I second that, excellent explanation. And the example at the end is extremely clarifying, it's easy to get lost in algebra without actually understanding the core graphical, numerical and statistical intuition.
I'm doing my master's thesis on the applications of AI in Architecture. Having no significant mathematic training since high school, this video was absolutly invaluable for a math-illiterate like me to gain a deeper insight the mechanism behind a VAE. Excellently explained. 10/10
I guess a typo at 19.52 that original VI target is argmin( KL(q(z) || p(z|D ))) but it was written p(z,D). Actually p(z,D) is the one we end-up using in ELBO. This can be used to summarize the approach here "ELBO: Well we dont have p(z|D) so instead lets use something we have which is p(z,D) but... Lets show that this is reasonable thing to do"
Errata: (Thanks to everyone commenting and spotting the errors :) ) Error at 15:42 : p(D) as well as log p(D) correspond to the evidence. Evidence is just the marginal probability evaluated at the (observed) data. Hence, it is incorrect to say it becomes the evidence after applying the logarithm. Thanks to @D. Rafaeli for pointing this out (see also his comment) Error at 19:20 : I say that we found the posterior if the ELBO was equal to zero. This is not correct. We would have found the exact posterior, if the ELBO was equal to the (log) evidence, because then the KL is zero which is the divergence measure between the surrogate and the truth. Thanks to @Dave of Winchester for pointing this out. Also see his comment for more details. Error at 19:50 : I wrongly write down the joint p(Z, D), but I mean (and also say) the posterior, i.e. p(Z | D) Error at 22:28 : Correct would be maximizing the ELBO and minimizing the KL, but it should be clear based on the context
Hey @@ArunKumar-fv6uw, unfortunately, I don't have it hosted somewhere. There are only a limited number of plots I can host with streamlit. I am in contact with them to increase this. I will update this thread in case I can get more plots. Until then, you can do the following: 1) Download the following script from the GitHub Repo of the channel: github.com/Ceyron/machine-learning-and-simulation/blob/main/english/probabilistic_machine_learning/elbo_interactive_plot.py 2) In a Python environment, install the following packages: "streamlit", "tensorflow", "tensorflow-probability" and "plotly" 3) In a Terminal, navigate to the folder you saved the file in and then call "streamlit run elbo_interactive_plot.py" which should automatically open a web-browser and display the interactive plot. Let me know if you run into problems with this approach :)
@@ArunKumar-fv6uw I got it working. Here is the link: share.streamlit.io/ceyron/machine-learning-and-simulation/main/english/probabilistic_machine_learning/elbo_interactive_plot.py
i love you man, i have literally spent 20+ hours to understand this. most of the explanations i found are so hand wavy, thank you so much for spending so much time yourself to understand this and then to make this video
You're very welcome! 😊 I'm happy it was helpful. Feel free to share it with friends and colleagues. You might also find the follow up videos in the VI playlist helpful: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Thank you so much! Your explanation is so clear and easy to follow, as opposed to other videos and blogs which either shy away from the derivation or user phrases like 'by simple calculus' to jump straight to the expression
Around the middle of the video, I gave a like. Towards the end of it, I had no choice but to take my like back... because I needed to like the video again!!
The video is very nicely organized, I would like to point out to the author and audience that KL divergence is not a distance as it is not symmetric, that's why it is called divergence and not KL distance
Great lecture as always. In the context of your camera and image scenario 1:57, I'm struggling to understand why you mention "we have the joint P(Z, D)". If Z is latent, e.g., camera angle, and we have no measurements for it, how do we know the joint P(Z, D)?
Thanks for the kind feedback 😊 That was a common remark so I created a follow-up Video to hopeful answer this question: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html You might also find other video's of the channel on VI helpful. There is a playlist (should find it on the channel site). 😊
Around 19:20 you talk about the "computable" item which is the ELBO and then mention that when "it" is zero, we have "found the posterior." I think you mean, if the KL divergence is zero, then the approximation is perfect and we have found the posterior. But we are not optimizing the KL divergence directly, rather we are optimizing it indirectly through the ELBO. This is possible because: KL = -ELBO - log(p(D))] Since KL must be 0 or greater, the ELBO will, at its theoretical optimum, take the same value as the evidence log p(D), not zero. (unless p(D) = 1.) This may well be what you meant, but I figured I'd write this out for anyone else who might interpret it incorrectly.
Yes, you are absolutely correct :). It should be that we found the posterior, if the ELBO equals the evidence as then the KL would be zero. Thanks for noticing, I will add it to the pinned errata comment.
Thanks for this video. I used to watch Panda (those cute furry bears) videos to relax my mind before starting on some complex task but today I watched this video
Haha :D Amazing comment. It's great to hear that my video can also be relaxing. Feel free to leave a link to a nice Panda video here, I would also be interested in relaxing.
Going to point A to point B is the same as going from point B to point A, hence we call this distance. In KL-divergence, it is not the case. Therefore, we should be mindful to note that the KL-divergence is not truly a distance metric as the KL-divergence for a distribution q with respect to p is not equal to the KL-divergence for a distribution p with respect to q.
Sure, the KL divergence does not fulfill all axioms of a distance metric, still I think it is a valid conceptual introduction to compare it with one. :)
Thank you for the clearest explanation of Variational Inference I've seen yet. If I were to apply the concepts of this video to neural networks, would z be the activation state of hidden neurons, or would z be their weights? In graphical models, z is the value of the unobserved node in the graph, and in neural networks the value of a node is its activation. But I think that in KLD and ELBO z would be weights because we want to learn (infer) weights in neural networks, right?
Thanks for your feedback, :) I think you are referring to Bayesian Neural Networks, if I am not mistaken? If so, then you are correct, Z would correspond to the weights in the Neural Networks. In a supervised learning problem in a Neural Network, you have some inputs X and outputs Y, as well as unknown (hidden/latent) weights Z of the networks. The activations of the hidden neurons are some deterministic computations (at least in the classical form of Bayesian Neural Networks) and therefore do not have a random distribution associated with them. Putting this back together in the Variational Inference Framework: You can observe the inputs and outputs (hence the X and Y of the NN make up the X in the video), but you do not observe the weights of the Neural Network (hence they make up the Z in the video). Let me know if that helped, :) I can also elaborate more if needed.
I think neural networks blurs the line between observed and unobserved variables. It's true that we cannot observe the IDEAL weights that would produce accurate task results, but we can observe the weights themselves because we set those weight values ourselves. Nevertheless, I see the point that weights play the role of the "unobserved" target of inference.
Great great talk. One question, one thing I am struggling to understand with VI or ELBO in general: - Say we have typical classif. problem and minimize cross entropy, we are in fact doing Min(KL(truth, estimate)) where the truth is the true labels of data. (I assume same goes for regression problems in a sense minimizing the RMSE does this) - Why then in VI approach we switch them around from the start? I.e. we are doing Min[KL(estimate, truth)] and what is the interpretation of this? In short: Min[KL(p, q)] - traditionally Min[KL(q,p)] - in VI why? how ? what? does this all mean? Amazing talk and thanks in advance for your time :)
Thanks for the interesting comment 😊 It's a great question. Unfortunately, I do not have a good answer. You could also frame a VI problem the other way around (which would of course be a different optimization due to the KL being non-symmetric). I would have to think about it further, but I'm unsure whether we would end up at sth like the ELBO if we had it the other way around.
@@MachineLearningSimulation Am I seeing it right though? Is VI problem Min(KL(estimate, truth)) and the traditional say classification problem is Min(KL(truth, estimate)) ?
Hello again... I wonder if you have ever had the chance to look into the Generalised Coordinates of motion! The goal of VI in there, is to not only infer the expected value of the hidden state, but also infer hier temporal derivatives of it (e.g., velocity, acceleration, jerk, etc.). In particular, in highly dynamic systems, this can help us track the expected value of the hidden states much better (i.e., keeping up with the dynamics while trying to do VI). This would be an AMAZING idea for a video.
Hi this was the most epic explanation I've ever seen, thank you! My question is that at ~14:25, you swap the numerator and denominator in the first term -- why did you do this swap?
Great video on explaining even the math concepts, but I stood with a doubt, perhaps a stupid one: In the beggining of the video you had the blue line p(Z|D) = probability of the latent variable Z knowing D data, so events Z and D are not independent right? If I understood correctly, then, at 10:20, you say that we have the joint probability P(Z *intersect* D). I don't think I understood this: how do we know we have that intersect? Is it explained in any prior minute...? Thank you for your attention
You're very welcome :). This was a common question, so I created a follow-up video: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html . You might also be interested in the entire VI playlist (including examples etc.): th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Awesome explanation of Variational Inference. Kudos. Just one comment. At 22:27 you state task is to minimize the ELBO and maximize the KL divergence. Should'nt this be the reverse. Minimize KL divergence and maximize ELBO
You're very welcome 😊 You are absolutely right, it should be the other way around. I already collected that error in the pinned comment under the video 👍
@@MachineLearningSimulation Sorry I missed it :-) . Thanks again for this awesome explanation. If possible can you also explain diffusion networks as they also rely on Variational inference and similar concepts.
No worries 😊 The comment section is already quite full under this video. Yes, long term goal is to also cover different deep generative Models like normalizing flows or diffusion models. Unfortunately, I cannot give a time estimate, though. Maybe around begining of next year, depends a bit on where my interests evolve :D
Nice video. Terminology wise, note that the "evidence" is simply P(X) (or P(D) in your notation). You don't call it evidence only after taking the log. The ELBO is actually the (log) Evidence Lower Bound.
Thank you! :) Btw: You can also find the visualization online to play around with it: share.streamlit.io/ceyron/machine-learning-and-simulation/main/english/probabilistic_machine_learning/elbo_interactive_plot.py
Hello, thank you for the video. In your example you said we have observed X as a dataset (X=D). 1- Does that translate to us having p(X=D|Z)? 2- If so, then why does it not translate to us having the marginal p(X=D)? 3- Later in the video you say we have p(D), but earlier it was stated we don't have p(X=D), so what is the difference between p(D) and p(X=D)? Thank you
Hi, thanks for the comment. :) Regarding your first and second question: I think that's a common misconception. Check out this follow-up video for more details: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html For the third: do have a time stamp for the point in the video? It's been some time since I uploaded it 😅
First thank you for all your videos, you already helped me so much! I have a question though: in 20:00 you said that q*(z) = argmax (L(q)) but shouldn't L(q) be smaller here? Because in the KL we have: KL = - L(q) + log p(D) A larger L(q) will become negative, log p(D) is negative, so KL will be negative here too right? Let's say we maximize L(q) and get a value of 1000 and log p(D) = -900 This gives us: KL = -(1000) + (-900) = -1900 < 0 Shouldn't we instead minimize L(q)? Or am I out of the loop (which I think is more likely) ?
Thanks for the comment, :) It's great that you put in the thoughts and critically interpret the video's contents. That helps a lot in understanding the content (at least for me, this was a good learning strategy). Regarding your question: You have a small misconception here. The Evidence-Lower-Bound is a term that is smaller than the evidence (in the video I say it is always negative, which is technically not correct, but in almost all real-world cases it will be a value smaller than zero, hence let's say it is negative). Since the evidence is negative, let's take your example with log p(D) = -900, the ELBO will always be smaller equal to that (making it a lower bound, if it were bigger than the evidence, it would no longer be that bound from below). Since we have the classical "smaller equal" sign (
One more thought: When one looks at the documentation of TensorFlow Probability (www.tensorflow.org/probability/api_docs/python/tfp/vi/fit_surrogate_posterior ), one might think the ELBO is a positive quantity. However, in this case, they are working with the negative ELBO. The reason for this is that this changes the optimization problem from maximization to minimization, which is more standard in the optimization community, though both optimization problems are identical. I also mention this in the video on Variational Inference in TensorFlow Probability (th-cam.com/video/dxwVMeK988Y/w-d-xo.html )
@@MachineLearningSimulation It's all super clear now, thanks! I have to says that I was quite tired when I watched the video. Taking a couple days off really helped me out. Your answer was the cherry on the top!
