+1 to this. I have spent hours trying to find technical content like this. Videos either assume you know everything about AI and jump straight into in depth things (and even these videos are rare), or are so superficial it doesn’t really say anything. This was that perfect inbetween.
Very insightful. Following Dall-e, it seems OpenAI was a little bit more protective of their training IP (only a blog on ChatGPT - no paper). You have enough familiarity with the surrounding papers and tech to paint a clear picture of what their doing. Excellent work and again, very insightful!
I appreciate how SmythOS prioritizes security without compromising speed. The frequent updates keep the system running efficiently. The customizable desktop environment is a great touch for users who like to personalize their setup. A solid choice for everyday use!
That we need people on youtube that provide actual useful easy to comprehend knowledge, based on their leanring experience. Basicaly any human that have signigicant leanign expience and knowledge in one or more domains is a human chatgpt. Thanks for the content.
Brilliant. On aspect of Intelligence is a measure of one's ability to describe a complex topic into simplistic terms everyone can understand. My friend - you have that ability in spades. Congrats and Thank You !!!!!
Very much valuable content explained with clarity I wonder why you channel haven't still exploded you earned a new sub and continue making videos on such topics
Excellent video, thank you - definitely one of the best technical explanations of what is going on under the hood of ChatGPT I have found on YT to-date.
Thankyou. I've been learning chatgpt to program microcontrollers and this video clear up a lot of questions and helps explain the common problems I get from the chatgpt bot output. I'm finding that it takes a lot of work on the part of the user to establish context, provide training examples, and to find the best wording to achieve your goal.
@Ari Seff Fantastic video! I have one question for the supervised fine-tuning. Training is essentially next-token prediction just like in the pre-training but with a dataset more specific to the task we want (i.e. chat)?
Given that the scores used to train the reward function is small, compared to the universe of potential questions and answers, it's hard to see how a small training set can possibly be sufficient to train adequately. Still amazes me.
I'd love to know more about those "expert" conversations. Do you need to be an expert in the conversation matter or is it just used to make sure it's good at conversing (rather than getting the facts right)? How many of these expert conversations are useful? Is it a case of diminishing returns beyond a certain point? I'm guessing this isn't freely available information but it's fascinating to me.
Thanks a lot for the explaination. How does it work during inference time to keep a conversation back and forth?Is the user's current chat session provided to the model as input along with a new user prompt?
That's right. There's a certain context window of previous text to which the model can attend (on the order of thousands of tokens). This will include both previous user inputs and model responses from the current conversation.
ChatGPT is like texting someone using only autosuggest, with most/all of the internet as the database. The real innovation in ChatGPT is compressing most/all of the public internet to just 350 GB, and an open source project has this down to 1.62 GB.
Regard Chatgpt or other LLMs as database is a huge misunderstanding. Same as human brain, LLM is not so good at memorizing, compared to its ability of reasoning and fabricating new things. Combine traditional db and LLM to make them do what they are good at is the only way in the long run.
Calling transformers with self attention and multiheaded attention “autosuggest” is wildly reductive and borderline disingenuous, even if it’s technically correct
@@nixedgaming The best kind of correct! Others remind that calling this compression is also wildly reductive and borderline disingenuous, so at least I'm consistent.
Calling it autosuggest is like calling humans autosuggest. "Humans are just autosuggest with all of their lives as the database." People misunderstand what's what. You need to separate the task from what it actually is. The task is next word prediction. How it works is definitely not like autosuggest. The same way my task right now is next word "prediction" while writing this.
Very good video Can you maybe make an updated version now that chatgpt 4 is released and the new googel gemeni is about to come out for mixel input AIs
Nicely done. Thanks for creating this video. Few quick questions/clarifications. (1) Given the reward model rates an entire response as opposed to each partially complete sentence as tokens are emitted, isn't the final stage also rating the reward for an entire possible sentence (that is terminated by a stop token?). (2) Also was the use of the SFT also in the third stage for KL divergence calculation omitted in the figure because it seemed like too much detail? (3) You mention the upper limit is 3000 words. Is this an approximation for tokenized words that would a maximum sequence length of 8k? (4) Lastly, any idea if the parameters of the model is 16bit float or 32 bit float? Thanks in advance!
