This type of explanation is perfect! First boiling the problem down to the most intuitive understanding and from there deduce the general formula. Thanks so much!
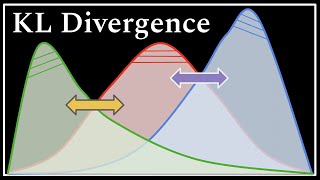
Great explanation! One technical remark I have is that (from my understanding) KL divergence is not technically a measure of distance, since it's not symmetric ( Dlk(P||Q) != Dlk(Q||P) ).
Great video! Loved the intuition behind the KL distribution. For some thinking about applications, this is used in the loss function of Variational Auto Encoders, a class of deep networks, and is used to find low dimensionality features of high dimensionality input data as an encoder. (e.g. use this to deconstruct images into "features")
A question here why will the number of heads and number of tails be the same for both the distributions at 3:04. If the probabilities for both the coins are different then the number of occurrences of heads and tails can also be different
I think the reason is because we do one experiment where we note the amount of tails and heads. We then assume that the observations are modelled by the probability distribution from the true coin. Now we want to figure out what the probability is that the amount of tails and heads we observed could be coming from coin 2. So the number of tails and heads are the same since they are literally the same, there is only one "measurement" being done.
Thanks for the explanation!! One thing is, formulas were confusing with how you denoted *q1* & *q2* for probabilities for coin 2, instead of *p2* & *q2=1-p2*
Same question here. This is a fantastic explanation but it defeats me when you mention “we normalize by raising to power of 1/N”. Why do we do this? What does that do or mean to the data? Thanks for making this video! Awesome!
I think the 1/N gives us the 'average' probability of a single toss; e.g. if we had a fair coin and had 3 tosses, the probability of our sequence would be 1/2 * 1/2 * 1/2 = 1/8. If we had ten tosses, the probability of the sequence would be 1/(2^10). These numbers are currently incomparable. If we now look at the probability of the sequence to the power of 1/N, where N is the number of tosses, then suddenly they are the same ... which is what we would want .... it basically normalizes the probability sequence!
@@vyasraina3930 so basically the 1/N gets rid of the number of tosses/sample size and in your case of a fair coin makes it so the probability would be 1/2 regardless of N by getting rid of the N (exponent in your probability sequence)
Excellent video. Can someone help me understand why is it called Divergence in the first place? Why are we taking 1/N power to normalise it to sample space, I did not understand the logic behind this.
That's a good question which I'm not sure I could answer too well. One could claim that the log function makes numbers more readable, and often when we deal with large/small numbers we log expressions first since the log operation is reversible and squeezes the range into a smaller one (e.g. e^10, about 22000, becomes 10), like is done with things like log probabilities. It could also just be mathematical convenience to drop the powers so that the overall expression looks much simpler. However I think you'd find a more satisfying answer by looking in the direction of entropy, as entropy is defined as the expected log probabilities of a distribution. Since the KL is interlinked tightly with entropy, something may drop out there which will show that logging the ratio makes the expression more natural and intuitive. I'd have to think bout it more, and maybe I'll make a video on entropy in the near future, but if I figure anything out I'll get back to you then.
@@adianliusie590 wow that’s such a great answer. I truly appreciate that! And yeah, what you said makes sense, and with regards to entropy you’re very right; since entropy is the expected/avg information of a distribution of random events and KL div measures the *relative* difference in expected information between two distributions.
Hi Darkev and Adian, there is another video on youtube (study squad academy) which explains the KL divergence from the perspective of Jensen's inequality. The main argument for taking the log is that it is a concave function, which does somewhat touch Adian's comment.
@@Marcus-ok2jy nH and nT are just the number of heads and tails generated in the sequence by the 'true coin', not by coin 2.. i.e., if i have a true coin and I flip it a few times I may get H,H,T,H (nH=3, nT=1) and you will notice that nH/N=0.75 and nT/N =0.25 which is not equal to p1 and p2 respectively. However, if were to flip the coin many more times, infinitely more times, we would notice the number of heads is the same as the number of tails. Thus, he is saying in the limit of a sufficient amount of coin flips, we will notice nH/N = 0.5 and nT/N = 0.5.
@@Drewbie_T Hi Andrew, But in 3:21 , the formula P(observations|coin 2) looks at the nH and nT of Coin 2 does it not? This is so that the KL divergence could take into the account the disparity in probability distribution between the 2 coins.