Amazing explanation!! I have a doubt though, How do we find the joint? You kind of said that we have access to the functional form of the joint because we have the directed graphical model but, I do not understand what you mean by that. Can you please elaborate a bit perhaps with a toy example?
Thanks a lot 😊 You probably find what you are looking for in one of the follow up videos: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Thank you so much for the awesome explanations! I was wondering, when you show the interactive ELBO plot, with computed ELBO, KL, and evidence values -- where does evidence come from, i.e. didn't we say that we don't have access to that marginal probability in the beginning..?
Hey, thanks for the feedback :) I appreciate it a lot. That's a great observation. Indeed, in most real-world scenario, we would be unable to obtain the value for the evidence. Here, I just arbitrarily selected one. If you take a look at the source-code of the visualization (if you ignore my terrible typos there for a moment :D ) at line 123 I picked the smallest KL value and put a negative sign in front. However, I could have also just said -40.0 or any other negative value. Maybe as an interesting side-note: the evidence gets smaller the more complex the models are and the more samples we have in a dataset. That is because observing the data in that particular way through that particular model will just become very unlikely then.
Hello, Thanks a lot for your video, I have 2 questions. - In 3:42 you mentioned marginal (p(x=D)) is the problem. Why this constant is important? can you illustrate it by an example? -In 10:29 you mentioned that we have the joint distribution but not the posterior. can you please example a graphical model to enlighten it? Many thanks
Hey, thanks for the comment :) And also the time stamps, that helps. It's been some time now since I uploaded the video :D Regarding your questions: 1) I can understand confusion. It might not seem that hard in the first place, but the constant is crucial in order to have a proper probability density function. We can already the query the posterior p(Z | X=D) in terms of its proportional, i.e., p(Z | X = D) ~ p(Z) p(X=D | Z). Consider the example of a Gaussian Mixture Model (and ignore for now that this simple model has an analytic posterior). Here, X are the positions in feature space and Z is the corresponding class. Assume we observed data D, and want to know how probable it is that the datapoints belong to a specific combination of classes, e.g., all samples were from class 0. Then we could not use the proportional posterior (which, in essence, is just the joint distribution) to assess this probability. The only task we could use it for is to say, which of two combinations of classes are more probable. For example, say Z^[1] = [0, 1, 1, 2] and Z^[2] = [1,1, 0, 1]. Then the proportional posterior (alias the joint) spits out two values and whichever value is higher indicates a more probable class association. However, we can't say whether its probability is low or high (in a global context), since it is unnormalized. Worse even, we can't say which class is the most probable, i.e., we could not optimize over Z. This is something we could be interested in (and are in case of inference). So, the marginal in the denominator is crucial. Next question: Why is it hard to obtain: Maybe a counter-question: What is the integral of e^(sin^2(x³) - x²) dx? I just made that up, but most certainly this is a function that does not have a closed-form integral. The challenge is that marginalization means an integral (in case of continuous random variables) or a sum (in case of discrete random variables) which is intractable. A loose definition for intractable could be: We are unable to exactly/analytically compute it with available resources. 2) There was a similar question before. Maybe scroll down to the comment of @C. The bottom line is that, whenever we have a Directed Graphical Model, which is kind of the basis of every probabilistic investigation (e.g. for Linear Regression, GMMs, Hidden Markov Models etc.), we also know its joint by means of factorization (th-cam.com/video/yBc01ZeaFxw/w-d-xo.html ). I understand that this is confusing and might need an example. Also, I promised one in the aforementioned comment, but haven't had the time yet. Hopefully, I can do it in the next months :) Let me know if sth is unclear. :)
Hey, I just released a follow-up video, which might answer some of your questions: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html There will also be more VI videos (including Variational Autoencoders) in the future.
Great Explanation, thank you for posting! Do you know any channel/video that shows a very simple case of mathematically tractable Bayesian inference and calculate the marginal distribution by integration? I'd love to see that. Keep up the great work.
Hey, thanks for commenting and all the kind words :) I have something in that regard on the channel: Is that (th-cam.com/video/SEwvipQaNvk/w-d-xo.html ) what you are looking for? It also has an accompanying Python implementation: th-cam.com/video/ISZwydaKZNY/w-d-xo.html
omg, the Bayesian thing really bothers me for a long time, and it is the first time I found a video can explain all the confusion and make it clearer and clearer. Thanks so much and really appreciate your work.
I would like first to thank you for these high quality educational videos. Second i would like to excuse me for my dumm questions ! Well how Variational inference is different from fitting a mixture of gaussian, well let me elaborate.. !GMM tries to estimate densities as linear of combination of gaussians distributions, (well i know gaussians is one of the exponential family distributions). so we are restricting the approximations in the GMM to only Gaussians ! well let me dive into my confusions and thoughts. Well at the end PDF is a function that intergrate to 1. So giving enough basis functions let say Gaussians with infinite function space, is not possible theoretically and principally to estimate any distribution ? Well someone would say well ok in GMM you are clustering and you need to predefine the number of clusters, well i would argue since im interested in the whole density and not clustering, i would expand the space of hypothesis such that i can capture all the details and the multimodality of the distribution. Well think of it like you have a large Dictionary of PDFs and the goal is to pick the PDFs and learn its parameters such that the representation with respect to this dictionary is sparse so that you pick the least possible number of functions. One last thing im kind of person who like to imagine and visualize things so im having trouble understanding, "well not understanding" but conceptualizing or imagining or appreciate the probabilistic framework. well when someone say P(X,Y) where X is MNIST and Y are the labels, like for me what does that mean taking multivariate scalar mapping in function of the datapoint and it is label, or P(X,Z) datapoints with its latent variable, well at the end im not really interested in the "scaler of chance" namely the probability. But im going from the spread of the data to learn something about the data itself. i mean why that make sense at all. For instance when i say i have P(X|Y=0) well is a real mathematical function or just my ability to extract the digit 0 from the whole dataset. im really having hard time feeling these terms. I don't have problem with the "mechanical" mathematics at all but i feel im missing something. Sorry if the questions are out of context of the video but i appreciate the response.
Hey, first: also thank you for your warm feedback :) I really appreciate that, and it motivates me a lot to put out these videos. It is even more amazing to see that people like you are actively thinking about the video's contents. I can just say that from my perspective, this is one of the best ways to learn: to watch/read/listen to things critically and come up with questions. Hence, there are no dumb questions and I can totally understand your confusion. This is an advanced and tough topic, with which I also struggled for a long time. Therefore, please feel free to also formulate follow-up questions in case my answer to your points are insufficient. Let me sum up the points from your comment and then answer them individually: 1) Why are GMM not enough to capture complex distributions (even approximately as a surrogate posterior)? What is the need for Variational Inference? 2) How can one think of the X & Z (that I also used in the video)? What do they represent, how could you visualize them? (I did not get your question on the sparse dictionary of PDFs, could you elaborate on that?) Answering your questions (or at least trying to ;) ) 1) Yes, you are correct. In theory, having a mixture of infinite Gaussians should be enough to capture arbitrarily complex (posterior) distributions. Well, probably there are some pathological examples that this does not work in general, but it should be correct for anything practically relevant. The downsides are, that first you could need an unreasonable large number of components in your mixture and second that the training stage may be highly complicated. For the first, think of a distribution in two dimension which density is high on a ring around the origin. You would need many sharply peaked Gaussians in order to well represent the density in the mixture. For Variational Inference, on the other hand, you could just use a clever Normalizing Flow or choose a family of parametric distributions that has this density feature. Of course, this requires some knowledge on the density distribution. For the second, consider training of Gaussian Mixture Models in high dimensions by the EM algorithm, which has quite some difficulties (I also mention some of them in my video on implementing it: th-cam.com/video/rSJifjJid0k/w-d-xo.html ). The higher the dimensions, the more mixture components and the more complicated the data points, the "more non-convex" the optimization will become. Additionally, you will have problems of enforcing the positive definiteness in the covariance matrices. Hence, from this perspective, using GMMs is impracticable. 2) It is the same for me, I like visualizations or at least a way to think of things. Unfortunately, working in this high dimensional spaces is highly complicated. There are many effects that seem unnatural to a human being used to two, three or four dimensions (one example: en.wikipedia.org/wiki/Volume_of_an_n-ball ). Some physicist (I unfortunately do not know of) once said (loose quote): If I have to visualize a 27-dimensional space, I draw it three-dimensional and say 27 in my head. (Maybe you have a link to the true quote). But back to your questions: MNIST might be a bit misleading, because it is usually used for supervised learning (we know images and labels during training and the latent variables are the parameters/weights of our model, whereas in classical Machine Learning they are not considered probabilistic, hence latent might be a bit confusing). However, for the sake of working in high-dimensional spaces, let's take MNIST anyway. X is an image and in the case of MNIST consists of 28x28 pixels with a grayscale value. One could therefore view an image as a 768-dimensional vector with coordinates that are in the range from 0 to 1 in all its axes. Now, we have a bunch of images. Hence, there many 768-dimensional points. For each point we additionally have an (observed during training) label. The points adhere to some structure in this high dimensional, or have a certain density, that we want to capture with our distribution.......
You're very welcome 🤗 (I'm not a professor though ;) ) I assume you refer to the visualization at the end of the video? This value I chose arbitrarily, sind it depends on the dataset, which is never talked about in this example.
Hats off to you indeed. However, I am confused about KL being always positive @16:37. If q(z)=p(x,z), then the results is KL = 0 + log(p(x)) < 0. what is the thing that I am missing here? Thanks in advance
I searched it and I come up with a conclusion. In math, it is proved that KL>=0. Hence, the loss should be always >=0. Accordingly, we have to restrict q(z) so that it become Not equal to p(x,z). Therefore, L(q) should be bounded by lp(x) (i.e., L(x) belong to the following range [p(x),inf).
Hi, thanks for the comment :). It seems like you clarified it for yourself. There are some points, that are not fully correct yet. Indeed, what you showed is that the loss is a lower bound to the log-evidence, i.e., L(q) in (-inf, log(p(D))) [note the log and the minus in front of infinity, you do not have this in your comment] . Hence, also the name: Evidence-lower-bound (ELBO). As a consequence, it would also be fine if q(z) == p(D, z), as our lower bound would then be tight and the KL was zero. You said that it is proven that KL>=0. This is not fully correct. Actually, it is one of the axioms of any divergence (or a distance) to be greater equal 0.
What software are you using for the "blackboard"? You (as well as people like William Spaniel and Khan Academy) really inspired me to do teaching myself
Appreciate it 😊 Khan Academy was also a big inspiration for me. I use Xournal++, in parts also because it works nicely with Wacom tablets under Linux. You need to do some small adjustments to the settings to get a back background.
@@MachineLearningSimulation Big thanks! May I ask do you have any video/video series discussing EM algorithm? Most resources I've read only explain its application for one specific use case such as in Gaussian Mixture Model.
These are the videos I have on the EM algorithm: 🔢 Expectation Maximization Algorithm | with implementation in TensorFlow Probability: th-cam.com/play/PLISXH-iEM4JnNy8UqOBsjW6Uf-ot1RoYb.html
Thank you for a great video! One thing I missed was why you chose KL[q(z)||p(z|D)] and not the other way around KL[p(z|D)||q(z)]. My guess is that the former optimizes q(z) to avoid results that are unlikely according to p(z|D) at the expense of possibly capturing only a subset of it. The latter would try to represent all of p(z|D), but potentially give us many unrealistic results, and this is not what we want. Could you please delve into this topic and clarify your choice of the metric?
