, this can be represented as: $Attention Score(Q,K)=Q⋅KT$
4. **Softmax**: - The attention scores are normalized using a softmax function to get the attention weights, which sum to 1. This helps in converting the scores into probabilities. 5. **Weighted Sum**: - The final representation of each word is computed as a weighted sum of the value vectors, where the weights are the attention weights calculated in the previous step. - Mathematically: Output=$Softmax(Q⋅KT)⋅V$
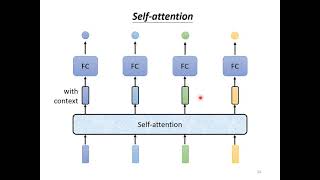
****4:00** Representing the process of acquiring Q, K, V as matrix operations** a1, a2, a3, a4 can be grouped as a matrix A q1, q2, q3, q4 can be grouped as a matrix Q and so on… W A = Q 14:35 The only parameters that require training are Wq, Wk, Wv. ****15:04** Multi-Head Self Attention** Number of heads is a hyperparam 2 Heads → 2 Queries, 2 Keys, 2 Values 3 Heads → 3 Queries, 3 Keys, 3 Values …… 19:00 But this means you have multiple bs, this requires additional transform to compute the output. 原本Head = 1, Value乘完Attention Score可直接輸出,Multi-head需要多一步處理 ****19:15** Positional Encoding** Self-Attention doesn’t have position info. Use positional encoding if you believe “position” is a required part of your data. ****26:00** Truncated Self-Attention** Speech is often very long. We can limit the range to a specific part of the speech, no need to consider the whole sequence ****28:00** Self-Attention for Image** ****29:30** Self-Attention VS CNN** CNN is self-attention with its range limited to the receptive field → CNN is simplified self-attention (CNN is more restricted) → Self-attention is CNN with a learnable receptive field. The kernel size is learned by the model, not set by the programmer. (Self-attention is more flexible) ****32:30** Flexible Models Need More Data** Flexible models need more data, otherwise you’ll encounter overfitting CNN is good enough when given a small amount of data, but eventually stops improving when fed more Self-attention can surpass CNN if given enough data ****35:10** Self-Attention VS RNN (Recurrent Neural Network)** ### RNN Key Characteristics 1. **Sequential Data Handling**: - RNNs are designed to handle sequential data by maintaining a hidden state that captures information from previous steps in the sequence. This allows the network to have a form of "memory" that can be used to inform its predictions. 2. **Recurrent Connections**: - Unlike feedforward neural networks, RNNs have connections that loop back on themselves. This feedback loop allows information to persist, making RNNs well-suited for tasks where the order of inputs matters. ****38:00** How RNN Works** Self-attention can replace RNN RNN must generate each vector one-by-one because the next vector requires the previous vector to compute. Self-attention can generate all vectors in parallel **那篇很有名的Transformer論文Attention is all you need說: “**Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states $ht$, as a function of the previous hidden state $ht−1$ and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.**”** 40:30 Self-Attention for Graph If two nodes are not connected, we don’t need to compute their attention score → GNN 坑很深









老師真的很謝謝您造福大家,讓大家即使沒考上台大依然可以上到如此優質的課程,我會努力學習的!
大陆学生能考台大吗?
@@bernardmontgomery3859 可以😅
我是在日本工作的机械工程师,看到您的讲座实在太有帮助了。非常容易理解,比光看教科书效果好一百倍。真的非常谢谢老师,真的超赞。
李老师你就是古时候掌管ML教学的神
非常喜欢老师的课程,每年都会有新的内容更新,紧跟学术界的发展。内容上深入浅出,很赞!
38:30 “天涯若比邻" 想不到一句诗点出了self-attention的精髓.
get 到这个精髓了,太厉害了 amazing
赞👍🏻
大陆学生崽一枚。李老师的机器学习课太棒了!
李老师的视频 是我的救命稻草!感谢感谢!
老師化繁為簡,舉重若輕,太厲害了!謝謝老師!
李老师的课程我看了好几遍了,每次看都有新的体会。谢谢李老师。
self-attention 天涯若比鄰的比喻實在是太妙!
感谢老师,讲的太好了!这个图解计算过程清晰易懂,我看了好多内容,就是您的最清晰!感谢!
老师备课真的是用心啊,大赞!
它是數學函式演算法,卻使用很多心理學
的詞彙,如:
學習、訓練、反省、自我注意.….😅
難怪很多外行人都以為 AI
和人腦一樣運作,甚至超越人腦😢
其實是兩回事😅
老師超棒!