@@Marcus-ok2jy No it does not, it is only looking at nH and nT of the true coin. Coin 2 is not being flipped at all. The only part where coin 2 comes in is after flipping the true coin (which has probability p1 heads and p2 tails), we obtain some chain of outcomes (i.e., H,H,T,H,T,T). Now that we have flipped the true coin and obtained an outcome, we look at the coin 2 probabilities and say, how likely is it that this sequence (H,H,T,H,T,T) could have come from coin 2? If coin 2 has .95 probability of landing on heads every time, it is unlikely that we would see an equal number of heads and tails in the distribution.
It's because we first flip a coin N times and record the number of heads (nH) and the number of tails (nT). It is assumed here that the coin used here repesents the real coin (which has p1 probability for head and p2 probability for tail). We are now interested in finding how close coin 2 can mimic the real coin's flips. And since the real coin produced nH heads and nT tails during our experiment, we use the same values. Hope this helped.
Thank you! May I ask how you made the video? I want the numbers to move like they do in your show. It looks great and maintains comprehensibility by bringing it to life! We have to make a video about AIC for our neuroinformatics class, so your video would be a nice introduction to the topic anyway... You do it a little better than our prof^^
This might break the magic a bit but I just use plain old fashioned Microsoft power point! To move the equations I use the inbuilt animations functionality, though it can get a bit tedious to make everything move exactly how you’d like to. But best of luck on making your video.
Thanks for the explanation. With the RLHF stuff happening in ChatGPT, does anyone know why they choose to use KL divergence instead of Cross-entropy loss when calculating the RL policy penalty?
The vedio is good, but what confuses me is the correctness of the division. Sometimes,we have different probability(like NH = NT = 1,and p1=q2,p2=q1),but the division result is 1,which mean they are similar ,or same. It is wrong actually. So, may this explanation is just coinstance, or I have made some mistakes. Hopefully you can help me.(If my pool english make it confusing, I am sorry for that)
It allows to factorize by addition rather than multiplication, since the log is a strictly monotonically increasing function. Practically speaking, this is more efficient to compute than a product of terms.
IMO this video gives pretty bad explanation of the essence just hiding by algebraic transformations. Found a much better video that actually explains why we use log() without "believe me or not...": th-cam.com/video/q0AkK8aYbLY/w-d-xo.html





![[Live] : ONE 169 วันนี้!! "อนาโตลี vs อูมาร์"](http://i.ytimg.com/vi/IK3YZVWuFJg/mqdefault.jpg)

![“อ.เบียร์ คนตื่นธรรม” มาตามคำเรียกร้อง แหกศาสตร์ฮวงจุ้ย เตือนสติอย่างมงาย | แฉ 7 พ.ย. 67 [1/3]](http://i.ytimg.com/vi/5fc4S3xBNfc/mqdefault.jpg)

The most intelligent people are the one's who are able to explain the hardest concepts in the most intutive way possible. Thanks.
I just want to say. This is--by far--the best explanation of KL divergence I've found on the internet. Thanks so much!
This was actually one of the most helpful videos. Thank you
Best explanation of the KL divergence in TH-cam for sure....
Thanks...
KL divergence confused me for so long, and I understood it just by watching your video for one time, thank you very much!
holy smoke, you are legit GOAT. so concise yet clear and intuitive explanation.
I'm just rewatching this video to freshen up my deep learning fundamentals. Super clear video, thank you so much!
You are unbelievably good at teaching man. You explained it better than they did in my course.
This type of explanation is perfect! First boiling the problem down to the most intuitive understanding and from there deduce the general formula. Thanks so much!
Perfectly explained in 5 minutes. Wow.
I didn't expect that good explanation from a randomly suggested youtube video
Great explanation! One technical remark I have is that (from my understanding) KL divergence is not technically a measure of distance, since it's not symmetric ( Dlk(P||Q) != Dlk(Q||P) ).
Yes, that's why it's called divergence instead of distance.
Great video! Loved the intuition behind the KL distribution. For some thinking about applications, this is used in the loss function of Variational Auto Encoders, a class of deep networks, and is used to find low dimensionality features of high dimensionality input data as an encoder. (e.g. use this to deconstruct images into "features")
Best explanation on the interwebs!
Bro, this intuition was not normal, u r just genius!!
One of the most useful explanations ever. Thanks!!
Thanks so much for this, needed to understand what KL Divergence is for a paper I'm reading and you just saved me so much time!
Thank you so much for this content. By far the explanation of KL Divergence seen so far
Thanks for the brilliant, intuitive and crystal-clear explanation!