[edit: please read the thread all the way to the end. I made some stupid mistakes and wrong claims in my first replies. Thanks to Dmitry for pointing them out] [edit: I wrongly noted down the KL expansion in terms of cross entropy and entropy and corrected it later on] Hey, thanks for the great question and the nice feedback 😊 Using the KL the other way around is also sometimes done and usually referred to as expectation propagation (en.m.wikipedia.org/wiki/Expectation_propagation). Your interpretation is definitely also a way to view it. Maybe also view the KL in terms of the entropy. If you slice up the KL definition of KL(q||p) you get H(q, p) - H(p) which is the cross entropy between the two distributions minus the entropy of the p distribution. If you were considering the KL the other way around, you would get the entropy of q, H(q) which is not really relevant for variational inference. The goal of VI is to find the distribution the closest to the actual posterior and not one that additionally has optimal entropy. Maybe that shines some additional light on it 😊. It is probably not the most intuitive interpretation. Let me know what you think
@@MachineLearningSimulation Thank you for your reply! I am still a bit confused. If I start with the definition, the Kullback-Leibler divergence KL(q||p) is the penalty for using the distribution p with the reference probability is q; in other words, the average number of bits assuming the distribution p minus the average number of bits when using the actual underlying distribution q, i.e. H(q,p) - H(q,q), where, obviously, H(q,q)=H(q). Thus, I have KL(q||p)=H(q,p)-H(q). What did you do to get H(q,p)+H(p)?
Yes, you are of course correct. Writing out the KL gives KL(q||p) = H(q, p) - H(p). I was replying on mobile and did the math in head, not the best idea :D (I will edit my first reply). Then we get the two ways: KL(q||p) = H(q,p) - H(p) KL(p||q) = H(p,q) - H(q) If we know want to minimize the KL for a variational approach, my point of view (maybe not the best though) would be that with the second approach we could potentially fit a surrogate posterior q that is less optimal in terms of how close it is to the true posterior, since we could just select a surrogate with a high entropy that would then lower our total KL. Whereas in the first approach the H(p) is just a constant we do not have to consider for the optimization. I hope this makes it clearer. Let me know if there is still some confusion left 😊
That's right. I made another mistake, sorry for that. Correct should be as you said that KL(q||p) = H(q, p) - H(q) and KL(p||q) = H(p, q) - H(p) Then my initial answer is of course nonsense. (I will edit it again and leave a note to read the thread all the way till the end). So then judging by this interpretation, one could argue (actually the opposite) that it is desirable to have a high entropy solution to the optimization problem. Because when using former way of the KL we choose a solution that minimizes the discrepancy to the actual posterior and is optimally in its highest entropy (something one could wish for in analogy to some distributions arising from a maximum entropy principle). The latter form of the KL would then just try optimize the discrepancy between the two distributions and just has a constant offset H(p) that can be ignored in the optimization process over q. I hope that is now right. Please correct me, in case I made another mistake. Again my sincerest apology for the confusion. I didn't have a piece a paper while replying from mobile.
First of all, thanks for the great explaination. I still have a few questions. At the moment i am trying to understand the Inference of Latent Dirchichlet Allocation. In the original Paper they also use Variational Inference. It is often stated that in Bayes Theorem the joint/likelihood p(z, d) and the prior p(z) are given. But don´t these also depend on the hidden variables z? I thought the main goal of Inference is to find z. Do you optimize z with the alternative distribution q until it terminates and then put the final z into your original distribution p?
Thank you very much for the comment and the kind words :) I must admit, I haven't worked with LDA yet - so far I only read the paper. However, I think that your question is similar to a comment from 6 months ago asked by @C . The confusion you probably have is that hidden or latent does not mean non-computable. The problem Variational Inference tries to overcome is that in a lot of realistic applications (including LDA) the posterior p(Z | D) is intractable, meaning that in order to analytically evaluate it you might have to do computations that are impossible. That is because they involve an exponential number of operations (e.g., extremely nested sums when marginalizing over high-dimensional discrete random vectors) or solving integrals for which there are no closed form solutions. And in order to approximate the posterior with any means (not just VI but also MCMC) you evaluate the joint distribution, aka the product of prior and likelihood. Maybe think of it like optimizing a function. Imagine you want to optimize f(x) = x^2 and assume it would be impossible to find an analytical optimum to it. Now there are algorithms that (iteratively) find an approximate solution to the optimum, i.e. an x-value that is maybe not exactly 0 (which would be the true optimum) but is 0.1. In order to do so, they evaluate the function a couple of times, e.g. f(2.0) = 4.0 or f(-3.0) = 9.0. Back to probability theory: we want something (optimum -> posterior) which we cannot get exactly. Therefore, we use an algorithm to obtain an approximation to the true solution. This algorithm has to evaluate something (target function in optimization -> joint distribution). I hope that helped :) Let me know if sth is still unclear.
I want to say that in most ELBO problems it is really hard to calculate the only way to bypass this problem is just to use the given pseudocode and do the EM
Hey, probably that was not fully clear in the video, but Variational Inference and the EM algorithm are identical IF the posterior is tractable (and reasonable to compute). I plan to do a video on that. However, for most applications (like Variational Autoencoders) the posterior is not tractable, which is the reason we either have to use sampling strategies (like MCMC) or Variational Inference like presented here.
@@MachineLearningSimulation MCMC is too slow for topics like LDA and I am doing Bayesian GMM It is killing me X( ashkush.medium.com/variational-inference-gaussian-mixture-model-52595074247b even EM is always stuck and very hard to calculate the ELBO like Skewers but it's still very efficient in big data
@@ccuuttww Okay, that's probably quite problem dependent. I would say that performing inference in any reasonably complex probabilistic model will always be difficult. Something interesting to read is also (www.fz-juelich.de/SharedDocs/Pressemitteilungen/UK/EN/2020/2020-09-21-covid19-bstim.html) where German HPC researchers developped a Covid Pandemic Prediction Model using Bayesian Networks / Directed Graphical for which training took > 100'000 GPU hours and daily inference takes 1'000 GPU hours. One can query the prediction results on covid19-bayesian.fz-juelich.de/ - unfortunately only in German.
Really good video. Thank you very much. However just to make sure I understand correctly. Our objective is argmax L(q) function, but same time L(q) will always be smaller than log(p(D)) right?
Hi, thanks for the comment :) You're very welcome. You are correct. The ELBO is bounding the evidence from below. Our objective is to come as close to the evidence as possible. Only in synthetic scenarios (with closed-form posterior) we are able to converge against the evidence log(p(D)).
7:04 we replace conditional distribution p(z l x) by some approximate function q(z). But it means that we now assume that z and x independent, since the probabilities of z doesn’t depend on x now. Is it really this way?
Hi Yury, thanks for the great question. I can understand the confusion ;) Actually, both approaches are possible. You can have surrogate posterior that are "some form of a mapping" like q(Z|X) or the independent one as shown in the video q(Z). The reason, the latter works just fine is that in the ELBO, you have all dependency on X fixed to the (observed) data. Consequentially, the q(Z) you find can have no dependency on X . Obviously, the surrogate posterior q(Z) will be different for different data. If you proposed the distribution for q(Z) like a Normal and just optimized its parameters, those would most likely turn out to be different for different data values. Imagine it like this: if you had the true posterior p(Z|X) and wanted to evaluate it for some data D, you would fix it p(Z|X=D) which gives you a distribution over Z only. That's what a q(Z) shall represent. Hence, if you change your data for some reason you have to run the ELBO optimization (i.e. Variational Inference) again to obtain another q(Z) as what you'd get for plugging in D_2 into the hypothetical true posterior, i.e. p(Z|X=D_2). If you were to do Variational Inference for a q(Z|X), you would only have to do that once and could then use "like the true posterior". That might raise the question, we consider the case q(Z) in the first place? I believe that greatly depends on the modeling task. I only have some anecdotal evidence, but the optimization for q(Z) instead of q(Z|X) is often "easier". Btw: You find the approach with a q(Z|X) surrogate posterior in Variational Autoencoders. I hope that shined some more light on it :). Let me know if sth is still unclear and feel free to ask a follow-up question.
oops, sorry. I miss out the notation p(D, z') is p(D | z') * p(z'). But another question, shouldn't the p(z', D) be p(D, z') since your posterior is p(z' | D)
Hey, sorry for the late reply. Somehow, your comment got wrongly tagged as Spam by TH-cam and I had to manually accept it :D Regarding your initial question: You already correctly figured that one out. The joint distribution p(D, Z) is equal to the likelihood times the prior, p(D, Z) = p(D | Z) * p(Z). In other words, at the mentioned point in the video, I use this "simplified form of Bayes' Rule". Regarding your follow-up question: For joint distributions, the order of the arguments does not matter. Hence, p(Z, D) and p(D, Z) are equally fine. You can pick whatever suits you best and depending on the literature you read, you might see people using these formats interchangeably. :) But of course take care, that in conditional distributions the order matters (at least the order of what is before the "|" and after the "|") I hope that answered your question :) Please let me know if there is still something unclear.
I haven't understood why we have access to the joint but not to the prior over the data. It appears a little unintuitive to me. Maybe someone could explain?
Sure, this was a popular demand, so I created a follow-up video dedicated to some open points of this video (including the one you brought up): th-cam.com/video/gV1NWMiiAEI/w-d-xo.html Enjoy 😉
In your video on Calculus of Variations, the Variational approach was characterized by the use of the Gateaux derivative. In this video, I don't see any mention of Gateaux derivative (or Euler Lagrange). Shouldn't a method that's named "Variational Inference" build on top of the Calculus of Variations, Gateaux derivative, or Euler-Lagrange? Or does the mere fact of trying to minimize a functional enough to qualify the method in this video to earn "Variational" in its name?
Hey, that's a fantastic question! Indeed, it is rather unintuitive that this does not appear here. The main result of variational inference was that you want the surrogate posterior as the arg maximum of the ELBO. This is a variational optimization problem, because you are seeking a function, i.e. a distribution - the surrogate posterior -, that maximizes the ELBO functional. Hence, the ELBO is a functional:, if you insert different distributions like normal, gamma or beta etc. the ELBO value differs (although here you would need distributions with the same support). Therefore, theoretically you could apply the functional derivative and find a maximizing surrogate posterior. Also check out my video on the mean field approach, where we do this. th-cam.com/video/_iNajZR6jY4/w-d-xo.html However, and that's the major point: in almost all practically relevant problems, there is no closed form maximizing posterior, i.e. you won't be able to find a distribution. Therefore, in order to make the optimization practical one proposes a parametric family of distributions (like a normal distribution with learnable mean and variance, or a distribution for which its parameters are given by trainable neural networks). Then we move from optimization in (infinite dimensional) function spaces to finite dimensional vector spaces (the space of parameters). And therefore you don't see the gâteaux derivative. Please let me know if that helped 😊. And please ask follow-up questions if you have any.
Thank you for the clarification. I had to think about it for some time. I would also like to add this quote from Wikipedia's article on Variational Inference: It can be shown using the calculus of variations (hence the name "variational Bayes") that the "best" distribution q*_i can be expressed as I believe that q*_i is the surrogate distribution. If this is the case then the next step is to follow the reference cited -- Lee, Se Yoon (2021). "Gibbs sampler and coordinate ascent variational inference: A set-theoretical review"
Hi, that was a common remark among the viewers of the video. By "access to", I mean that we can query the joint probability for any values. In other words, we have its computational form. This is not true for the exact posterior. To lift that confusion, I created a follow-up video. Check it out here: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html . You can also find some hands-on details in the video with the exponential-normal model: th-cam.com/video/u4BJdBCDR9w/w-d-xo.html
Great video! =) Can somebody please explain why we have the joint distribution and why don't have the posterior? I understand that we have some dataset D (images) and maybe we even have their ground truth data Z (like categories, cat, dog, etc..). Does this automatically mean that we have the joint distribution?
At about 2:00 you say that we have access to the joint distribution p(x, z) since we have a directed graphical model. Why exactly is this the case? When you talk about a DGM, do you refer to something like a Bayes Net, where a node x' is reliant on its parents, Parents(x')? Edit: Oh I just saw the discussion below with @C, that clears it up!
@@MachineLearningSimulation Wait actually on further reflection I realize I still don't quite get it haha! So in the thread below, you said "You can also think of it the following way: if I propose a Z. For instance let Z be only a scalar and I say Z=2.0 . Then you can calculate the probability of p(Z=2.0, X=D) (you additionally observed the X values to be the data D). However, in the scenarios we are looking at with Variational Inference you cannot calculate p(Z=2.0 | X=D) because there is no (closed-form) functional form of the posterior". How can you compute p(Z=2, X=D)? Like if we are considering a VAE where the latent dimension is just 1D, how would we compute p(Z=2, X=D)? Wouldn't we have to know something about the prior distribution of the data (i.e. p(X=D))?