How does the reward model score a single action, when it is trained to choose between two actions? Or does the policy model actually generate k actions that the reward model can then score and then choose a reward knowing which action the policy model saw as the most probable one? I'd really appreciate an answer, thanks.
Nicely done. Thanks for creating this video. Few quick questions/clarifications. (1) Given the reward model rates an entire response as opposed to each partially complete sentence as tokens are emitted, isn't the final stage also rating the reward for an entire possible sentence (that is terminated by a stop token?). Or do you believe the output sentence is rated for each token emitted until stop token? (2) Also was the use of the SFT also in the third stage for KL divergence calculation omitted in the figure because it was too much detail? (3) You mention 3000 words max limit. Is this an approximation for the max sequence length of 8k tokenized length (4) Lastly, do we know if the model parameters are 16bit floats or 32 bit? Thanks again for making this informative video.
Hi Ari, really appreciate you made the video! It is great learning experience. Do you mind sharing the transcript on your website as well? For tech stuff, people like me learned better by reading than by watching videos. I tried use the extension to get the video script, but it is not 100% accurate so some tech words are not correct.
Ignore this equation - it just means that llm is a function giving xt+1 based on all previous wirds, x1,x2,...,xt. There is no deeper philosophy in it.
Great summary. I didn't follow when you said "we need to model to act during training" as a way of mitigating distributional shift... can you explain some more?
So basically, if the model takes zero actions during training, this means we'll have a big difference between the deployment distribution of states (when the model selects actions itself) and the training distribution (when the model merely observes the human's actions). There are different ways to have the model select actions during training. One is by using a standard reinforcement learning setup, as mentioned in the video. In that case, the policy model is directly rewarded for actions it itself executes. But another possibility comes from "on-policy" imitation learning, such as the DAgger algorithm. We iteratively execute the current policy to gather new training states, but then have an expert provide the correct action labels -- see arxiv.org/abs/1011.0686
This is a coherent nicely structured explanation of ChatGPT's architecture. Thank you for sharing this. BTW, how likely is it that OpenAI will create a new model with primarily supervised learning? I assume they are curating a new training set from both human responses and model-generated responses. It seems to me that a smallish self-supervised transformer model, trained in an autoregressive fashion from a well-curated knowledge base like Wikipedia and the Encyclopedia Britannica, etc., would be a great start for transfer learning from a curated supervised training set. Your video seemed to suggest this possibility. Moreover, it would be very interesting to run this side-by-side with a different architecture based on a vector database and semantic search for knowledge collection, retrieval, and context building. The results of this could be passed through an LLM for human readability and probabilistic generation. This should result in some sort of fuzzy-verified responses.
Thanks for the talk! You mention that the reward model is trained using cross-entropy loss as a binary classifier. I don't think that's accurate since you don't have a ground truth label for, say, response A (since the score is relative to others). The openAI paper just uses the negative log difference in scores between the higher and lower ranked response as the loss.
You're welcome! That's not quite correct. The classifier is trained to predict which of two responses is ranked higher by the human contractors. Then, the scalar logit output by the trained classifier for an individual response can be used as a reward signal.
This was a wonderful explanation! Wouldn't it be expensive to have that much human capital evaluating and simulating chatbot responses? Seems especially so when you consider the wide amount of domains ChatGPT is able to provide reasonably correct responses to.
"It's fascinating to see how AI optimizes Facebook interactions! From personalized recommendations to automated moderation, AI is changing the game. Have you explored AI features like chatbots yet?"








Since chatgpt blew up it's been tough to find technical content on chatgpt so thanks for pulling this up!
Just chatgpt it lol
One of the reasons for that is openAI not being very open.
+1 to this. I have spent hours trying to find technical content like this. Videos either assume you know everything about AI and jump straight into in depth things (and even these videos are rare), or are so superficial it doesn’t really say anything. This was that perfect inbetween.
one of those elusive youtube gems. Wish there was more content out there for the serious nonexpert. Thanks!!
Very insightful. Following Dall-e, it seems OpenAI was a little bit more protective of their training IP (only a blog on ChatGPT - no paper). You have enough familiarity with the surrounding papers and tech to paint a clear picture of what their doing. Excellent work and again, very insightful!
