Timestamps: 00:04 PDF demo (analysis of two annual reports) 01:30 Visual overview of flawed architecture 06:00 Jerry Liu, Llama index RAG overview 18:34 Code walkthrough
Great video but what if we have 200 documents and we woulld like to compare strategy of bank for example. let's suppose we have 20 banks in it. The retreiver will return to much document to deal with prompt max token number. How to deal with such use case please ? regards
But here you are comparing only two documents. Have you tried the performance of the model when asked to compare between more than 2 documents, say around 10-15 documents? Or even just asking if a particular information is present in a xyz document and just interacting with a single document when the vector database has been already uploaded with the embeddings from multiple documents with each document being super long (500-600 pages)?
Does this code work with other LLMs outside OpenAI's? Because i keep getting this error -Not Implemented Error for; response = s_engine.query("Compare and contrast the risk factors of Uber and Lyft?") print(str(response))
Is this strictly used to compare the documents? I have 4 different PDF documents with information in them. The total is only 50 pages. Would it make sense to put them all into one PDF and use your approach that you used in your GPT-4 Tutorial: How to Chat With Multiple PDF Files (~1000 pages of Tesla's 10-K Annual Reports) video?
hey guys, does any one know of exmaples of llamaindex use cases where the source if returned/referenced in teh llm response. im building a complex multi document RAG and need to show the source of each answer even if taken across multiple documents?
This video is only 6 days old and the code is already giving warnings or am I missing something C:\Users\JJ\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\__init__.py:39: UserWarning: Importing BasePromptTemplate from langchain root module is no longer supported. warnings.warn( Because of this line from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex How do we get rid of these warnings?
@@JerryLiu-ff8xv It doesn't. Please let us know when the update to make these warnings goes away is live though as it does not look good for client demos when you are showing other people
Hey, Anyone worked with the notebook recently ? Im getting this error for following line: from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex "ImportError: cannot import name 'BaseCache' from 'langchain.cache' (/usr/local/lib/python3.10/dist-packages/langchain/cache.py)"

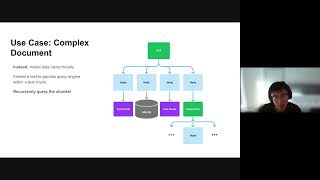








Timestamps:
00:04 PDF demo (analysis of two annual reports)
01:30 Visual overview of flawed architecture
06:00 Jerry Liu, Llama index RAG overview
18:34 Code walkthrough
Great video
but what if we have 200 documents and we woulld like to compare strategy of bank for example.
let's suppose we have 20 banks in it. The retreiver will return to much document to deal with prompt max token number.
How to deal with such use case please ?
regards
But here you are comparing only two documents. Have you tried the performance of the model when asked to compare between more than 2 documents, say around 10-15 documents? Or even just asking if a particular information is present in a xyz document and just interacting with a single document when the vector database has been already uploaded with the embeddings from multiple documents with each document being super long (500-600 pages)?
this approach won’t work in this case. You need to look for agents, maybe?
Does this code work with other LLMs outside OpenAI's? Because i keep getting this error -Not Implemented Error for; response = s_engine.query("Compare and contrast the risk factors of Uber and Lyft?")
print(str(response))
This is AMAZING content!
Thanks for sharing 🤜🤛
hey, just mentioning, looking at the code an openai key is exposed, not sure if this intentional. Thanks for the video!
Is this strictly used to compare the documents? I have 4 different PDF documents with information in them. The total is only 50 pages. Would it make sense to put them all into one PDF and use your approach that you used in your GPT-4 Tutorial: How to Chat With Multiple PDF Files (~1000 pages of Tesla's 10-K Annual Reports) video?
Love your videos
How is the question being divided into sub question , wasn't clear about that
Hey, will the other stuff about tabular data etc. be coming in a future video?
yes
Excellent video!👍
hey guys, does any one know of exmaples of llamaindex use cases where the source if returned/referenced in teh llm response. im building a complex multi document RAG and need to show the source of each answer even if taken across multiple documents?
Great guest. Let your guest speak.
what is the link for the collab ?
colab.research.google.com/drive/1Y_lUUKMdC627J5EP0dK1H8NveovpYisM?usp=sharing
did you manage to find what versions of langchain and llama-index to use? I'm having version dependency issues and I can't seem to resolve them
wut ! what a surprize ! haha
been a while
This video is only 6 days old and the code is already giving warnings or am I missing something
C:\Users\JJ\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\__init__.py:39: UserWarning: Importing BasePromptTemplate from langchain root module is no longer supported.
warnings.warn(
Because of this line
from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
How do we get rid of these warnings?
yeah we'll have a fix for these warnings soon, thanks for flagging. but this shouldn't break your current flows
@@JerryLiu-ff8xv It doesn't. Please let us know when the update to make these warnings goes away is live though as it does not look good for client demos when you are showing other people
@@JerryLiu-ff8xv BTW where are the links to the slides?
Hey,
Anyone worked with the notebook recently ?
Im getting this error for following line:
from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
"ImportError: cannot import name 'BaseCache' from 'langchain.cache' (/usr/local/lib/python3.10/dist-packages/langchain/cache.py)"
Even I am getting the same error
i am getting the same error. haven't been able to find the correct versions yet
@michamichalik9719 - did you find a way to fix the issue?