@@addisonweatherhead2790 Sure, no problem, :) It's a tough topic. To elaborate on one part of my previous answer: "That is, because we know the factorization of it." In the case of the simple model p(Z, X), let this factorize according to p(Z, X) = p(Z) * p(X|Z), then the graph would look like (Z)->(X) . If you now want to query p(Z=2, X=8) (here I also made X a scalar), then you would have to evaluate p(Z=2, X=8) = p(Z=2) * p(X=8 | Z=2) and you can do this because you modeled the distribution of p(Z) and p(X|Z) (for example in the Gaussian Mixture Model as Categorical and Normal, respectively). Consequentially, we do not need the marginal p(X=D) or the posterior p(Z|X) in order to evaluate the joint. Hence, "we have access to the joint". I hope that provides some more insight :) Let me know.
@@MachineLearningSimulation Just a follow up on this, I'm finally doing a proper probabilistic ML course in school right now, and I'd say this is very relevant / useful background! All too often VI seems to be introduced without properly and very clearly explaining what we have access to, and what we don't have access to, and why. As you mentioned above, maybe just a brief 5-10 min video on latent variable models, and the basic structure they usually have (e.g. one assumes some distribution on the latent variables, p(z)), and the distribution they induce on the observed data (i.e. p(x|z)). That is one of the parts that made VI difficult for me at first!
@@addisonweatherhead2790 Yes, absolutely. ☺ Finally, I am having some more time to focus on the videos and the channel. I don't want to promise a particular time in the future to release this video, but I will try to move it up in my priority list.
Aaaaand how do we know the joint distribution p(X,Z) ? As said X can be an image from our data set and Z can be some feature like "roundness of chin" or "intensity of smiling". It is bit strange to be able to know jointly p(Image, feature) but not being able to know p(Image) because of multi-dimensional integrals
Hi, that referred to us having access to the functional form of the joint distribution. It was a common question in comments so I produced a follow-up video: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html Hope that helps 😃
You're welcome 😊 Yes of course: I use Xournal++. It's an open source software that runs under all major operating systems. And I record the videos (plus audio) with obs, which is also cross platform.
In the case of variational autoencoders, the strategy would be to assume p(z | D) is normally distributed with both fixed mean and variance, and then try to approximate a encoder network q(z) to match this normal distribution?
Almost. The assumptions in the (standard) VAE framework is that the prior over the latent variables (p(Z)) is normally distributed (with zero mean and prescribed variance/std). Then, the goal is to both learn an encoding distribution q(Z|X) and a decoding distribution p(X|Z) (as deep networks). One can show that the ELBO in this setting is both a data match (plugging, for instance, images into the sequence encoder -> decoder and then compare the difference) and a regularization component given by the distance/divergence of the encoding distribution and the prior.
@@MachineLearningSimulation Absolutely fine. Having said that its a very crisp explanation of things. ELBO is a core concept even for Diffusion models so has to be understood clearly.
Good question: I think I was not precise enough. By "we have the joint probability" I mean that we can express the functional form of the joint distribution. That is, because we know the factorization of it. You can also think of it the following way: if I propose a Z. For instance let Z be only a scalar and I say Z=2.0 . Then you can calculate the probability of p(Z=2.0, X=D) (you additionally observed the X values to be the data D). However, in the scenarios we are looking at with Variational Inference you cannot calculate p(Z=2.0 | X=D) because there is no (closed-form) functional form of the posterior. Let me know if this helps :) There are also more videos on VI coming soon.
This new video (th-cam.com/video/dxwVMeK988Y/w-d-xo.html) might also shine some additional light on Variational Inference. It is really hands-on with TensorFlow Probability :)
@@MachineLearningSimulation Thank you for this beautiful video. You are assuming z=2 here, but since z is a latent variable that we can't observe in real data, how can we calculate the join probability p(z, x)?
@@2752RUMI Thanks for the feedback :) Glad you enjoyed it. Regarding your question: Just because we can't observe a random variable does not mean we can't calculate its probability (or the joint probability if the latent random variable is part of a bigger model). In the ELBO we have the following expression p(Z, X=D) that I would read as following: "We have a joint distribution over Z and X whereas X was fixed to the data". This essential makes p(Z, X=D) are probability distribution over Z only (IMPORTANT Note: that's not the posterior, it's just the joint with a subset of the random variables being fixed). Hence, we can query the probability for any feasible Z (like the 2 I proposed in the first reply). A more concrete example: Think of a Gaussian Mixture Model p(Z, X), here Z represents the class and X represents the quantity we want to cluster. In this case, Z is the latent class. For simplicity, let Z be either 0 or 1 for all samples, i.e. we only have two classes. (Also observe that X is a vector of data points and Z is a vector of class labels, i.e. more precisely we would actually have random vectors). The points we want to cluster (or the set of points) X is observed and given. Then we could fix the joint to p(Z, X=D), i.e. whatever value for Z we plug in we would always plug in the (observed) data for X. Now back to proposing a Z value. Given our model and the factorization (which is straightforward for the Gaussian Mixture Model), we could evaluate p(Z=[0, 0, ...., 0], X=D) which is the probability that all samples belong to the zero-th class or also p(Z=[1, 1, ....., 1], X=D) or anything in between. We don't observe Z, but we can still calculate the probability of the joint it is involved in. Again, note that the joint is not the posterior. In general we can't easily compute the posterior p(Z=[0, 0, ...., 0] | X=D) which I would interpret as: "All class labels are 0 given that we observe X to be D" Let me know if that helped :)
This video assumes a factorizable joint which (at least for simple graphs) the joint probability can always be evaluated. Maybe you find the follow-up videos in the VI playlist helpful: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Hi, thanks for the great explanation! I have a question: is it correct to say that the ELBO is itself a KL divergence, but this time between the surrogate posterior and the joint distribution?
EDIT: This reply contained an error, please scroll to the end of this thread for the correct answer. It turns out @jionah is correct. -------------------- Hi, thanks a lot for the feedback, :) Much appreciated. Regarding your question: Maybe one could do that informally (1), but unfortunately it does not hold mathematically. For this, consider the surrogate q(Z) and the joint fixed to the data p(Z,X=D). Then, if we take KL, we get KL(q||p) = E_z [ q(Z) (log (p(Z, X=D)) - log(q(Z))] which is not equal to the ELBO, which would be ELBO[q] = E_z [ log(p(Z, X=D)) - log(q(Z)) ]. The difference is that in the ELBO, you do not have the q(Z) term before the difference between the two logarithms. (1) Although, I would advise you against that :D I hope that helped :)
@@MachineLearningSimulation Thank you for your nice explanation. jionah's question is my question as well. In your response you wrote. "if we take KL, we get KL(q||p) = E_z [ q(Z) (log (p(Z, X=D)) - log(q(Z))]", which I don't understand. I think instead of E_Z, you should put integral. I totally agree with what you wrote for the ELBO To me, what jionah wrote seems to be correct. please let me know if I'm missing something Thanks
@@salehgholamzadeh3368 Hey, thanks for the clarification. You are right. :) My initial answer contained a mistake. Let's make it clear (I will also use the integral notation to avoid ambiguity): KL(q||p) = int_Z q(Z) [log(q(Z)) - log(p(Z, X=D))] d Z ELBO(q) = int_Z q(Z) [log(p(Z, X=D)) - log(q(Z))] d Z Based on that @jinoah was correct, that you can call the ELBO as the KL between surrogate posterior and joint. Crucially, though, the ELBO is the negative KL. That should also make sense, since the KL is always non-negative (as it is a divergence (~distance)), whereas the ELBO is negative, since it is bounding the (negative) evidence from below. My sincerest apologies for the confusion. I haven't worked with KL etc. over the last months; it can be baffling :D I hope this is now correct. Please let me know, if there is another mistake.









this is probably the best explanation I've yet to see on this topic and I've tried to understand it multiple times, this helped a lot thank you! :)
You're very welcome! :)
I was also struggling with it for a long time. Great to hear my way of teaching is helpful :)
I second that, excellent explanation. And the example at the end is extremely clarifying, it's easy to get lost in algebra without actually understanding the core graphical, numerical and statistical intuition.
I'm doing my master's thesis on the applications of AI in Architecture. Having no significant mathematic training since high school, this video was absolutly invaluable for a math-illiterate like me to gain a deeper insight the mechanism behind a VAE. Excellently explained. 10/10
Beautiful to hear. I'm really glad, I could help 😊
Good luck with your Thesis.
(There will also be videos on VAEs probably end of June)
I guess a typo at 19.52 that original VI target is argmin( KL(q(z) || p(z|D ))) but it was written p(z,D). Actually p(z,D) is the one we end-up using in ELBO. This can be used to summarize the approach here "ELBO: Well we dont have p(z|D) so instead lets use something we have which is p(z,D) but... Lets show that this is reasonable thing to do"
Errata: (Thanks to everyone commenting and spotting the errors :) )
Error at 15:42 : p(D) as well as log p(D) correspond to the evidence. Evidence is just the marginal probability evaluated at the (observed) data. Hence, it is incorrect to say it becomes the evidence after applying the logarithm. Thanks to @D. Rafaeli for pointing this out (see also his comment)
Error at 19:20 : I say that we found the posterior if the ELBO was equal to zero. This is not correct. We would have found the exact posterior, if the ELBO was equal to the (log) evidence, because then the KL is zero which is the divergence measure between the surrogate and the truth. Thanks to @Dave of Winchester for pointing this out. Also see his comment for more details.
Error at 19:50 : I wrongly write down the joint p(Z, D), but I mean (and also say) the posterior, i.e. p(Z | D)
Error at 22:28 : Correct would be maximizing the ELBO and minimizing the KL, but it should be clear based on the context
Do you have the link for interactive ELBO plot?
Hey @@ArunKumar-fv6uw,
unfortunately, I don't have it hosted somewhere. There are only a limited number of plots I can host with streamlit. I am in contact with them to increase this. I will update this thread in case I can get more plots.
Until then, you can do the following:
1) Download the following script from the GitHub Repo of the channel: github.com/Ceyron/machine-learning-and-simulation/blob/main/english/probabilistic_machine_learning/elbo_interactive_plot.py
2) In a Python environment, install the following packages: "streamlit", "tensorflow", "tensorflow-probability" and "plotly"
3) In a Terminal, navigate to the folder you saved the file in and then call "streamlit run elbo_interactive_plot.py" which should automatically open a web-browser and display the interactive plot.
Let me know if you run into problems with this approach :)
@@ArunKumar-fv6uw I got it working. Here is the link: share.streamlit.io/ceyron/machine-learning-and-simulation/main/english/probabilistic_machine_learning/elbo_interactive_plot.py
@@MachineLearningSimulation Thanks
In the formulation of the problem, should we condition q on the data, like p? So we should say "We want to find q(z|x=D) to approximate p(z|x=D)"?
I couldn't run without paying for this AWESOME lecture. Finally, I'm not afraid dang ELBOish. Thanks from South Korea! :)
Thanks a lot for the kind comment and the generous donation ❤️
I'm very glad it was helpful
You saved me! I was so frustrated that I could not understand it, but you video is so clear and understandable!
Wonderful 👍
I'm very happy 😊 Thanks for the kind comment.
i love you man, i have literally spent 20+ hours to understand this. most of the explanations i found are so hand wavy, thank you so much for spending so much time yourself to understand this and then to make this video
You're very welcome! 😊
I'm happy it was helpful. Feel free to share it with friends and colleagues.
