terimakasih banyak telah membagikan ilmunya, bermanfaat sekali dan sangat mudah dipahami oleh saya yang benar2 tidak pernah menyentuh machine learning sebelumnya, semoga berkah
Please lanjutkan seri ini pak, kalo bisa sampai unsupervised learning(clustering dsb). Terima kasih ilmunya pak. Saya sudah banyak ilmu dari channel ini. Terus berkembang menjadi lebih baik :)
Playlist belajar machine learning ini pasti akan kami lanjutkan. Saat ini kami masih menggodok materi terkait logistic regression. Ini akan menjadi topik pembelajaran untuk sesi ke 12. Oh ya, bilamana mendapatkan manfaat dari channel Indonesia Belajar ini, jangan lupa untuk merekomendasikannya juga ke teman2 yang lain :)
He3... Ini belum masuk NLP sih, masih di dasar machine learning dulu. Bertahap ya. Saya coba susun materi belajarnya supaya tetap ramah bagi pemula. Harapannya makin banyak orang yang tertarik untuk mendalami bidang machine learning ini :)
selamat siang pak izin bertanya, maksud dari penjelasan kata cat ada di dokumen ke 2 dan dokum 4, itu yg diliat dari mana nya ya pak saya masih beluum memahami nya. pada menit 12:59
terimkasih videonya sangat bermanfaat,sya sedang masuk metopen tntang analisis sentimen menggunakan SVM apakah bisa menjelaskan cara manual untuk perhitungan SVM nya pak setelh perhitungan tfidf .Karena saya masih kurang paham setelah selsai menghitung tfidfnya saya jadi bingung klasifikasikan ke SVM nya karena jurnal2 tidak lengkap dalam menjelaskannya,terimkasih
Permisi pak, saya ingin bertanya, apakah bisa metode TF-IDF dengan Sklearn ini diterapkan pada dataset yg sdh di tokenizing sebelumnya? Jika bisa, bagaimana caranya ya pak? Sebelumnya terimakasih pak
Unable to allocate 59.1 GiB for an array with shape (133314, 59486) and data type float64, saat mau ngerubah ke bentuk dataframe, kenapa muncul tulisan gitu ya pak? cara mengatasi nya bagaimana ya?
Terima kasih banyak penjelasannya membuat lebih memahami tf idf. Saya mau menanyakan jika untuk document bentuk csv langsung dibuat objek untuk pemanggilannya saja? boleh dicontohkan scripnya bagaimana? terima kasih Pak :)
Untuk dataset dalam format csv, kita bisa load sebagai pandas data frame. Di channel Indonesia Belajar ini kami sudah menyediakan satu playlist khusus yang membahas topik terkait Python Pandas Dataframe. Semoga bisa bermanfaat 😊🙏
@@belajaridn Baik Pak, sudah saya coba. Izin bertanya lagi, saya memiliki data yang ribuan. bagaimana cara untuk memudahkan membaca hasil dari tf idfnya ini? apakah perlu divisualisasikan? jika iya, ada saran dari Bapak saya bisa pakai apa utk memvisualkan? saya saat ini bingung untuk menganalisis hasil dari tf idf nya.
@@hidayatulfitri2965 Terkait kebutuhan visualisasi data, silakan untuk mempelajari playlist Belajar Visualisasi Data dengan Python Matplotlib. Di sana kami menyajikan materi visualisasi dasar dari dasar sehingga mudah untuk dipelajari bagi pemula.
permisi pak ijin bertanya, jujur saya masih awam dan baru belajar machine learning, kemarin saya coba ikuti di video ini saya pake google colab, saya coba-coba pakai dataset yang berasal dari kaggle , dan prosesnya bisa sampai seperti di akhir video, yang saya tanyakan, di video ini apa hanya hasil preprocessing atau data yang sudah melalui proces tf-idf ?
ingin bertanya pak, kalau ingin menggunakan dataset/corpus sendiri yang berada dalam bentuk file csv untuk menjalankan perhitungan tf-idf nya, bagaimana ya pak caranya? terima kasih banyak.
