*Github Code* - github.com/explainingai-code/DDPM-Pytorch *DDPM Implementation Video* - th-cam.com/video/vu6eKteJWew/w-d-xo.html Note: There’s a typo at 19:49, in the denominator, for the variance, instead of cumulative product of alphas till t-1, it should be cumulative product of alphas till t. So \bar{\alpha}_t instead of \bar{\alpha}_{t-1}
After spending one month in web/youtube reading blogs, watching videos finally I got this GEM. Its the best explanation on the mathematics from entire universe. It took me 10 days to grasp all these excellent mind blowing thoughts behind the DDPM. Kudus to you. Keep posting on recent topics.
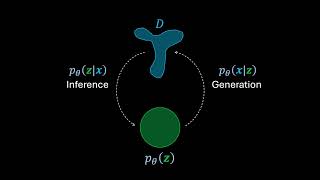
Thanks for this wonderfully intuitive video! It provided a fantastic breakdown of the fundamentals of diffusion models. Let me try to answer your question about why the reverse process in diffusion models is also a (reverse) diffusion with Gaussian transitions. Why Reverse Diffusion Uses Gaussian Transitions 1. Forward Diffusion Introduces Noise Gradually Remember the β term? In the forward process, β is chosen to be very small (close to 0). This ensures that Gaussian noise is added gradually to the data over many steps. Each step introduces only a tiny amount of noise, meaning the transition from the original image to pure noise happens slowly and smoothly. This gradual noise addition is crucial because it preserves the structure of the data for longer, making it easier for the reverse process to reconstruct high-quality images. If we added large amounts of noise in one go, like in VAEs, the original structure would be harder to recover, leading to blurrier reconstructions. 2. Reverse Diffusion Needs "Gaussian-Like" Inputs The forward process only involves adding isotropic Gaussian noise at each step. This means the model learns to work with samples that are progressively noised in a Gaussian way. However, in the reverse process, when the model predicts the noise at each step, the resulting sample isn't guaranteed to remain Gaussian-like. To fix this, after subtracting the model's predicted noise, we add a small Gaussian noise with a carefully chosen variance. This step helps "Gaussianize" the sample, ensuring it aligns with what the model expects at the next time step. This small added noise smoothens any irregularities and makes the reverse process more stable, resulting in higher-quality outputs. Step-by-Step Noise Removal The reverse process works by removing noise step-by-step, moving from pure noise back to a clean image (closer to x0 ). This gradual approach is crucial because predicting small changes (i.e., removing a little noise at a time) is much easier for the model than trying to reconstruct the clean image in one big jump. This is why diffusion models produce sharper and more realistic images compared to VAEs, where predictions often result in blurry outputs due to the lack of such gradual refinement.
This is a great video, i completely understood till "Simplifying the Likelihood for Diffusion Models". I'll need to replay multiple times but the video is very helpful.. Please make more such video diving into maths. Most youtubers leave out the maths part while teaching DL part which is crazy because it's all math.
Wow! This is an incredibly clear explanation of the complex mathematics behind DDPM. Thank you so much, Tushar! This video is a real gem. The formulas may seem intimidating at first, but it's amazing how such a complex model can be derived from a fundamentally simple idea.
Yes you are right. It should be \bar{\alpha}_t instead of \bar{\alpha}_{t-1}. Its correct in the next step but I messed up in the starting expression. Thank You. Have now added this error to pinned comment.
Hi, Very good attempt of explaining the DDPM, and thank you for sharing the information. Kudos! to answer your question at 14:22 (why reverse process is the diffusion?) because while reverse process, after the prediction of noise by u-net we check for the condition whether it is at t=0(x0-original image state) our output would be mean(has same shape of image) or not, if we are not at t=0 then our output would be mean+variance (with this variance we are adding noise again - based on x0). Hope this helps!
14:30 actually the reason we model reverse process also as gaussian is that the distribution q(x_t-1|xt, x0) is gaussian with certain mean and variance. (can be derived using bayes rule not very high level math there) notice that its conditioned not only on xt but also on x0. But in theory p(x_t-1|xt) is the reverse process distribution. Hence we can't say that reverse process is also gaussian. we are just assuming/approximating it
This video was absolutely amazing! Also giving yourself a rating of 0.05 after spending 500 hrs on a topic is crazy(Not that I would know, because I am about a 0.0005 according to this scale) Waiting eagerly for the next one!
Thank you so much! the scale was more to indicate how much I don't know(yet)😃 Have already started working on Part 2 of Stable Diffusion Video so that should soon be out.
Great video thank you ! Some maths would need more explanation though such as at 12:59 where you assume espilon(t), epsilon(t-1),...,espilon(0) are all the same and factorize by a new term named espilon.
Thanks! and I agree with you. In hindsight if I made the video again, I think it would be over an hour long atleast, because there are few aspects that I now think I could/should have gone in more detail. Regarding the epsilon terms, I did talk a bit about this briefly @12:16, where I mention that this can be done because sum of two independent gaussian random variables remains a gaussian with mean and variance being the sum of both the means and variances.
Thank you for this fantastic video on DDPMs, it was super helpful. One thing I'm having trouble understanding is the derivation at 12:29, how can we go from the 3rd line to the 4th line on the right side. I mean this part: sqrt(alpha_t - alpha_t * alpha_{t-1}) * epsilon_{t-1} + sqrt(1 - alpha_t) * episolon_t ...to the next line where we combined these two square roots: sqrt(1 - alpha_t * alpha_{t-1}) * epsilon ?