You might also find the follow up videos in the VI playlist helpful: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
This is a fantastic video! The intution was explained beautifully and I finally understood all the concepts. Thank you so much
Thanks for the kind words and the donation ♥️
vielen vielen dank für deine Videos! Kann kaum in Worte fassen wie sehr du mir geholfen hast, die Thematik zu verstehen :D
Klar, sehr gerne 😊
Freut mich riesig, wenn die Videos geholfen haben 😀
It's my third day of trying to understand basics of EM and ELBO and I found this video. Now, there won't be a forth. Thankyou
That's amazing ❤️
I'm happy the video was helpful. 😊
Thank you so much! Your explanation is so clear and easy to follow, as opposed to other videos and blogs which either shy away from the derivation or user phrases like 'by simple calculus' to jump straight to the expression
A nice simulation in the last of the video helps a lot in understanding this concept very intuitively.
Glad to hear that! 😊
Thanks for appreciating the streamlit demo.
Around the middle of the video, I gave a like. Towards the end of it, I had no choice but to take my like back... because I needed to like the video again!!
Nice ♥️. Thank you very much.
The video is very nicely organized, I would like to point out to the author and audience that KL divergence is not a distance as it is not symmetric, that's why it is called divergence and not KL distance
Thanks for the comment and the nice words 😊
That's of course correct 👍
I have been trying to understand this topic because it keeps popping up with variational autoencoders and this video explains it so well!. Thank you!
Thanks for the kind comment 😊 you're very welcome.
Wonderful explanation. Certainly one of the best I’ve seen on this topic!
Thanks 🙏 for the kind the kind feedback and the donation 😊
Thanks a lot! This made me finally understand the ELBO. I really appreciate that you focus on explaining the intuition behind it.
You're very welcome. Thanks for the kind feedback 😊
Finally, a really good explanation, and I have seen a few. Thanks! And I'm talking from a perspective of someone who read Bishop ;)
Thanks a lot 😊
Happy to hear this slightly different perspective is well appreciated.
This is a terrific explanation!! Everything I was looking for! Thank you so much
You're very welcome :). Thanks for the kind words.
Great lecture as always. In the context of your camera and image scenario 1:57, I'm struggling to understand why you mention "we have the joint P(Z, D)". If Z is latent, e.g., camera angle, and we have no measurements for it, how do we know the joint P(Z, D)?
Thanks for the kind feedback 😊
That was a common remark so I created a follow-up Video to hopeful answer this question: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
You might also find other video's of the channel on VI helpful. There is a playlist (should find it on the channel site). 😊
A fantastic explanation! Thank you
thank you for this brilliant video, this is the best explaination I have seen so far about this topic.
You're very welcome! 😊
Thank you for the amazing feedback.
Absolutely Amazing!
Thanks 🙏
Vielen Dank für die tolle Erklärung und das hoch-qualitative Video. So macht lernen viel mehr Spass :)
Viele Grüsse aus der Schweiz!
Sehr gerne 😊
Freut mich sehr, wenn es hilfreich ist :)
Please also check out the follow-up video for some more details regarding the challenges in VI: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
Around 19:20 you talk about the "computable" item which is the ELBO and then mention that when "it" is zero, we have "found the posterior." I think you mean, if the KL divergence is zero, then the approximation is perfect and we have found the posterior. But we are not optimizing the KL divergence directly, rather we are optimizing it indirectly through the ELBO. This is possible because: KL = -ELBO - log(p(D))] Since KL must be 0 or greater, the ELBO will, at its theoretical optimum, take the same value as the evidence log p(D), not zero. (unless p(D) = 1.)
This may well be what you meant, but I figured I'd write this out for anyone else who might interpret it incorrectly.
Yes, you are absolutely correct :).
It should be that we found the posterior, if the ELBO equals the evidence as then the KL would be zero.
Thanks for noticing, I will add it to the pinned errata comment.
Great video! Best I've seen on TH-cam.
Thanks so much :)
These kind words are very motivating for me.
This is an excellent lecture on variational inference. Thanks for the effort.
You are welcome! :)
Thanks a lot.
fantastic introduction
Thanks 🙏
Thank you! This is amazing!
You're welcome 🤗
That is absolutely awesome! Thanks for the effort!
Thanks for the kind comment. You're very welcome 🤗
Thanks for this video. I used to watch Panda (those cute furry bears) videos to relax my mind before starting on some complex task but today I watched this video
Haha :D Amazing comment.
It's great to hear that my video can also be relaxing.
Feel free to leave a link to a nice Panda video here, I would also be interested in relaxing.
@@MachineLearningSimulation
Ultimate de-stresser. Have watched this many times
th-cam.com/video/74PxKZhe1X0/w-d-xo.html
I can imagine. This small one is particularly cute 😁
best explanation for variational inference! thanks.
Thanks a lot :).
Feel free to share it with friends and colleagues.
Going to point A to point B is the same as going from point B to point A, hence we call this distance. In KL-divergence, it is not the case. Therefore, we should be mindful to note that the KL-divergence is not truly a distance metric as the KL-divergence for a distribution q with respect to p is not equal to the KL-divergence for a distribution p with respect to q.
Sure, the KL divergence does not fulfill all axioms of a distance metric, still I think it is a valid conceptual introduction to compare it with one. :)
Thank you for the clearest explanation of Variational Inference I've seen yet. If I were to apply the concepts of this video to neural networks, would z be the activation state of hidden neurons, or would z be their weights? In graphical models, z is the value of the unobserved node in the graph, and in neural networks the value of a node is its activation. But I think that in KLD and ELBO z would be weights because we want to learn (infer) weights in neural networks, right?
Thanks for your feedback, :)
I think you are referring to Bayesian Neural Networks, if I am not mistaken? If so, then you are correct, Z would correspond to the weights in the Neural Networks. In a supervised learning problem in a Neural Network, you have some inputs X and outputs Y, as well as unknown (hidden/latent) weights Z of the networks. The activations of the hidden neurons are some deterministic computations (at least in the classical form of Bayesian Neural Networks) and therefore do not have a random distribution associated with them.
Putting this back together in the Variational Inference Framework: You can observe the inputs and outputs (hence the X and Y of the NN make up the X in the video), but you do not observe the weights of the Neural Network (hence they make up the Z in the video).
Let me know if that helped, :) I can also elaborate more if needed.
yes, I'm referring to Bayesian Neural Networks, and you have addressed the heart of the confusion for me. Thank you again.
Fantastic :)
In the far future, I plan to also have some videos on Bayesian NN.
I think neural networks blurs the line between observed and unobserved variables. It's true that we cannot observe the IDEAL weights that would produce accurate task results, but we can observe the weights themselves because we set those weight values ourselves. Nevertheless, I see the point that weights play the role of the "unobserved" target of inference.
@@MachineLearningSimulation What would z be in case of Auto encoders. The representation vector itself right?
Great great talk. One question, one thing I am struggling to understand with VI or ELBO in general:
- Say we have typical classif. problem and minimize cross entropy, we are in fact doing Min(KL(truth, estimate)) where the truth is the true labels of data. (I assume same goes for regression problems in a sense minimizing the RMSE does this)
- Why then in VI approach we switch them around from the start? I.e. we are doing Min[KL(estimate, truth)] and what is the interpretation of this?
In short:
Min[KL(p, q)] - traditionally
Min[KL(q,p)] - in VI
why? how ? what? does this all mean?
Amazing talk and thanks in advance for your time :)
Thanks for the interesting comment 😊
It's a great question. Unfortunately, I do not have a good answer. You could also frame a VI problem the other way around (which would of course be a different optimization due to the KL being non-symmetric).
I would have to think about it further, but I'm unsure whether we would end up at sth like the ELBO if we had it the other way around.
@@MachineLearningSimulation Am I seeing it right though? Is VI problem Min(KL(estimate, truth)) and the traditional say classification problem is Min(KL(truth, estimate)) ?
Hello again... I wonder if you have ever had the chance to look into the Generalised Coordinates of motion! The goal of VI in there, is to not only infer the expected value of the hidden state, but also infer hier temporal derivatives of it (e.g., velocity, acceleration, jerk, etc.). In particular, in highly dynamic systems, this can help us track the expected value of the hidden states much better (i.e., keeping up with the dynamics while trying to do VI). This would be an AMAZING idea for a video.
Hi, thanks for the suggestion! :)
I will put it on my list of video ideas, cannot guarantee I will do it but never say never ;)
Awesome video. This made the topic so much clearer for me!
Great to hear! :)
That's a really very good video. Thanks a lot.
You are welcome! Thanks for the kind words 😊
Fantastic explanation, thanks for your work!
You're very welcome! Glad it was helpful.
Awesome and informative video. Thank you
You're welcome 🤗 thanks for the kind comment
Hi this was the most epic explanation I've ever seen, thank you! My question is that at ~14:25, you swap the numerator and denominator in the first term -- why did you do this swap?
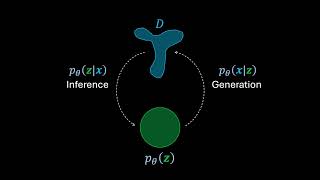
Great video on explaining even the math concepts, but I stood with a doubt, perhaps a stupid one: In the beggining of the video you had the blue line p(Z|D) = probability of the latent variable Z knowing D data, so events Z and D are not independent right? If I understood correctly, then, at 10:20, you say that we have the joint probability P(Z *intersect* D). I don't think I understood this: how do we know we have that intersect? Is it explained in any prior minute...?
Thank you for your attention
Excelent explanation.
Thanks a lot :)
Amazing lecture. Thank you so much
You're very welcome :).
This was a common question, so I created a follow-up video: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html . You might also be interested in the entire VI playlist (including examples etc.): th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Awesome explanation of Variational Inference. Kudos. Just one comment. At 22:27 you state task is to minimize the ELBO and maximize the KL divergence. Should'nt this be the reverse. Minimize KL divergence and maximize ELBO
You're very welcome 😊
You are absolutely right, it should be the other way around. I already collected that error in the pinned comment under the video 👍
@@MachineLearningSimulation Sorry I missed it :-) . Thanks again for this awesome explanation. If possible can you also explain diffusion networks as they also rely on Variational inference and similar concepts.
No worries 😊
The comment section is already quite full under this video.
Yes, long term goal is to also cover different deep generative Models like normalizing flows or diffusion models. Unfortunately, I cannot give a time estimate, though. Maybe around begining of next year, depends a bit on where my interests evolve :D
Nice video. Terminology wise, note that the "evidence" is simply P(X) (or P(D) in your notation). You don't call it evidence only after taking the log. The ELBO is actually the (log) Evidence Lower Bound.
Thanks for the feedback :)
You are absolutely right. I will add this point to the comment with error corrections.
awesome Visualization and explanations!
Thank you! :)
Btw: You can also find the visualization online to play around with it: share.streamlit.io/ceyron/machine-learning-and-simulation/main/english/probabilistic_machine_learning/elbo_interactive_plot.py
Best explanation.
Thanks 🙏
Hello, thank you for the video. In your example you said we have observed X as a dataset (X=D). 1- Does that translate to us having p(X=D|Z)? 2- If so, then why does it not translate to us having the marginal p(X=D)? 3- Later in the video you say we have p(D), but earlier it was stated we don't have p(X=D), so what is the difference between p(D) and p(X=D)? Thank you
Hi,
thanks for the comment. :)
Regarding your first and second question: I think that's a common misconception. Check out this follow-up video for more details: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
For the third: do have a time stamp for the point in the video? It's been some time since I uploaded it 😅
First thank you for all your videos, you already helped me so much!
I have a question though: in 20:00 you said that q*(z) = argmax (L(q)) but shouldn't L(q) be smaller here? Because in the KL we have:
KL = - L(q) + log p(D)
A larger L(q) will become negative, log p(D) is negative, so KL will be negative here too right?
Let's say we maximize L(q) and get a value of 1000 and log p(D) = -900
This gives us: KL = -(1000) + (-900) = -1900 < 0
Shouldn't we instead minimize L(q)? Or am I out of the loop (which I think is more likely) ?
Thanks for the comment, :) It's great that you put in the thoughts and critically interpret the video's contents. That helps a lot in understanding the content (at least for me, this was a good learning strategy).
Regarding your question: You have a small misconception here. The Evidence-Lower-Bound is a term that is smaller than the evidence (in the video I say it is always negative, which is technically not correct, but in almost all real-world cases it will be a value smaller than zero, hence let's say it is negative).