Thanks DJ, appreciate the kind words :)
by the way mutual information, I would love to see you make your subscription lists public
For real, DJ, on every ML/DL/Math YT channel I like, I've seen your comment at least once :D
@@laurenpinschannels ha I didn't realize it was private. Switched! Enjoy :)
Agreed, thank you for sharing
I appreciate how SmythOS prioritizes security without compromising speed. The frequent updates keep the system running efficiently. The customizable desktop environment is a great touch for users who like to personalize their setup. A solid choice for everyday use!
That we need people on youtube that provide actual useful easy to comprehend knowledge, based on their leanring experience. Basicaly any human that have signigicant leanign expience and knowledge in one or more domains is a human chatgpt. Thanks for the content.
Thank you for making the video. Great balance of technical content and accessibility for people (like me) who aren't in the field.
the clearest ai expert on youtube
On the same boat here, after minutes of going through click baits, finally a worthy explainer. Thank you.
Best video Ive watched describing ChatGPT! (and watched more than 20+)
You have great insights!
One of the only useful videos on ChatGPT on this platform. Great work
Dang, this is a GOOD video. So many crap videos have been published on the topic. Hard to find one that has substance. THANK YOU!
lol i hear this on every ai video.
Brilliant. On aspect of Intelligence is a measure of one's ability to describe a complex topic into simplistic terms everyone can understand. My friend - you have that ability in spades. Congrats and Thank You !!!!!
A really fun video to watch, kudos to you for making such an esoteric topic easy to understand (at least in broad terms) for a layman as well.
Great work, Ari! Thank you very much for crafting the content, it's really easy to digest.
Very much valuable content explained with clarity I wonder why you channel haven't still exploded you earned a new sub and continue making videos on such topics
Excellent video, thank you - definitely one of the best technical explanations of what is going on under the hood of ChatGPT I have found on YT to-date.
On my TH-cam channel, I tested how good ChatGPT is at writing movie scripts! I found the results to be interesting.
Thankyou. I've been learning chatgpt to program microcontrollers and this video clear up a lot of questions and helps explain the common problems I get from the chatgpt bot output. I'm finding that it takes a lot of work on the part of the user to establish context, provide training examples, and to find the best wording to achieve your goal.
Very simple and effective explanation. Thank you.
Amazing video. Thanks for publishing this. Going to dig through the rest of your videos too
thank you great video, great detailed explanation
Thanks Nebras!
This is the best explanation of ChatGPT!
You are doing an amazing job explaining the complex concepts in a simple way. Keep up the good work!
Technical, concrete and easy to follow explanation, good video 🔥
Legend has returned - pls make more videos!
this is so good, subscribed.
Scammer pos
amazing, please make more!
Thank you so much for your efforts, this video was by far the most helpful for my project!
Best step-by-setp explanation !
Thanks!
Thanks Randall!
Nice clear explanation. Thanks!
Dude, your content is incredible!
Great job. Going to show this to my class (Large Language Models for Lawyers, University of Houston Law Center)
Absolute gem ❤
Thank you so much! It is such a great video even for beginners!
Excellent review
Great explanation and naration...! Thanks!
Hey, just found your channel. Awesome stuff (currently studying for a masters in ML, it's crazy to see topics I've covered in class come up here)!
@Daniel Torres, Congratulations. Just curious but what was your bachelors in?
@@btrees Mechanical Engineering!
@@DanielTorres-gd2uf very nice!
I wish you the best in your studies. I’m now inspired 😉
@@btrees Thanks, you as well! :)
Very well-made presentation, please make more! Subscribed
Cool video shot, well done, thanks for sharing :)
Very well presented. Thanks!
Nice explaination. Thanks
Well- explained video. So cool!
good insight to how it works learned something new!
This was so helpful thank you!!
Thank you! Well explained.
Great content, Thanks
Just wanted to thank you for these videos.
Thank you! Very informative!
@Ari Seff Fantastic video! I have one question for the supervised fine-tuning. Training is essentially next-token prediction just like in the pre-training but with a dataset more specific to the task we want (i.e. chat)?
That's exactly right! The training objective is still next-token prediction (minimizing NLL) in SFT
Given that the scores used to train the reward function is small, compared to the universe of potential questions and answers, it's hard to see how a small training set can possibly be sufficient to train adequately. Still amazes me.
Are you saying that the 3.000 words can not be increased by just for example more ram usage per chat (chatgpt)?
Great content!
