Thanks for the good work. I am still practicing the FrozenLake DQL+CNN and wonder how to train the model on CUDA as the training time keeps increasing.
Thank you for the continual support, Andy! Here are some general guidelines on using CUDA: # First, make sure you have CUDA installed properly and is supported by your GPU device = 'cuda' if torch.cuda.is_available() else 'cpu' print(device) # Then, anywhere that uses the network should be sent to CUDA, for example: DQN(....).to(device) # Also, anywhere that deals with Tensors should be sent to CUDA, for example: torch.FloatTensor(...).to(device) torch.IntTensor(...).to(device) Note that when you run your code and Pytorch complains that not everything is on the same device, it means you didn't send something to CUDA using "to(device)".




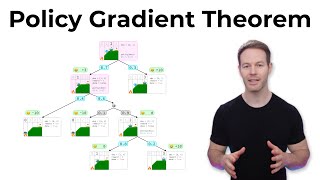





Let me know if you want the code walkthru and demo.
Where is the code?
@@peterhpchen Here you go github.com/johnnycode8/gym_solutions/blob/main/cliff_walking_reinforce.py
Thanks for the good work. I am still practicing the FrozenLake DQL+CNN and wonder how to train the model on CUDA as the training time keeps increasing.
Thank you for the continual support, Andy! Here are some general guidelines on using CUDA:
# First, make sure you have CUDA installed properly and is supported by your GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
# Then, anywhere that uses the network should be sent to CUDA, for example:
DQN(....).to(device)
# Also, anywhere that deals with Tensors should be sent to CUDA, for example:
torch.FloatTensor(...).to(device)
torch.IntTensor(...).to(device)
Note that when you run your code and Pytorch complains that not everything is on the same device, it means you didn't send something to CUDA using "to(device)".
@@johnnycode thanks a lot for the help. And It works!
@@kimiochangThat’s great 👍
One question why it has to be log? It is a bit confusing part to be honest.
This page explains the math that arrives to log(): mcneela.github.io/math/2018/04/18/A-Tutorial-on-the-REINFORCE-Algorithm.html
Check out OpenAI’s SpinningUp, they explained that.