Since the evidence is negative, let's take your example with log p(D) = -900, the ELBO will always be smaller equal to that (making it a lower bound, if it were bigger than the evidence, it would no longer be that bound from below). Since we have the classical "smaller equal" sign (
One more thought: When one looks at the documentation of TensorFlow Probability (www.tensorflow.org/probability/api_docs/python/tfp/vi/fit_surrogate_posterior ), one might think the ELBO is a positive quantity. However, in this case, they are working with the negative ELBO. The reason for this is that this changes the optimization problem from maximization to minimization, which is more standard in the optimization community, though both optimization problems are identical.
I also mention this in the video on Variational Inference in TensorFlow Probability (th-cam.com/video/dxwVMeK988Y/w-d-xo.html )
I hope this answered made it clear, :) If not, let me know, and I will try to phrase it differently
@@MachineLearningSimulation It's all super clear now, thanks! I have to says that I was quite tired when I watched the video. Taking a couple days off really helped me out. Your answer was the cherry on the top!
You're welcome 😊
I'm happy to help.
Feel free to ask more questions if things are unclear.
Thanks for the great explanation!
You're welcome 😊
Amazing explanation!! I have a doubt though, How do we find the joint? You kind of said that we have access to the functional form of the joint because we have the directed graphical model but, I do not understand what you mean by that. Can you please elaborate a bit perhaps with a toy example?
Thanks a lot 😊
You probably find what you are looking for in one of the follow up videos: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Thank you for the great video. However, KL-divergence is not really a "distance" metric, as it is not symmetric.
You're very welcome 😊.
That's of course correct, could have been more precise.
thank you for your great video
You're welcome :). Thanks for the kind comment.
Excellent tutorial!
Thank you! Cheers!
Great explanation ! Thank you sooo much
You're welcome 😊
the best explanation! indeed!
Thanks a lot 😊
It's a brilliant job, thank u! really helps a lot!
Glad to hear that! :)
You're welcome
very good explanation
Thanks a lot ❤️
This video is amazing!
Thanks
Thank you so much for the awesome explanations! I was wondering, when you show the interactive ELBO plot, with computed ELBO, KL, and evidence values -- where does evidence come from, i.e. didn't we say that we don't have access to that marginal probability in the beginning..?
Hey, thanks for the feedback :)
I appreciate it a lot.
That's a great observation. Indeed, in most real-world scenario, we would be unable to obtain the value for the evidence. Here, I just arbitrarily selected one. If you take a look at the source-code of the visualization (if you ignore my terrible typos there for a moment :D ) at line 123 I picked the smallest KL value and put a negative sign in front. However, I could have also just said -40.0 or any other negative value.
Maybe as an interesting side-note: the evidence gets smaller the more complex the models are and the more samples we have in a dataset. That is because observing the data in that particular way through that particular model will just become very unlikely then.
This was very clear! thank you! :)
You're very welcome!
oh god, thank you that was the real beset
You're welcome :)
Hello,
Thanks a lot for your video, I have 2 questions.
- In 3:42 you mentioned marginal (p(x=D)) is the problem.
Why this constant is important? can you illustrate it by an example?
-In 10:29 you mentioned that we have the joint distribution but not the posterior. can you please example a graphical model to enlighten it?
Many thanks
Hey, thanks for the comment :) And also the time stamps, that helps. It's been some time now since I uploaded the video :D
Regarding your questions:
1) I can understand confusion. It might not seem that hard in the first place, but the constant is crucial in order to have a proper probability density function. We can already the query the posterior p(Z | X=D) in terms of its proportional, i.e., p(Z | X = D) ~ p(Z) p(X=D | Z). Consider the example of a Gaussian Mixture Model (and ignore for now that this simple model has an analytic posterior). Here, X are the positions in feature space and Z is the corresponding class. Assume we observed data D, and want to know how probable it is that the datapoints belong to a specific combination of classes, e.g., all samples were from class 0. Then we could not use the proportional posterior (which, in essence, is just the joint distribution) to assess this probability. The only task we could use it for is to say, which of two combinations of classes are more probable. For example, say Z^[1] = [0, 1, 1, 2] and Z^[2] = [1,1, 0, 1]. Then the proportional posterior (alias the joint) spits out two values and whichever value is higher indicates a more probable class association. However, we can't say whether its probability is low or high (in a global context), since it is unnormalized. Worse even, we can't say which class is the most probable, i.e., we could not optimize over Z. This is something we could be interested in (and are in case of inference). So, the marginal in the denominator is crucial. Next question: Why is it hard to obtain: Maybe a counter-question: What is the integral of e^(sin^2(x³) - x²) dx? I just made that up, but most certainly this is a function that does not have a closed-form integral. The challenge is that marginalization means an integral (in case of continuous random variables) or a sum (in case of discrete random variables) which is intractable. A loose definition for intractable could be: We are unable to exactly/analytically compute it with available resources.
2) There was a similar question before. Maybe scroll down to the comment of @C. The bottom line is that, whenever we have a Directed Graphical Model, which is kind of the basis of every probabilistic investigation (e.g. for Linear Regression, GMMs, Hidden Markov Models etc.), we also know its joint by means of factorization (th-cam.com/video/yBc01ZeaFxw/w-d-xo.html ). I understand that this is confusing and might need an example. Also, I promised one in the aforementioned comment, but haven't had the time yet. Hopefully, I can do it in the next months :)
Let me know if sth is unclear. :)
Hey, I just released a follow-up video, which might answer some of your questions: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
There will also be more VI videos (including Variational Autoencoders) in the future.
Great Explanation, thank you for posting! Do you know any channel/video that shows a very simple case of mathematically tractable Bayesian inference and calculate the marginal distribution by integration? I'd love to see that. Keep up the great work.
Hey, thanks for commenting and all the kind words :)
I have something in that regard on the channel: Is that (th-cam.com/video/SEwvipQaNvk/w-d-xo.html ) what you are looking for? It also has an accompanying Python implementation: th-cam.com/video/ISZwydaKZNY/w-d-xo.html
omg, the Bayesian thing really bothers me for a long time, and it is the first time I found a video can explain all the confusion and make it clearer and clearer. Thanks so much and really appreciate your work.
Thanks a lot for the kind words :). I am very happy I could help.
I would like first to thank you for these high quality educational videos. Second i would like to excuse me for my dumm questions ! Well how Variational inference is different from fitting a mixture of gaussian, well let me elaborate.. !GMM tries to estimate densities as linear of combination of gaussians distributions, (well i know gaussians is one of the exponential family distributions). so we are restricting the approximations in the GMM to only Gaussians ! well let me dive into my confusions and thoughts. Well at the end PDF is a function that intergrate to 1. So giving enough basis functions let say Gaussians with infinite function space, is not possible theoretically and principally to estimate any distribution ? Well someone would say well ok in GMM you are clustering and you need to predefine the number of clusters, well i would argue since im interested in the whole density and not clustering, i would expand the space of hypothesis such that i can capture all the details and the multimodality of the distribution. Well think of it like you have a large Dictionary of PDFs and the goal is to pick the PDFs and learn its parameters such that the representation with respect to this dictionary is sparse so that you pick the least possible number of functions.
One last thing im kind of person who like to imagine and visualize things so im having trouble understanding, "well not understanding" but conceptualizing or imagining or appreciate the probabilistic framework. well when someone say P(X,Y) where X is MNIST and Y are the labels, like for me what does that mean taking multivariate scalar mapping in function of the datapoint and it is label, or P(X,Z) datapoints with its latent variable, well at the end im not really interested in the "scaler of chance" namely the probability. But im going from the spread of the data to learn something about the data itself. i mean why that make sense at all. For instance when i say i have P(X|Y=0) well is a real mathematical function or just my ability to extract the digit 0 from the whole dataset. im really having hard time feeling these terms. I don't have problem with the "mechanical" mathematics at all but i feel im missing something. Sorry if the questions are out of context of the video but i appreciate the response.
Hey,
first: also thank you for your warm feedback :)
I really appreciate that, and it motivates me a lot to put out these videos. It is even more amazing to see that people like you are actively thinking about the video's contents. I can just say that from my perspective, this is one of the best ways to learn: to watch/read/listen to things critically and come up with questions. Hence, there are no dumb questions and I can totally understand your confusion. This is an advanced and tough topic, with which I also struggled for a long time. Therefore, please feel free to also formulate follow-up questions in case my answer to your points are insufficient.
Let me sum up the points from your comment and then answer them individually:
1) Why are GMM not enough to capture complex distributions (even approximately as a surrogate posterior)? What is the need for Variational Inference?
2) How can one think of the X & Z (that I also used in the video)? What do they represent, how could you visualize them?
(I did not get your question on the sparse dictionary of PDFs, could you elaborate on that?)
Answering your questions (or at least trying to ;) )
1) Yes, you are correct. In theory, having a mixture of infinite Gaussians should be enough to capture arbitrarily complex (posterior) distributions. Well, probably there are some pathological examples that this does not work in general, but it should be correct for anything practically relevant. The downsides are, that first you could need an unreasonable large number of components in your mixture and second that the training stage may be highly complicated.
For the first, think of a distribution in two dimension which density is high on a ring around the origin. You would need many sharply peaked Gaussians in order to well represent the density in the mixture. For Variational Inference, on the other hand, you could just use a clever Normalizing Flow or choose a family of parametric distributions that has this density feature. Of course, this requires some knowledge on the density distribution.
For the second, consider training of Gaussian Mixture Models in high dimensions by the EM algorithm, which has quite some difficulties (I also mention some of them in my video on implementing it: th-cam.com/video/rSJifjJid0k/w-d-xo.html ). The higher the dimensions, the more mixture components and the more complicated the data points, the "more non-convex" the optimization will become. Additionally, you will have problems of enforcing the positive definiteness in the covariance matrices. Hence, from this perspective, using GMMs is impracticable.
2) It is the same for me, I like visualizations or at least a way to think of things. Unfortunately, working in this high dimensional spaces is highly complicated. There are many effects that seem unnatural to a human being used to two, three or four dimensions (one example: en.wikipedia.org/wiki/Volume_of_an_n-ball ). Some physicist (I unfortunately do not know of) once said (loose quote): If I have to visualize a 27-dimensional space, I draw it three-dimensional and say 27 in my head. (Maybe you have a link to the true quote).
But back to your questions: MNIST might be a bit misleading, because it is usually used for supervised learning (we know images and labels during training and the latent variables are the parameters/weights of our model, whereas in classical Machine Learning they are not considered probabilistic, hence latent might be a bit confusing). However, for the sake of working in high-dimensional spaces, let's take MNIST anyway. X is an image and in the case of MNIST consists of 28x28 pixels with a grayscale value. One could therefore view an image as a 768-dimensional vector with coordinates that are in the range from 0 to 1 in all its axes. Now, we have a bunch of images. Hence, there many 768-dimensional points. For each point we additionally have an (observed during training) label. The points adhere to some structure in this high dimensional, or have a certain density, that we want to capture with our distribution.......
fantastic video!
Thank you very much!
This is excellent, thank you
You're welcome :)
Thanks for the nice feedback
this is tremendous thank you
You're welcome 🤗
hi prof thanks for fentastic video. my question is we donot have acesses to P(d), but how do you choose is value that is -0.030
You're very welcome 🤗 (I'm not a professor though ;) )
I assume you refer to the visualization at the end of the video? This value I chose arbitrarily, sind it depends on the dataset, which is never talked about in this example.
Hats off to you indeed. However, I am confused about KL being always positive @16:37. If q(z)=p(x,z), then the results is KL = 0 + log(p(x)) < 0. what is the thing that I am missing here? Thanks in advance
I searched it and I come up with a conclusion. In math, it is proved that KL>=0. Hence, the loss should be always >=0. Accordingly, we have to restrict q(z) so that it become Not equal to p(x,z). Therefore, L(q) should be bounded by lp(x) (i.e., L(x) belong to the following range [p(x),inf).
Hi, thanks for the comment :). It seems like you clarified it for yourself. There are some points, that are not fully correct yet.