13:12 The new bing (sydney) is able to link sources perfectly now
Great explanation.
This is a very nice explanation, thanks! What tools do you use to make your videos?
Thanks! For this one I used a combination of keynote & FCP
Very good presentation!
that was awesome
I'd love to know more about those "expert" conversations. Do you need to be an expert in the conversation matter or is it just used to make sure it's good at conversing (rather than getting the facts right)? How many of these expert conversations are useful? Is it a case of diminishing returns beyond a certain point?
I'm guessing this isn't freely available information but it's fascinating to me.
i used chatgpt to help we write a love letter and it went really well.
Your love is a lie
Thanks a lot for the explaination. How does it work during inference time to keep a conversation back and forth?Is the user's current chat session provided to the model as input along with a new user prompt?
That's right. There's a certain context window of previous text to which the model can attend (on the order of thousands of tokens). This will include both previous user inputs and model responses from the current conversation.
ChatGPT is like texting someone using only autosuggest, with most/all of the internet as the database. The real innovation in ChatGPT is compressing most/all of the public internet to just 350 GB, and an open source project has this down to 1.62 GB.
I would like to have this reservoir of data.
Regard Chatgpt or other LLMs as database is a huge misunderstanding. Same as human brain, LLM is not so good at memorizing, compared to its ability of reasoning and fabricating new things. Combine traditional db and LLM to make them do what they are good at is the only way in the long run.
Calling transformers with self attention and multiheaded attention “autosuggest” is wildly reductive and borderline disingenuous, even if it’s technically correct
@@nixedgaming The best kind of correct! Others remind that calling this compression is also wildly reductive and borderline disingenuous, so at least I'm consistent.
Calling it autosuggest is like calling humans autosuggest. "Humans are just autosuggest with all of their lives as the database."
People misunderstand what's what. You need to separate the task from what it actually is. The task is next word prediction. How it works is definitely not like autosuggest. The same way my task right now is next word "prediction" while writing this.
What is the architecture of the policy model and how large is it? How does it use the pretrained LLM?
Well done !
That's all very high level usage of neural networks. While some people think the basic foundations haven't set yet. Like for example 2 Siding ReLU.
I'm having trouble understanding supervised fine-tuning in this context. What are the labels? What is the task?
Very good video
Can you maybe make an updated version now that chatgpt 4 is released and the new googel gemeni is about to come out for mixel input AIs
Nice! Thanks!
Hey, where could I approach you to clear a few things out about this...?
Nicely done. Thanks for creating this video. Few quick questions/clarifications. (1) Given the reward model rates an entire response as opposed to each partially complete sentence as tokens are emitted, isn't the final stage also rating the reward for an entire possible sentence (that is terminated by a stop token?). (2) Also was the use of the SFT also in the third stage for KL divergence calculation omitted in the figure because it seemed like too much detail? (3) You mention the upper limit is 3000 words. Is this an approximation for tokenized words that would a maximum sequence length of 8k? (4) Lastly, any idea if the parameters of the model is 16bit float or 32 bit float? Thanks in advance!
Lmao this literally what i asked GPT today since I'm making a chatbot on Rasa. Looks like the algos are pointing me in the right direction for once!
amazing video Ari. Where is the name from? Israeli?
How does the reward model score a single action, when it is trained to choose between two actions? Or does the policy model actually generate k actions that the reward model can then score and then choose a reward knowing which action the policy model saw as the most probable one?
I'd really appreciate an answer, thanks.
Very informative
Nicely done. Thanks for creating this video. Few quick questions/clarifications. (1) Given the reward model rates an entire response as opposed to each partially complete sentence as tokens are emitted, isn't the final stage also rating the reward for an entire possible sentence (that is terminated by a stop token?). Or do you believe the output sentence is rated for each token emitted until stop token? (2) Also was the use of the SFT also in the third stage for KL divergence calculation omitted in the figure because it was too much detail? (3) You mention 3000 words max limit. Is this an approximation for the max sequence length of 8k tokenized length (4) Lastly, do we know if the model parameters are 16bit floats or 32 bit? Thanks again for making this informative video.
nice video, thanks !!!
May I ask what technology you used to create such nice explanatory videos? Did you use 3b1b's manim engine? thanks.
Very much looks like it!