化繁為簡,老師真的太厲害了>
讲self-attention竟能讲的如此清楚。。
原來是請人聽打
一直以為老師是用實驗室的語音處理模型自動幫影片上字幕XD
老师请问作业1截止了,那能看看优秀作业的范例吗?想了解一下神仙是怎样调参的
感謝! 看了其他網上英文課都沒老師的深入淺出
醍醐灌顶。感谢教授。
self-attention是transformer最核心也最难的一块,看了好多教程都是模模糊糊的,没想到被老师一讲,喝着茶吃着点心就搞懂了,太感谢了!
李老師您好,這課程講得太清楚了,已經被您圈粉 謝謝
谢谢老师,概念忘了就回来听一遍🥰
老师讲的真好,浅显易懂。
### How Self-Attention Works
1. **Input Representation**:
- Consider an input sequence of words, each represented by a vector. For example, in a sentence "The cat sat on the mat", each word is converted into a vector through embedding.
2. **Query, Key, and Value Vectors**:
- For each word in the sequence, self-attention computes three vectors: Query (Q), Key (K), and Value (V).
- These vectors are derived by multiplying the input vector with three different weight matrices that are learned during training.
3. **Attention Scores**:
- The attention score for a word is computed by taking the dot product of its query vector with the **key vectors of all words** in the sequence. This score indicates **the importance of other words to the current word**.
- Mathematically, this can be represented as:
$Attention Score(Q,K)=Q⋅KT$
$Attention Score(Q,K)=Q⋅KT\text{Attention Score}(Q, K) = Q \cdot K^T$
4. **Softmax**:
- The attention scores are normalized using a softmax function to get the attention weights, which sum to 1. This helps in converting the scores into probabilities.
5. **Weighted Sum**:
- The final representation of each word is computed as a weighted sum of the value vectors, where the weights are the attention weights calculated in the previous step.
- Mathematically:
Output=$Softmax(Q⋅KT)⋅V$
Output=$Softmax(Q⋅KT)⋅V\text{Output} = \text{Softmax}(Q \cdot K^T) \cdot V$
****4:00** Representing the process of acquiring Q, K, V as matrix operations**
a1, a2, a3, a4 can be grouped as a matrix A
q1, q2, q3, q4 can be grouped as a matrix Q
and so on…
W A = Q
14:35 The only parameters that require training are Wq, Wk, Wv.
****15:04** Multi-Head Self Attention**
Number of heads is a hyperparam
2 Heads → 2 Queries, 2 Keys, 2 Values
3 Heads → 3 Queries, 3 Keys, 3 Values
……
19:00 But this means you have multiple bs, this requires additional transform to compute the output.
原本Head = 1, Value乘完Attention Score可直接輸出,Multi-head需要多一步處理
****19:15** Positional Encoding**
Self-Attention doesn’t have position info.
Use positional encoding if you believe “position” is a required part of your data.
****26:00** Truncated Self-Attention**
Speech is often very long. We can limit the range to a specific part of the speech, no need to consider the whole sequence
****28:00** Self-Attention for Image**
****29:30** Self-Attention VS CNN**
CNN is self-attention with its range limited to the receptive field
→ CNN is simplified self-attention (CNN is more restricted)
→ Self-attention is CNN with a learnable receptive field. The kernel size is learned by the model, not set by the programmer. (Self-attention is more flexible)
****32:30** Flexible Models Need More Data**
Flexible models need more data, otherwise you’ll encounter overfitting
CNN is good enough when given a small amount of data, but eventually stops improving when fed more
Self-attention can surpass CNN if given enough data
****35:10** Self-Attention VS RNN (Recurrent Neural Network)**
### RNN Key Characteristics
1. **Sequential Data Handling**:
- RNNs are designed to handle sequential data by maintaining a hidden state that captures information from previous steps in the sequence. This allows the network to have a form of "memory" that can be used to inform its predictions.
2. **Recurrent Connections**:
- Unlike feedforward neural networks, RNNs have connections that loop back on themselves. This feedback loop allows information to persist, making RNNs well-suited for tasks where the order of inputs matters.
****38:00** How RNN Works**
Self-attention can replace RNN
RNN must generate each vector one-by-one because the next vector requires the previous vector to compute.