Indeed, what you showed is that the loss is a lower bound to the log-evidence, i.e., L(q) in (-inf, log(p(D))) [note the log and the minus in front of infinity, you do not have this in your comment] . Hence, also the name: Evidence-lower-bound (ELBO). As a consequence, it would also be fine if q(z) == p(D, z), as our lower bound would then be tight and the KL was zero.
You said that it is proven that KL>=0. This is not fully correct. Actually, it is one of the axioms of any divergence (or a distance) to be greater equal 0.
What software are you using for the "blackboard"? You (as well as people like William Spaniel and Khan Academy) really inspired me to do teaching myself
Appreciate it 😊 Khan Academy was also a big inspiration for me.
I use Xournal++, in parts also because it works nicely with Wacom tablets under Linux. You need to do some small adjustments to the settings to get a back background.
@@MachineLearningSimulation Big thanks! May I ask do you have any video/video series discussing EM algorithm? Most resources I've read only explain its application for one specific use case such as in Gaussian Mixture Model.
These are the videos I have on the EM algorithm:
🔢 Expectation Maximization Algorithm | with implementation in TensorFlow Probability: th-cam.com/play/PLISXH-iEM4JnNy8UqOBsjW6Uf-ot1RoYb.html
Awsome!
😊 thank you.
Thank you for a great video! One thing I missed was why you chose KL[q(z)||p(z|D)] and not the other way around KL[p(z|D)||q(z)]. My guess is that the former optimizes q(z) to avoid results that are unlikely according to p(z|D) at the expense of possibly capturing only a subset of it. The latter would try to represent all of p(z|D), but potentially give us many unrealistic results, and this is not what we want. Could you please delve into this topic and clarify your choice of the metric?
[edit: please read the thread all the way to the end. I made some stupid mistakes and wrong claims in my first replies. Thanks to Dmitry for pointing them out]
[edit: I wrongly noted down the KL expansion in terms of cross entropy and entropy and corrected it later on]
Hey, thanks for the great question and the nice feedback 😊
Using the KL the other way around is also sometimes done and usually referred to as expectation propagation (en.m.wikipedia.org/wiki/Expectation_propagation).
Your interpretation is definitely also a way to view it. Maybe also view the KL in terms of the entropy. If you slice up the KL definition of KL(q||p) you get H(q, p) - H(p) which is the cross entropy between the two distributions minus the entropy of the p distribution. If you were considering the KL the other way around, you would get the entropy of q, H(q) which is not really relevant for variational inference. The goal of VI is to find the distribution the closest to the actual posterior and not one that additionally has optimal entropy.
Maybe that shines some additional light on it 😊. It is probably not the most intuitive interpretation. Let me know what you think
@@MachineLearningSimulation Thank you for your reply! I am still a bit confused. If I start with the definition, the Kullback-Leibler divergence KL(q||p) is the penalty for using the distribution p with the reference probability is q; in other words, the average number of bits assuming the distribution p minus the average number of bits when using the actual underlying distribution q, i.e. H(q,p) - H(q,q), where, obviously, H(q,q)=H(q). Thus, I have KL(q||p)=H(q,p)-H(q). What did you do to get H(q,p)+H(p)?
Yes, you are of course correct.
Writing out the KL gives KL(q||p) = H(q, p) - H(p). I was replying on mobile and did the math in head, not the best idea :D
(I will edit my first reply).
Then we get the two ways:
KL(q||p) = H(q,p) - H(p)
KL(p||q) = H(p,q) - H(q)
If we know want to minimize the KL for a variational approach, my point of view (maybe not the best though) would be that with the second approach we could potentially fit a surrogate posterior q that is less optimal in terms of how close it is to the true posterior, since we could just select a surrogate with a high entropy that would then lower our total KL. Whereas in the first approach the H(p) is just a constant we do not have to consider for the optimization.
I hope this makes it clearer. Let me know if there is still some confusion left 😊
@@MachineLearningSimulation Yes, my confusion is because KL(q||p)=H(q,p)-H(q) and not H(q,p)-H(p). Please clarify your answer.
That's right. I made another mistake, sorry for that. Correct should be as you said that
KL(q||p) = H(q, p) - H(q)
and
KL(p||q) = H(p, q) - H(p)
Then my initial answer is of course nonsense. (I will edit it again and leave a note to read the thread all the way till the end).
So then judging by this interpretation, one could argue (actually the opposite) that it is desirable to have a high entropy solution to the optimization problem. Because when using former way of the KL we choose a solution that minimizes the discrepancy to the actual posterior and is optimally in its highest entropy (something one could wish for in analogy to some distributions arising from a maximum entropy principle). The latter form of the KL would then just try optimize the discrepancy between the two distributions and just has a constant offset H(p) that can be ignored in the optimization process over q.
I hope that is now right. Please correct me, in case I made another mistake.
Again my sincerest apology for the confusion. I didn't have a piece a paper while replying from mobile.
First of all, thanks for the great explaination.
I still have a few questions. At the moment i am trying to understand the Inference of Latent Dirchichlet Allocation. In the original Paper they also use Variational Inference. It is often stated that in Bayes Theorem the joint/likelihood p(z, d) and the prior p(z) are given. But don´t these also depend on the hidden variables z? I thought the main goal of Inference is to find z. Do you optimize z with the alternative distribution q until it terminates and then put the final z into your original distribution p?
Thank you very much for the comment and the kind words :)
I must admit, I haven't worked with LDA yet - so far I only read the paper. However, I think that your question is similar to a comment from 6 months ago asked by @C . The confusion you probably have is that hidden or latent does not mean non-computable.
The problem Variational Inference tries to overcome is that in a lot of realistic applications (including LDA) the posterior p(Z | D) is intractable, meaning that in order to analytically evaluate it you might have to do computations that are impossible. That is because they involve an exponential number of operations (e.g., extremely nested sums when marginalizing over high-dimensional discrete random vectors) or solving integrals for which there are no closed form solutions. And in order to approximate the posterior with any means (not just VI but also MCMC) you evaluate the joint distribution, aka the product of prior and likelihood.
Maybe think of it like optimizing a function. Imagine you want to optimize f(x) = x^2 and assume it would be impossible to find an analytical optimum to it. Now there are algorithms that (iteratively) find an approximate solution to the optimum, i.e. an x-value that is maybe not exactly 0 (which would be the true optimum) but is 0.1. In order to do so, they evaluate the function a couple of times, e.g. f(2.0) = 4.0 or f(-3.0) = 9.0.
Back to probability theory: we want something (optimum -> posterior) which we cannot get exactly. Therefore, we use an algorithm to obtain an approximation to the true solution. This algorithm has to evaluate something (target function in optimization -> joint distribution).
I hope that helped :)
Let me know if sth is still unclear.
@@MachineLearningSimulation Thank you for the detailed Answer. I think I have a better understanding now.
I want to say that in most ELBO problems it is really hard to calculate
the only way to bypass this problem is just to use the given pseudocode and do the EM
Hey,
probably that was not fully clear in the video, but Variational Inference and the EM algorithm are identical IF the posterior is tractable (and reasonable to compute). I plan to do a video on that.
However, for most applications (like Variational Autoencoders) the posterior is not tractable, which is the reason we either have to use sampling strategies (like MCMC) or Variational Inference like presented here.
@@MachineLearningSimulation MCMC is too slow for topics like LDA and I am doing Bayesian GMM
It is killing me X( ashkush.medium.com/variational-inference-gaussian-mixture-model-52595074247b
even EM is always stuck and very hard to calculate the ELBO like
Skewers but it's still very efficient in big data
@@ccuuttww Okay, that's probably quite problem dependent. I would say that performing inference in any reasonably complex probabilistic model will always be difficult.
Something interesting to read is also (www.fz-juelich.de/SharedDocs/Pressemitteilungen/UK/EN/2020/2020-09-21-covid19-bstim.html) where German HPC researchers developped a Covid Pandemic Prediction Model using Bayesian Networks / Directed Graphical for which training took > 100'000 GPU hours and daily inference takes 1'000 GPU hours. One can query the prediction results on covid19-bayesian.fz-juelich.de/ - unfortunately only in German.
Really good video. Thank you very much. However just to make sure I understand correctly. Our objective is argmax L(q) function, but same time L(q) will always be smaller than log(p(D)) right?
Hi,
thanks for the comment :)
You're very welcome.
You are correct. The ELBO is bounding the evidence from below. Our objective is to come as close to the evidence as possible. Only in synthetic scenarios (with closed-form posterior) we are able to converge against the evidence log(p(D)).
7:04 we replace conditional distribution p(z l x) by some approximate function q(z). But it means that we now assume that z and x independent, since the probabilities of z doesn’t depend on x now. Is it really this way?
Hi Yury,
thanks for the great question. I can understand the confusion ;)
Actually, both approaches are possible. You can have surrogate posterior that are "some form of a mapping" like q(Z|X) or the independent one as shown in the video q(Z). The reason, the latter works just fine is that in the ELBO, you have all dependency on X fixed to the (observed) data. Consequentially, the q(Z) you find can have no dependency on X . Obviously, the surrogate posterior q(Z) will be different for different data. If you proposed the distribution for q(Z) like a Normal and just optimized its parameters, those would most likely turn out to be different for different data values. Imagine it like this: if you had the true posterior p(Z|X) and wanted to evaluate it for some data D, you would fix it p(Z|X=D) which gives you a distribution over Z only. That's what a q(Z) shall represent. Hence, if you change your data for some reason you have to run the ELBO optimization (i.e. Variational Inference) again to obtain another q(Z) as what you'd get for plugging in D_2 into the hypothetical true posterior, i.e. p(Z|X=D_2).
If you were to do Variational Inference for a q(Z|X), you would only have to do that once and could then use "like the true posterior".
That might raise the question, we consider the case q(Z) in the first place? I believe that greatly depends on the modeling task. I only have some anecdotal evidence, but the optimization for q(Z) instead of q(Z|X) is often "easier". Btw: You find the approach with a q(Z|X) surrogate posterior in Variational Autoencoders.
I hope that shined some more light on it :). Let me know if sth is still unclear and feel free to ask a follow-up question.
at 11:59, shouldnt the p(z' | D) = p(D | z') * p(z')/p(D). The p(z') is gone?
oops, sorry. I miss out the notation p(D, z') is p(D | z') * p(z'). But another question, shouldn't the p(z', D) be p(D, z') since your posterior is p(z' | D)
Hey, sorry for the late reply. Somehow, your comment got wrongly tagged as Spam by TH-cam and I had to manually accept it :D
Regarding your initial question: You already correctly figured that one out. The joint distribution p(D, Z) is equal to the likelihood times the prior, p(D, Z) = p(D | Z) * p(Z). In other words, at the mentioned point in the video, I use this "simplified form of Bayes' Rule".
Regarding your follow-up question: For joint distributions, the order of the arguments does not matter. Hence, p(Z, D) and p(D, Z) are equally fine. You can pick whatever suits you best and depending on the literature you read, you might see people using these formats interchangeably. :) But of course take care, that in conditional distributions the order matters (at least the order of what is before the "|" and after the "|")
I hope that answered your question :)
Please let me know if there is still something unclear.
@@MachineLearningSimulation Thanks for your explanation!
understood ✅
Awesome :)
Thanks 😁
This is fantastic!
Nice :). Thanks!
very useful tnx
You're welcome :)
I haven't understood why we have access to the joint but not to the prior over the data. It appears a little unintuitive to me. Maybe someone could explain?
Sure, this was a popular demand, so I created a follow-up video dedicated to some open points of this video (including the one you brought up): th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
Enjoy 😉
In your video on Calculus of Variations, the Variational approach was characterized by the use of the Gateaux derivative. In this video, I don't see any mention of Gateaux derivative (or Euler Lagrange). Shouldn't a method that's named "Variational Inference" build on top of the Calculus of Variations, Gateaux derivative, or Euler-Lagrange? Or does the mere fact of trying to minimize a functional enough to qualify the method in this video to earn "Variational" in its name?
Hey,
that's a fantastic question! Indeed, it is rather unintuitive that this does not appear here.