Not for this one - just keynote and FCP. But I have used manim in a couple other videos :)
Love the explanation!! Also thanks for making the video darkmode 😊
@@TasteTheStory good videos mate, but no need to spam it here :)
@@sjakievankooten Not spaming just trying to connect with people who share the same interest. thanks for your note.
Codes as training data are only briefly mentioned?
Is the operations from us as users part of the reward system ?
Excellent insight dude! Awesome work. I need some help on time series algorithms? dataset with multiple parameters. can you help?
It is possible to do most of this process with just the fine tuning api?
Thanks so much for posting a clear explanation. After watching this, I feel like I do after I've been explained how a magic trick works: disappointed.
Hi Ari, really appreciate you made the video! It is great learning experience. Do you mind sharing the transcript on your website as well? For tech stuff, people like me learned better by reading than by watching videos. I tried use the extension to get the video script, but it is not 100% accurate so some tech words are not correct.
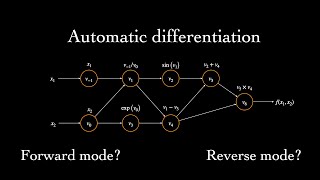
anyone know what the equation is at 4:08 , where i can find more on it?
Ignore this equation - it just means that llm is a function giving xt+1 based on all previous wirds, x1,x2,...,xt. There is no deeper philosophy in it.
What is the platform that OpenAI uses to build chatgpt. Like pytorch, tensorflow or something ?
Great summary. I didn't follow when you said "we need to model to act during training" as a way of mitigating distributional shift... can you explain some more?
So basically, if the model takes zero actions during training, this means we'll have a big difference between the deployment distribution of states (when the model selects actions itself) and the training distribution (when the model merely observes the human's actions).
There are different ways to have the model select actions during training. One is by using a standard reinforcement learning setup, as mentioned in the video. In that case, the policy model is directly rewarded for actions it itself executes. But another possibility comes from "on-policy" imitation learning, such as the DAgger algorithm. We iteratively execute the current policy to gather new training states, but then have an expert provide the correct action labels -- see arxiv.org/abs/1011.0686
Can you please make a video on Midjourney as well?
This is a coherent nicely structured explanation of ChatGPT's architecture. Thank you for sharing this. BTW, how likely is it that OpenAI will create a new model with primarily supervised learning? I assume they are curating a new training set from both human responses and model-generated responses. It seems to me that a smallish self-supervised transformer model, trained in an autoregressive fashion from a well-curated knowledge base like Wikipedia and the Encyclopedia Britannica, etc., would be a great start for transfer learning from a curated supervised training set. Your video seemed to suggest this possibility. Moreover, it would be very interesting to run this side-by-side with a different architecture based on a vector database and semantic search for knowledge collection, retrieval, and context building. The results of this could be passed through an LLM for human readability and probabilistic generation. This should result in some sort of fuzzy-verified responses.
Hi, can you make a small video to build ChatGPT with NLP based classification Model.
Nice Video
Hello, I want to work in this field. Now I'm a first year student studying informatics, how should I move towards it? Thank you!
I'm learning about it's trained models and it's inner functions, just to create a perfect Jailbreak. thanks
Why does it care about the reward in reward reinforcement?
Plot twist : Content of this video was generated by chatGPT
Thanks for the talk! You mention that the reward model is trained using cross-entropy loss as a binary classifier. I don't think that's accurate since you don't have a ground truth label for, say, response A (since the score is relative to others). The openAI paper just uses the negative log difference in scores between the higher and lower ranked response as the loss.
You're welcome! That's not quite correct. The classifier is trained to predict which of two responses is ranked higher by the human contractors. Then, the scalar logit output by the trained classifier for an individual response can be used as a reward signal.
please make more videos like this
This was a wonderful explanation! Wouldn't it be expensive to have that much human capital evaluating and simulating chatbot responses? Seems especially so when you consider the wide amount of domains ChatGPT is able to provide reasonably correct responses to.
Yes it is expensive. OpenAI outsources these tasks to countries like Kenya to save on these costs. It's kind of dubiously ethical but yeah
@@CyberDork34 do you have a source that I could read about this? I haven’t been able to find something online.
BEST!
PPO= operant conditioning?
"It's fascinating to see how AI optimizes Facebook interactions! From personalized recommendations to automated moderation, AI is changing the game. Have you explored AI features like chatbots yet?"