Bisa load dulu datasetnya ke dalam Pandas Dataframe. Bilamana belum familiar bekerja dengan Python Pandas Dataframe, di channel Indonesia Belajar ini kami sudah menyediakan satu playlist khusus yang membahas topik Pandas Dataframe.
Pak saya diminta untuk topic dan sentimen analysis,apakah sklearn bisa menghandle hal tersebut?atau saya harus belajar NLP,saya coba cari library yang support bahasa indonesia hanya NLTK dan Spacy,kasus seperti ini seperti apa ya pak?
Untuk fit_transform sebenarnya terdapat dua buah proses yang dijadikan satu, yaitu fit dan transform. Nah karena proses fit sudah dilakukan pada fase training, maka pada saat testing kita bisa langsung aplikasikan dengan transform saja ☺️👌☕
permisi kak setelah mengikuti tahap TF-IDF itu, bagaimana caranya buat implementasikan hasil TF-IDF tersebut sebagai fitur di model ?jika targetnya numerik? mohon arahannya kak
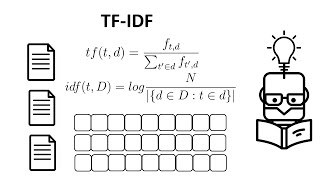
Kak mau nanya penjumlahan idf pada keluaran kata tf di log hasil nya semakin kecil yaa contoh nya dokumen ada 3, keluaran kata tf ada 2 kata untuk mencari hasil log(Dokumen keseluruhan /di bagi tf)= log(3/2) hasil nya kecil dari pada log(3/1)
Padahal harusnya kata terbanyak mendominasi harus nya, ini untuk model saya kak, tapi matematik manual nya masih bingung saya kak naive bayes classifier modelnya
Untuk TF-ID terdapat beberapa variasi kalkulasi. Untuk lebih detailnya bisa mempelajari dokumentasi Scikit-Learn. Di sana mestinya ada referensi terkait research paper yang dijadikan acuan formulasi yang diterapkan juga 😊☕
iya nih, mungkin next bisa buat pembahasan video perhitungan manualnya ya Pak, agar kita yg nonton bisa paham juga perhitungan manualnya kl menggunakan scikit learn 😁









Makasih banyak bang,,, untuk vectorizer.get_feature_names() udah diganti sama vectorizer.get_feature_names_out() ..
Oke noted, terima kasih untuk informasinya 😊☕🙏
terimakasih banyak telah membagikan ilmunya, bermanfaat sekali dan sangat mudah dipahami oleh saya yang benar2 tidak pernah menyentuh machine learning sebelumnya, semoga berkah
Sama-sama, senang bisa membantu ☺️☕🙏
mau salim sama yang bikin... mudah dipahami dan ga belibet bgt. trimakasiii udah buat video ini!
Alhamdulillah kalau memang bermanfaat. Kami juga senang bisa menghasilkan materi pembelajaran yang bermanfaat dan mudah dipahami 😊🙏
@@belajaridn btw pak, udah pernah buat tentang lexicon kaah?
Belum mas, kebetulan fokusnya masih pada pengenalan Machine Learning. Untuk lexicon lebih spesifik ke NLP.
baru pertama liat videonya. sabar ngajarnya, short juga... bagus & berkualitas... teruskan Pak Dosen :-)
Terima kasih, semoga bisa bermanfaat bagi banyak orang 😊🙏
Terimakasih banyak pak atas segala materi yang telah disampaikan.
Sama-sama, senang bisa membantu. Playlist ini masih on going, tetapi memang ada kendala dalam penggarapannya. Mohon kesabarannya ya 😊🙏
@@belajaridn baik pak, kalau boleh, saya request unsupervised learning pak hehe
Siap, K Means memang akan kami bahas selepas kami membahas topik boosting. Mohon kesabarannya ya 😊☕🙏
Please lanjutkan seri ini pak, kalo bisa sampai unsupervised learning(clustering dsb). Terima kasih ilmunya pak. Saya sudah banyak ilmu dari channel ini. Terus berkembang menjadi lebih baik :)
Playlist belajar machine learning ini pasti akan kami lanjutkan. Saat ini kami masih menggodok materi terkait logistic regression. Ini akan menjadi topik pembelajaran untuk sesi ke 12.