Self-attention can generate all vectors in parallel
**那篇很有名的Transformer論文Attention is all you need說: “**Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states $ht$, as a function of the previous hidden state $ht−1$ and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.**”**
40:30 Self-Attention for Graph
If two nodes are not connected, we don’t need to compute their attention score
→ GNN 坑很深
李老师你好,您的PPT上说会将优秀的代码和报告公开给大家学习,请问在哪里能找到那些优秀的同学的代码呢
先头香再瓜子看上。最近有篇被iclr拒掉的用kernel Hilbert space解释attention的文很有意思。
老師好,由於tensorflow在某個版本後,內建的lstm (rnn)是CudnnLSTM ,所以初學者如果在不知情的情況下,直接與self-attention進行比較,會發現self-attention速度並不會比lstm (rnn)來得快,希望老師也可以介紹一下CUDNN系列的RNN
理論上self-attention是並行處裡,應該會比rnn快才對@@
请问prof. lee提到的课后作业以及答案在哪里可以查看
这个真的是讲的非常之清楚了
Wq, Wk, Wv 是隨機初始化 然後再依照資料不斷優化而得到.
所以 不同組別的 (Wq, Wk, Wv) 就隱含著代表不同的 local minimum
這樣的理解是正確的嗎?
我感觉self-attention在执行之前所有向量必须都准备好,而RNN可以随输入随输出。这个是self-attention的一个缺点。
太有帮助了,非常感谢老师。
谢谢老师。在10:42这个时刻的slide, 请问是不是模型的本质只有一个Wk, 一个 Wq 和 一个Wv 这三个矩阵而已。这里的 A矩阵是临时的feature, 因为例子是4个输入,所以得到的A就是4x4。但是其实同一个模型,可以处理任意长度的输入,比如输入了15927个input,那么仍然通过Wk, Wq和Wv 这三个参数矩阵得到了15927x15927 这么大的A。请问这么理解正确吗?
讲的太好了,谢谢老师!
老師可以請問在 19:14 計算multi-head的時候,為什麼不直接從ai 得到 (qi,1), (qi,2),而是先得到qi再去得到後面兩個向量 (qi,1), (qi,2)
我认为这种做法相当于是增加了网络的深度,类似于在CNN或FC中增加了一层
这样也可以,就是减小了模型的弹性
老师讲得真的太好了
谢谢,讲的很清楚
@Hung-yi Lee 老師,您好!
看完self-attention和rnn的比較覺得觀念更好了,想請問很多論文架構會將它加在lstm後面的用意是訓練過程中取得重點資訊和平行輸出結果嗎
另外,TCN和self-attention都是有平行輸出的優點,但也常常看到兩者結合,self-attention有的放在前面,有的放在後面,但不知道怎麼樣的架構比較合適,又如何解釋為何這樣結合結果比較好
謝謝老師 精彩的課程!
一个小小的建议:比如在12:48时,矩阵中元素的第一标角标最好用来表示行,第二个角标表示列。你的表示方法应该是刚好相反。总体而言,这是一个非常好的lecture, 感谢分享。
那是大陸這邊是台灣
我認為那並不是單純矩陣元素的角標,α1,1 α1,2 α1,3 α1,4分別代表的是q1與 k1 k2 k3 k4 的transpose做dot product的結果,而老師為了表示運算結果在矩陣中的位置,故直接沿用(α x,x)這樣的表示法,所以你可以把它看成是運算結果的編號,不是元素的角標。
p.s. 可以參考教授的線性代數課堂,教授確實是用你提到那種常用的表示法。
@@三-o2k 在學術交流的情況下提這種話題不太恰當吧,大家都是讀書人,在為知識進步做貢獻,不需要有攻擊性。
@@Vic870209 台灣的行列確實是大陸的列行, 定義顛倒.
可以問一下老師在自注意機制時求Q1,Q2時他們乘上的Wq都是一樣的嗎
感觉黄老师,希望您身体健康,科研顺利,可以一直给大家带来优质平等的学习资源,respect!
人家last name是Lee😂
你是故意的吗😂😂😂
v1向量的维度和[a1,1prime,a1,2 prime,a1,3prime,a1,4prime].T的维度是否是同样的?[a1,1prime,a1,2 prime,a1,3prime,a1,4prime]是否是4个数,表达一个4x1的列向量.
老师讲的太好了,想催更一下
得到的4x4的ai,j prime 的矩阵,是否都是数值的,就是16个数字而非向量.那么V矩阵中的v1,v2,v3,v4的维度是什么呢?是否和ai一致?
讲得太精彩了,谢谢老师🙏
为什么18:20处要先得到qi再分别乘两个矩阵呢,不能直接乘两个不同的矩阵吗,因为都是线性变换,结果应该没区别,但后面的情况还能少一些参数啊
我看pytorch的multi head attention的doc是將qkv的W矩陣先分成n_head份,我推測是將sequence embedding與分成n_head份的qkv dot product後分別得到n_head份的qkv,或許不是得到qi再乘兩個矩陣
如果 CNN + Positional Encoding? 是否會有幫助?