Thanks, that made the idea make a lot more sense to me. Showing how it arises so nicely from a large sample size, made it feel much more natural.
Great video. Thanks for sharing. Really intuitive.
Thanks Adian! The connection back to cross entropy loss is cool. Slowly coming together for me.
A question here why will the number of heads and number of tails be the same for both the distributions at 3:04. If the probabilities for both the coins are different then the number of occurrences of heads and tails can also be different
I think the reason is because we do one experiment where we note the amount of tails and heads. We then assume that the observations are modelled by the probability distribution from the true coin. Now we want to figure out what the probability is that the amount of tails and heads we observed could be coming from coin 2. So the number of tails and heads are the same since they are literally the same, there is only one "measurement" being done.
this was great and super useful in my internship (which really just started), Thanks! :)
thanks a lot ! 5min for explaining what I could'nt understand in hours
This is awesome, thanks for breaking it down Adian
Thanks for the simple, yet helpful, explanation!
Thanks for the explanation!! One thing is, formulas were confusing with how you denoted *q1* & *q2* for probabilities for coin 2, instead of *p2* & *q2=1-p2*
@3:26 I don't understand how are we normalizing by raising it to the power of 1/N. Could you please explain that?
Same question here. This is a fantastic explanation but it defeats me when you mention “we normalize by raising to power of 1/N”. Why do we do this? What does that do or mean to the data? Thanks for making this video! Awesome!
I think the 1/N gives us the 'average' probability of a single toss; e.g. if we had a fair coin and had 3 tosses, the probability of our sequence would be 1/2 * 1/2 * 1/2 = 1/8. If we had ten tosses, the probability of the sequence would be 1/(2^10). These numbers are currently incomparable. If we now look at the probability of the sequence to the power of 1/N, where N is the number of tosses, then suddenly they are the same ... which is what we would want .... it basically normalizes the probability sequence!
@@vyasraina3930 thanks for the explaination! in general why is power 1/N more important than let's say multiplying by 1/N?
@@vyasraina3930 so basically the 1/N gets rid of the number of tosses/sample size and in your case of a fair coin makes it so the probability would be 1/2 regardless of N by getting rid of the N (exponent in your probability sequence)
Thank you so much for this video and clear explanation!
Excellent video. Can someone help me understand why is it called Divergence in the first place? Why are we taking 1/N power to normalise it to sample space, I did not understand the logic behind this.
Great video! Can you make a video about soft actor critic?
Great content! Thank you.
Very well-explained. Thank you!
Nice video! Can you say something about alternatives? E.g. why wouldn't mean squared error (of two probability distributions) work as well?
Wow this is an amazing explanation. So is KL divergence equivalent to Bayes factor with equal priors?
Finally a simple explanation
thx for sharing very helpful and intuitive.
This is so intuitive!!!!!!!!!❤
Very great explanation!
Amazing explanation, thanks!
Thanks for creating this video is awsome
Great Video
excellent explanation
Awesome video, but at 3:27, on what basis did we take the log?
That's a good question which I'm not sure I could answer too well. One could claim that the log function makes numbers more readable, and often when we deal with large/small numbers we log expressions first since the log operation is reversible and squeezes the range into a smaller one (e.g. e^10, about 22000, becomes 10), like is done with things like log probabilities. It could also just be mathematical convenience to drop the powers so that the overall expression looks much simpler.
However I think you'd find a more satisfying answer by looking in the direction of entropy, as entropy is defined as the expected log probabilities of a distribution. Since the KL is interlinked tightly with entropy, something may drop out there which will show that logging the ratio makes the expression more natural and intuitive. I'd have to think bout it more, and maybe I'll make a video on entropy in the near future, but if I figure anything out I'll get back to you then.
@@adianliusie590 wow that’s such a great answer. I truly appreciate that! And yeah, what you said makes sense, and with regards to entropy you’re very right; since entropy is the expected/avg information of a distribution of random events and KL div measures the *relative* difference in expected information between two distributions.
Hi Darkev and Adian, there is another video on youtube (study squad academy) which explains the KL divergence from the perspective of Jensen's inequality. The main argument for taking the log is that it is a concave function, which does somewhat touch Adian's comment.
Useful video.
Concise and clear, thank you!
Very good video. Thanks so much!
thank you so much, very nicely explained
Very well explained! Thank you!
super helpful! Thank you
Great video . Thanks.
Keep the vids coming this is so so useful
This was awesome. Thank you.