Oh ya, bilamana mendapatkan manfaat dari channel Indonesia Belajar ini, jangan lupa untuk merekomendasikannya juga ke teman2 yang lain :)
Terimakasih ilmunya
Sama-sama, semoga bermanfaat ya 😊🙏
kerenn sekalii pak dosen, lanjut NLP lagi xixixi 🙏🏻
He3... Ini belum masuk NLP sih, masih di dasar machine learning dulu. Bertahap ya. Saya coba susun materi belajarnya supaya tetap ramah bagi pemula. Harapannya makin banyak orang yang tertarik untuk mendalami bidang machine learning ini :)
selamat siang pak izin bertanya, maksud dari penjelasan kata cat ada di dokumen ke 2 dan dokum 4, itu yg diliat dari mana nya ya pak saya masih beluum memahami nya. pada menit 12:59
Dokumen untuk konteks kasus di sini adalah kalimat. Kata cat terkandung pada kalimat ke 2 dan 4 dari corpus yang kita gunakan dalam kasus ini.
terimkasih videonya sangat bermanfaat,sya sedang masuk metopen tntang analisis sentimen menggunakan SVM apakah bisa menjelaskan cara manual untuk perhitungan SVM nya pak setelh perhitungan tfidf .Karena saya masih kurang paham setelah selsai menghitung tfidfnya saya jadi bingung klasifikasikan ke SVM nya karena jurnal2 tidak lengkap dalam menjelaskannya,terimkasih
Mas, apakah TF-IDF dan cosine similarity bisa digunakan untuk membuat deteksi duplikasi file?
Permisi pak, saya ingin bertanya, apakah bisa metode TF-IDF dengan Sklearn ini diterapkan pada dataset yg sdh di tokenizing sebelumnya? Jika bisa, bagaimana caranya ya pak? Sebelumnya terimakasih pak
Unable to allocate 59.1 GiB for an array with shape (133314, 59486) and data type float64, saat mau ngerubah ke bentuk dataframe, kenapa muncul tulisan gitu ya pak? cara mengatasi nya bagaimana ya?
He3... kalau ini nampaknya lebih pada keterbatasan hardware yang digunakan mas :)
Terima kasih banyak penjelasannya membuat lebih memahami tf idf. Saya mau menanyakan jika untuk document bentuk csv langsung dibuat objek untuk pemanggilannya saja? boleh dicontohkan scripnya bagaimana? terima kasih Pak :)
Untuk dataset dalam format csv, kita bisa load sebagai pandas data frame. Di channel Indonesia Belajar ini kami sudah menyediakan satu playlist khusus yang membahas topik terkait Python Pandas Dataframe. Semoga bisa bermanfaat 😊🙏
@@belajaridn Baik Pak, sudah saya coba. Izin bertanya lagi, saya memiliki data yang ribuan. bagaimana cara untuk memudahkan membaca hasil dari tf idfnya ini? apakah perlu divisualisasikan? jika iya, ada saran dari Bapak saya bisa pakai apa utk memvisualkan? saya saat ini bingung untuk menganalisis hasil dari tf idf nya.
@@hidayatulfitri2965 Terkait kebutuhan visualisasi data, silakan untuk mempelajari playlist Belajar Visualisasi Data dengan Python Matplotlib. Di sana kami menyajikan materi visualisasi dasar dari dasar sehingga mudah untuk dipelajari bagi pemula.
permisi pak ijin bertanya, jujur saya masih awam dan baru belajar machine learning,
kemarin saya coba ikuti di video ini saya pake google colab, saya coba-coba pakai dataset yang berasal dari kaggle , dan prosesnya bisa sampai seperti di akhir video, yang saya tanyakan, di video ini apa hanya hasil preprocessing atau data yang sudah melalui proces tf-idf ?
Mau tanya pak budi, apakah untuk text nya tidak perlu dilakukan tokenisasi? Tks.
Apakah TF-IDF dapat diterapkan ke metode Naive Bayes pak?
ingin bertanya pak, kalau ingin menggunakan dataset/corpus sendiri yang berada dalam bentuk file csv untuk menjalankan perhitungan tf-idf nya, bagaimana ya pak caranya? terima kasih banyak.