总觉的那个CNN和Self-Attention差别还是挺大的,CNN对每个receptive field里面的pixel学一个weight,self-attention对于所有的pixel应该是学了一个相同的函数,只是这个函数是非线性的。不知道这个理解对不对。
25:01 P.31 Many application
请问老师value vector有什么作用?
讲的很清楚,太棒了!
非常感谢老师,讲的非常容易理解。有个问题想问一下,您这里讲的注意力的计算公式是:O=V*softmax(K^T*Q),但是论文中的计算公式是:O=softmax(Q*K^T)V。这两者的本质是不是一样的?
一样的,算出来是两个矩阵
我也有同樣的問題
一样的。老师这里把a_i这些当作了column vector,而很多文章里都会把它们当作row vector。这两种推导也因此差一个转置。
请问老师,bi是向量还是一个数值?
v1,v2,v3,v4是scalar 吗?
请问老师这里的wq,wk都是一样的吗?比如q1=wq a1,q2=wq a2
请教李老师说,有没有研究解释head应该怎么选,或者说起码empirically应该怎么选吗?
為什麼RNN會幾乎被Transoformers 取代而CNN在數據不足的情況下有優勢? 之前說過越少Data,就數對地用較單間的方法處理, CNN在數據上有這種結果, RNN 會不會也是一樣
RNN 最大的問題會卡在兩個:
1. 距離較遠的相關資訊逐漸遺失
2. 結構上較難以矩陣處理,就不能仰賴 GPU 的平行運算來提高速度
當然如果你要解決的問題很簡單、資料本身的複雜度不高的話,採用 RNN 的效果差異性就比較少
(但一般來說,Transformer 有加速,所以你資料量一提上去就會改用 Transformer 基底的模型了~)
(另外就是因為 RNN 多用在序列,以文字來說:通常資料本身變化性很高、複雜度很高,attention 在這方面真的很有幫助)
according to 個人經驗XD
想請問
I Saw a Saw
能判斷出"相同單詞不同詞性"
是因為有Position Encoding
還是Self Attention
還是其實兩技術都具有能判斷出"相同單詞不同詞性"
请问在网络中需要学习的除了 QKV 三个矩阵之外,每个单词(输入)的向量表示 也是 学出来的吗?
在这里催更会被打吗_(:зゝ∠)_ 老师的课讲的也太好了
学习了,很清晰
請問self-attentioin 可以應用在時間序列的資料上嘛
请问老师, 除了W_q, W_k, W_v, 输入embeding I, 应该也是可以通过学习去调整的吧。
help,positional encoding部分,为什么ei+aI之后就能学习到位置信息?时间22:20
如有錯誤請指正~
我看到的理解是,每個e都帶有位置訊息,e1e2..ei,因此只要加入e這個參數,就把位置訊息帶進去了。
謝謝老師
作业在哪里看?
无敌。
感谢老师
非常感謝老師能創作、教授這麽優質的課程,我是一個來自大陸的學生,非常感謝老師的幫助。大陸的高等教育堪憂,我全靠各種網絡上的資源學習。
厲害
14:40弹幕: 真的屌爆了
位置資訊直接加進input好像不太合理,是不是應該要放在其他dimension處理?
我也有這樣的疑問, 讓我開始懷疑我對加法的認知 :)
可以去看2019年的版本
@@yo-pg8re 感謝,懂了👍
老師請問Theory of ML的視頻可以上傳麼?
想問有人知道這樣Multi-head在訓練的時候, 會不會Wq,1和Wq,2學得很像?
应该不会吧。毕竟initializaiton不一样,就像CNN同一层conv layer不同的filter训练结果也是不一样的。
李老師,請問truncated attention和local attention的區別在哪裡呢?
讀了原作者的paper後,我的理解是,truncated attention的前後長度是可以不同的,比如在paper中,作者設定左邊的長度L=5,右邊的長度R=3,但是local attention的話,前後長度是一樣的。
請問我的理解正確嗎?
very nice course, thx U
感谢🙏
非常感謝老師的講解,聽完馬上就懂self-attention的原理了!
但是我有一個問題,請問在RNN中,每個vector的FC是共用同一個嗎? 還是獨立開來的?
每個vector的FC是共用的,FC是一個矩陣,將hidden vector轉換爲output vector作爲為每一個RNN Block的輸出
Great videos!
Please upload the English translated version of self-attention part 2
why we need positional encoding --> no position information in self-attention.
👍👍👍
推
牛逼
good
我本硕大陆985。跟Prof Lee比较,大陆课上讲的内容简直就是笑话,照本宣科,毫无创新。
簽
ino prada xD
但是讲的真的好!
老师应该是日本留学的台湾籍人士
老師學碩博都是台灣大學喔~
q是什么呢
谢谢老师!讲的太好了!