The main result of variational inference was that you want the surrogate posterior as the arg maximum of the ELBO. This is a variational optimization problem, because you are seeking a function, i.e. a distribution - the surrogate posterior -, that maximizes the ELBO functional. Hence, the ELBO is a functional:, if you insert different distributions like normal, gamma or beta etc. the ELBO value differs (although here you would need distributions with the same support). Therefore, theoretically you could apply the functional derivative and find a maximizing surrogate posterior. Also check out my video on the mean field approach, where we do this. th-cam.com/video/_iNajZR6jY4/w-d-xo.html
However, and that's the major point: in almost all practically relevant problems, there is no closed form maximizing posterior, i.e. you won't be able to find a distribution. Therefore, in order to make the optimization practical one proposes a parametric family of distributions (like a normal distribution with learnable mean and variance, or a distribution for which its parameters are given by trainable neural networks). Then we move from optimization in (infinite dimensional) function spaces to finite dimensional vector spaces (the space of parameters). And therefore you don't see the gâteaux derivative.
Please let me know if that helped 😊. And please ask follow-up questions if you have any.
Thank you for the clarification. I had to think about it for some time. I would also like to add this quote from Wikipedia's article on Variational Inference:
It can be shown using the calculus of variations (hence the name "variational Bayes") that the "best" distribution q*_i can be expressed as
I believe that q*_i is the surrogate distribution. If this is the case then the next step is to follow the reference cited -- Lee, Se Yoon (2021). "Gibbs sampler and coordinate ascent variational inference: A set-theoretical review"
Why we have access to the joint probability if we can observe only X.
Hi,
that was a common remark among the viewers of the video. By "access to", I mean that we can query the joint probability for any values. In other words, we have its computational form. This is not true for the exact posterior.
To lift that confusion, I created a follow-up video. Check it out here: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html . You can also find some hands-on details in the video with the exponential-normal model: th-cam.com/video/u4BJdBCDR9w/w-d-xo.html
Great video! =) Can somebody please explain why we have the joint distribution and why don't have the posterior?
I understand that we have some dataset D (images) and maybe we even have their ground truth data Z (like categories, cat, dog, etc..). Does this automatically mean that we have the joint distribution?
Great point! This was common question, so I created a follow-up video. Check it out here: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
At about 2:00 you say that we have access to the joint distribution p(x, z) since we have a directed graphical model. Why exactly is this the case? When you talk about a DGM, do you refer to something like a Bayes Net, where a node x' is reliant on its parents, Parents(x')?
Edit: Oh I just saw the discussion below with @C, that clears it up!
As also in the thread, a video on this is on the To-Do list :)
@@MachineLearningSimulation Wait actually on further reflection I realize I still don't quite get it haha!
So in the thread below, you said "You can also think of it the following way: if I propose a Z. For instance let Z be only a scalar and I say Z=2.0 . Then you can calculate the probability of p(Z=2.0, X=D) (you additionally observed the X values to be the data D). However, in the scenarios we are looking at with Variational Inference you cannot calculate p(Z=2.0 | X=D) because there is no (closed-form) functional form of the posterior". How can you compute p(Z=2, X=D)? Like if we are considering a VAE where the latent dimension is just 1D, how would we compute p(Z=2, X=D)? Wouldn't we have to know something about the prior distribution of the data (i.e. p(X=D))?
@@addisonweatherhead2790 Sure, no problem, :) It's a tough topic.
To elaborate on one part of my previous answer: "That is, because we know the factorization of it." In the case of the simple model p(Z, X), let this factorize according to p(Z, X) = p(Z) * p(X|Z), then the graph would look like (Z)->(X) . If you now want to query p(Z=2, X=8) (here I also made X a scalar), then you would have to evaluate p(Z=2, X=8) = p(Z=2) * p(X=8 | Z=2) and you can do this because you modeled the distribution of p(Z) and p(X|Z) (for example in the Gaussian Mixture Model as Categorical and Normal, respectively). Consequentially, we do not need the marginal p(X=D) or the posterior p(Z|X) in order to evaluate the joint. Hence, "we have access to the joint".
I hope that provides some more insight :) Let me know.
@@MachineLearningSimulation Just a follow up on this, I'm finally doing a proper probabilistic ML course in school right now, and I'd say this is very relevant / useful background! All too often VI seems to be introduced without properly and very clearly explaining what we have access to, and what we don't have access to, and why.
As you mentioned above, maybe just a brief 5-10 min video on latent variable models, and the basic structure they usually have (e.g. one assumes some distribution on the latent variables, p(z)), and the distribution they induce on the observed data (i.e. p(x|z)). That is one of the parts that made VI difficult for me at first!
@@addisonweatherhead2790 Yes, absolutely. ☺
Finally, I am having some more time to focus on the videos and the channel. I don't want to promise a particular time in the future to release this video, but I will try to move it up in my priority list.
Aaaaand how do we know the joint distribution p(X,Z) ? As said X can be an image from our data set and Z can be some feature like "roundness of chin" or "intensity of smiling". It is bit strange to be able to know jointly p(Image, feature) but not being able to know p(Image) because of multi-dimensional integrals
That was a common question I received, check out the follow-up video I created: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
Hope that helps 😊
10:15 By "we only have access to p(z, D) you mean that we only have access to samples of p(z, D) where we can only observe D, right?
Hi,
that referred to us having access to the functional form of the joint distribution. It was a common question in comments so I produced a follow-up video: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
Hope that helps 😃
Should the ELBO be greater then the evidence?
Many thanks. Could you please share what application you are using to do your drawings and writings please?
You're welcome 😊
Yes of course:
I use Xournal++. It's an open source software that runs under all major operating systems. And I record the videos (plus audio) with obs, which is also cross platform.
@@MachineLearningSimulation thanks a lot for the info.
Thanks!
Welcome! 😊
In the case of variational autoencoders, the strategy would be to assume p(z | D) is normally distributed with both fixed mean and variance, and then try to approximate a encoder network q(z) to match this normal distribution?
Almost. The assumptions in the (standard) VAE framework is that the prior over the latent variables (p(Z)) is normally distributed (with zero mean and prescribed variance/std). Then, the goal is to both learn an encoding distribution q(Z|X) and a decoding distribution p(X|Z) (as deep networks). One can show that the ELBO in this setting is both a data match (plugging, for instance, images into the sequence encoder -> decoder and then compare the difference) and a regularization component given by the distance/divergence of the encoding distribution and the prior.
@@MachineLearningSimulation great
Also at around 2:40 or so its stated that we know the joint of observed and latent. Not sure I get that
Hi,
that was a common remark :) so I created a follow-up video, check it out: th-cam.com/video/gV1NWMiiAEI/w-d-xo.html
@@MachineLearningSimulation Absolutely fine. Having said that its a very crisp explanation of things. ELBO is a core concept even for Diffusion models so has to be understood clearly.
You said that we have the joint probability, but when working with real data in practice, would we have the joint, given that Z is latent?
Good question: I think I was not precise enough. By "we have the joint probability" I mean that we can express the functional form of the joint distribution.
That is, because we know the factorization of it.
You can also think of it the following way: if I propose a Z. For instance let Z be only a scalar and I say Z=2.0 . Then you can calculate the probability of p(Z=2.0, X=D) (you additionally observed the X values to be the data D). However, in the scenarios we are looking at with Variational Inference you cannot calculate p(Z=2.0 | X=D) because there is no (closed-form) functional form of the posterior.
Let me know if this helps :) There are also more videos on VI coming soon.
This new video (th-cam.com/video/dxwVMeK988Y/w-d-xo.html) might also shine some additional light on Variational Inference. It is really hands-on with TensorFlow Probability :)
@@MachineLearningSimulation Thank you for this beautiful video.
You are assuming z=2 here, but since z is a latent variable that we can't observe in real data, how can we calculate the join probability p(z, x)?
@@2752RUMI Thanks for the feedback :) Glad you enjoyed it.
Regarding your question: Just because we can't observe a random variable does not mean we can't calculate its probability (or the joint probability if the latent random variable is part of a bigger model). In the ELBO we have the following expression p(Z, X=D) that I would read as following: "We have a joint distribution over Z and X whereas X was fixed to the data".
This essential makes p(Z, X=D) are probability distribution over Z only (IMPORTANT Note: that's not the posterior, it's just the joint with a subset of the random variables being fixed). Hence, we can query the probability for any feasible Z (like the 2 I proposed in the first reply).
A more concrete example: Think of a Gaussian Mixture Model p(Z, X), here Z represents the class and X represents the quantity we want to cluster. In this case, Z is the latent class. For simplicity, let Z be either 0 or 1 for all samples, i.e. we only have two classes. (Also observe that X is a vector of data points and Z is a vector of class labels, i.e. more precisely we would actually have random vectors). The points we want to cluster (or the set of points) X is observed and given. Then we could fix the joint to p(Z, X=D), i.e. whatever value for Z we plug in we would always plug in the (observed) data for X.
Now back to proposing a Z value. Given our model and the factorization (which is straightforward for the Gaussian Mixture Model), we could evaluate p(Z=[0, 0, ...., 0], X=D) which is the probability that all samples belong to the zero-th class or also p(Z=[1, 1, ....., 1], X=D) or anything in between. We don't observe Z, but we can still calculate the probability of the joint it is involved in.
Again, note that the joint is not the posterior. In general we can't easily compute the posterior p(Z=[0, 0, ...., 0] | X=D) which I would interpret as: "All class labels are 0 given that we observe X to be D"
Let me know if that helped :)
@@2752RUMI I thought about it again, and I think it is good to make a video on this :) I will put it on my To-Do list.
4:14 Isn't it intractable because we don't know p(x, z) in the first place?
This video assumes a factorizable joint which (at least for simple graphs) the joint probability can always be evaluated.
Maybe you find the follow-up videos in the VI playlist helpful: Variational Inference: Simply Explained: th-cam.com/play/PLISXH-iEM4JloWnKysIEPPysGVg4v3PaP.html
Hi, thanks for the great explanation! I have a question: is it correct to say that the ELBO is itself a KL divergence, but this time between the surrogate posterior and the joint distribution?
EDIT: This reply contained an error, please scroll to the end of this thread for the correct answer. It turns out @jionah is correct.
--------------------
Hi, thanks a lot for the feedback, :) Much appreciated.
Regarding your question: Maybe one could do that informally (1), but unfortunately it does not hold mathematically. For this, consider the surrogate q(Z) and the joint fixed to the data p(Z,X=D). Then, if we take KL, we get KL(q||p) = E_z [ q(Z) (log (p(Z, X=D)) - log(q(Z))] which is not equal to the ELBO, which would be ELBO[q] = E_z [ log(p(Z, X=D)) - log(q(Z)) ].
The difference is that in the ELBO, you do not have the q(Z) term before the difference between the two logarithms.
(1) Although, I would advise you against that :D
I hope that helped :)
@@MachineLearningSimulation Thank you for your nice explanation. jionah's question is my question as well.
In your response you wrote. "if we take KL, we get KL(q||p) = E_z [ q(Z) (log (p(Z, X=D)) - log(q(Z))]", which I don't understand. I think instead of E_Z, you should put integral.
I totally agree with what you wrote for the ELBO
To me, what jionah wrote seems to be correct. please let me know if I'm missing something
Thanks
@@salehgholamzadeh3368 Hey,
thanks for the clarification. You are right. :) My initial answer contained a mistake.
Let's make it clear (I will also use the integral notation to avoid ambiguity):
KL(q||p) = int_Z q(Z) [log(q(Z)) - log(p(Z, X=D))] d Z
ELBO(q) = int_Z q(Z) [log(p(Z, X=D)) - log(q(Z))] d Z
Based on that @jinoah was correct, that you can call the ELBO as the KL between surrogate posterior and joint. Crucially, though, the ELBO is the negative KL. That should also make sense, since the KL is always non-negative (as it is a divergence (~distance)), whereas the ELBO is negative, since it is bounding the (negative) evidence from below.
My sincerest apologies for the confusion. I haven't worked with KL etc. over the last months; it can be baffling :D
I hope this is now correct. Please let me know, if there is another mistake.