Bisa load dulu datasetnya ke dalam Pandas Dataframe. Bilamana belum familiar bekerja dengan Python Pandas Dataframe, di channel Indonesia Belajar ini kami sudah menyediakan satu playlist khusus yang membahas topik Pandas Dataframe.
@@belajaridn terima kasih pak
@@belajaridn kalau pakai file csv transformasinya kemana pak ?
@@crispikriyuk9119 Sebagian besar pengolahan dataset pada Python umumnya akan memanfaatkan Pandas Dataframe :)
@@belajaridn maaf pak boleh share linknya mengenai Dataframe untuk tf idf ?, soalnya ada banyak video ttg Dataframe
Mau tanya algoritma TF-IDF ini apakah merupakan salah satu jenis - jenis algoritma Data Mining?
Yup, TF-IDF dan beberapa teknik dalam bidang machine learning secara umum juga banyak dibahas di area data mining 😊
@@belajaridn Apakah ada teori tentang TF-IDF?
pak saya sudah melihatnya saya bandingin rupanya hasil output itu pakai binary..... kalau buat kayak raw tf, logarithmic tf, augmented tf gimana ?
izin bertanya pak, apakah tf-idf merupakan feature engineering terbaik dibandingkan bag of words, one hot encoding, dll ?🙏🏻
Sebenarnya tergantung pada kasus yang dihadapi. Oleh karenanya pemahaman terhadap konteks dataset sangatlah penting.
Pak saya diminta untuk topic dan sentimen analysis,apakah sklearn bisa menghandle hal tersebut?atau saya harus belajar NLP,saya coba cari library yang support bahasa indonesia hanya NLTK dan Spacy,kasus seperti ini seperti apa ya pak?
Untuk explorasi terkait NLP bisa memanfaatkan NLTK 😊☕👍
@@belajaridn Apakah NLTK support bahasa indonesia pak?
Untuk dukungan bahasa Indonesia sepertinya belum ada.
Kira2 bisa diterapkan untuk apa saja ya dengan algoritma tf-idf? Terima kasih.
Beberapa penerapannya bisa untuk Document Classification, Topic Modeling, Information Retrieval System, dan juga Stop word filtering.
Saya penasaran Pak, kenapa di TF-IDF pada saat training data pakai method fit_transform saja sedangkan pada test data pakai method transform?
Untuk fit_transform sebenarnya terdapat dua buah proses yang dijadikan satu, yaitu fit dan transform. Nah karena proses fit sudah dilakukan pada fase training, maka pada saat testing kita bisa langsung aplikasikan dengan transform saja ☺️👌☕
Apakah tiap baris kalimat pendek memiliki nilai Tfidf nya sendiri ?
permisi kak
setelah mengikuti tahap TF-IDF itu, bagaimana caranya buat implementasikan hasil TF-IDF tersebut sebagai fitur di model ?jika targetnya numerik?
mohon arahannya kak
Kak mau nanya penjumlahan idf pada keluaran kata tf di log hasil nya semakin kecil yaa contoh nya dokumen ada 3, keluaran kata tf ada 2 kata untuk mencari hasil log(Dokumen keseluruhan /di bagi tf)= log(3/2) hasil nya kecil dari pada log(3/1)
Padahal harusnya kata terbanyak mendominasi harus nya, ini untuk model saya kak, tapi matematik manual nya masih bingung saya kak naive bayes classifier modelnya
Tolong di respon yaa kak terimkasi
bang kamu droomp ya suaranya mirip bngt
nyoba itung manual, udah dicek bolak balik kok hasilnya bisa beda ya bang sama yg di TfidfVectorizer()
Untuk TF-ID terdapat beberapa variasi kalkulasi. Untuk lebih detailnya bisa mempelajari dokumentasi Scikit-Learn. Di sana mestinya ada referensi terkait research paper yang dijadikan acuan formulasi yang diterapkan juga 😊☕
iya nih, mungkin next bisa buat pembahasan video perhitungan manualnya ya Pak, agar kita yg nonton bisa paham juga perhitungan manualnya kl menggunakan scikit learn 😁