Hi, I don't get why you assume that the nH and nT for the coin two would be the same as the coin 1?
Yeah i don't get it either, any explainations anyone?
@@Marcus-ok2jy nH and nT are just the number of heads and tails generated in the sequence by the 'true coin', not by coin 2.. i.e., if i have a true coin and I flip it a few times I may get H,H,T,H (nH=3, nT=1) and you will notice that nH/N=0.75 and nT/N =0.25 which is not equal to p1 and p2 respectively. However, if were to flip the coin many more times, infinitely more times, we would notice the number of heads is the same as the number of tails. Thus, he is saying in the limit of a sufficient amount of coin flips, we will notice nH/N = 0.5 and nT/N = 0.5.
@@Drewbie_T Hi Andrew, But in 3:21 , the formula P(observations|coin 2) looks at the nH and nT of Coin 2 does it not? This is so that the KL divergence could take into the account the disparity in probability distribution between the 2 coins.
@@Marcus-ok2jy No it does not, it is only looking at nH and nT of the true coin. Coin 2 is not being flipped at all. The only part where coin 2 comes in is after flipping the true coin (which has probability p1 heads and p2 tails), we obtain some chain of outcomes (i.e., H,H,T,H,T,T). Now that we have flipped the true coin and obtained an outcome, we look at the coin 2 probabilities and say, how likely is it that this sequence (H,H,T,H,T,T) could have come from coin 2? If coin 2 has .95 probability of landing on heads every time, it is unlikely that we would see an equal number of heads and tails in the distribution.
It's because we first flip a coin N times and record the number of heads (nH) and the number of tails (nT). It is assumed here that the coin used here repesents the real coin (which has p1 probability for head and p2 probability for tail). We are now interested in finding how close coin 2 can mimic the real coin's flips. And since the real coin produced nH heads and nT tails during our experiment, we use the same values.
Hope this helped.
Thank you!
May I ask how you made the video?
I want the numbers to move like they do in your show.
It looks great and maintains comprehensibility by bringing it to life!
We have to make a video about AIC for our neuroinformatics class, so your video would be a nice introduction to the topic anyway...
You do it a little better than our prof^^
This might break the magic a bit but I just use plain old fashioned Microsoft power point! To move the equations I use the inbuilt animations functionality, though it can get a bit tedious to make everything move exactly how you’d like to. But best of luck on making your video.
@@adianliusie590 thx for your answer! Good to know. It doesn't break the magic. I just use another program and I am a noob at some points
This was very good have liked and subscribed
Thanks for the explanation. With the RLHF stuff happening in ChatGPT, does anyone know why they choose to use KL divergence instead of Cross-entropy loss when calculating the RL policy penalty?
Just perfect!
Dude just plops in some God-tier eye openers in the credits and leaves. Never realized this relationship between KL and cross-entropy loss.
Only that is not a distance ('cause is not symmetric), but a pseudo distance. Great video!
This is gold!
Excellent!!!
This video is amazing
Thank you!
So a Kale Divergence of zero means identical distributions? What do the || lines mean?
beautiful!
The vedio is good, but what confuses me is the correctness of the division. Sometimes,we have different probability(like NH = NT = 1,and p1=q2,p2=q1),but the division result is 1,which mean they are similar ,or same. It is wrong actually. So, may this explanation is just coinstance, or I have made some mistakes. Hopefully you can help me.(If my pool english make it confusing, I am sorry for that)
Thanks very much.
...tremendous!
Greaaaat job
Thank you so much
KL loss is not exactly equivalent to cross entropy loss right
Why raise to 1/n power, why use log? Why don't we use just sum(P/Q)?
😁😁😁gotcha. super ez explanation
Awesome
So fire
Nice video :)
So, Why is KL Divergence is not symmetric?
great explanation, would be perfect if you speaked slower
I love you Biradr
when you say "likelyhood of the observation of each coin", you really mean "probability" instead of "likelyhood", right?
I still dont know why the log appears there.
It allows to factorize by addition rather than multiplication, since the log is a strictly monotonically increasing function. Practically speaking, this is more efficient to compute than a product of terms.
It has my initials
nice
It is not a measure of distance between distributions!
wowowowo
It’s technically not “distance”
IMO this video gives pretty bad explanation of the essence just hiding by algebraic transformations. Found a much better video that actually explains why we use log() without "believe me or not...": th-cam.com/video/q0AkK8aYbLY/w-d-xo.html
Great explanation. Thank you so much!
Beautiful explanation!
Thanks so much
Thank you a lot