In the third line, just view the epsilon terms as samples from gaussian with 0 mean and some variance. So the two epsilon terms in third line is just adding two gaussians. Then we use the fact that sum of two independent gaussians ends up being a gaussian with mean as sum of the two means(which here for both is 0) and variance as sum of the two variances. Which is why we can rewrite it in the 4th line as a sample from a gaussian with 0 mean and variance as sum of the individual variances present in third line. Do Let me know if this clarifies it.
Hey, very helpful video. I'm making a project for our image processing course on diffPIR paper, this video explains everything in sequence. All the bad calculation missed in my paper is explained and with proper intuition very nicely thanks👍 Edit: just one question what about the term E[log(p(x_0|x_1))], what is the idea behind it, does the model minimize it?
Thank you! This term is the reconstruction loss which is similar to what we have in vae's. Here its measure that given a slightly noisy image x1(t=1), how well the model is able to reconstruct the original image x0 from it. In an actual implementation this is minimized together with the summation terms itself. So during training instead of uniformly sampling timesteps from t=2 to t=T(to minimize the summation terms), we sample timesteps from t=1 to t=T, and when t=1 , the model is learning to denoise x1 (rather reconstruct x0 from a noisy x1). The only difference happens during inferencing, where at t=1, we simply return the predicted denoised mean, rather than returning a sample from N(mean, scheduled variance) which we do for t=2 to t=T.
Thank You! Do you mean that variance should be sqrt(1- alpha_t) ? If you see the formulation for xt @12:00 then you can see that xt = sqrt(alpha_t) x_(t-1) + sqrt(1- alpha_t)e where e is mean zero and variance 1. Which means sqrt(1- alpha_t)e will have mean 0 and variance (1-alpha_t) which is what is used @19:42 Let me know if I misunderstood your question.
At 4:27 In the definition of the dXt, it is mentioned random mean and zero variance, but at bottom when you do the re-parameterization, N(0, I) is mentioned i.e. zero mean and unity variance. Isn't that different than the defination?
I think there is a comma missing(sorry about that confusion) , it should actually be ''random, mean zero & variance µ(Xt, t)dt" The last term needs to have mean zero and variance µ(Xt, t)dt .
I had a doubt. At 17:11 if we had removed this x0 term we would have gotten stuck ahead, and the ground truth reverse function and the approximat ng reverse function would effectively be representing the same thing as both don't have the information of x0. Am I right in saying this?
I just wanted to kow for an image how will the end result be a normal distribtuion with mean 0 considering it has valeues between o and 1 after normlaized
If we dont use the x0 conditioning then what we could get is KL divergence between q(xt|xt-1) and p(xt | xt+1) You can take a look at Page 8 of this tutorial - arxiv.org/pdf/2208.11970 for that derivation and they also explain later problems because of this on Page 9. But now we would end up with the task of computing expectation over samples of two random variables, xt-1 & xt+1(high variance) drawn from joint distribution q(xt-1, xt+1 | x0) (which we dont know how to compute). This is simplified when we add the x0 conditioning which we see later in the video, with expectation now over samples of one random variable xt drawn from q(xt|x0) and what we end up is something we can easily compute. In the tutorial I linked, this change is done on Page 9
@@Sherlock14-d6x Thats because at each timestep you are destroying the original structure a bit and adding a noise component. If you look @7:15 in video, you can see that the original values were in range -6 to 6 but that didnt matter as we continued destroying the original structure and adding noise repeatedly we had a normal distribution @7:25
I derived the whole equation for reverse diffusion process and at 21:26 in the last term of equation in the last line, I did not get \sqrt{\alpha t - 1}. Could you share the complete derivation? Also, the third last line seems to be incorrect, it should be (\alpha t - 1) instead of (\alpha t - 1)^2
Hello, yes the square on \bar{\alpha_(t-1)} is a mistake which gets corrected in the next line. But thank you for pointing that out! Regarding the last term in last line, just wanted to mention that its \bar{\alpha_(t-1)} which is just coming from rewriting \bar{\alpha_(t)} from the last term in second last line as \alpha_t * \bar{\alpha_(t-1)} .
I haven’t yet given it a try. I started with canva for the first video and found was able to do everything that I wanted to( in terms of animations ), so just kept using that only.
Your explanation is really easy to understand. I have one request. Can you make one video on any virtual try on. On models like dior or tryondiffusion who give good results. Paper explanation and implementation both will really help. I am trying understand them over a month but still couldn't understand anything.
28:11 The algorithm for sampling, namely step 4, looks a lot different than what you explain. Why is that? To me, it looks like they take the predicted noise from xt, do a lil math to it, then subtract it from xt, then add a lil noise to it to get xt-1. You kinda just ran through it like it was nothing, but it doesn't look the same at all.
Hello, Do you mean the formulation of mu + sigma*z and Step 4 of Sampling ? They both are actually the same and just require taking sqrt(xt) term out and simplifying the second term. Have a look at this - imgur.com/a/LJL73z1
Yes, in theory the forward process and the reverse process is the same given the process is a Weiner Process(Brownian motion). Intuitively, if you have a microscopic view of a Brownian motion, the forward and the reverse process looks similar (i.e. random). th-cam.com/video/XCUlnHP1TNM/w-d-xo.html
In the reverse process, at each time step we have a distribution (P(xt-1|xt)), which is a gaussian(N(mu_t-1, sigma)). We use the prediction of noise at each timestep to compute the predicted mean, mu_theta. The adding noise part is actually reparameterization trick to sample from the predicted P(xt-1) distribution. Which is why we sample a random noise z, shift it by the mean of this predicted distribution and then scale it by sigma. Also, if we straightaway use mu_theta(so always return mean instead of reparameterization trick to sample from P(xt-1)), then the entire reverse process would end up being deterministic.
If you don't add enough noise in each step, then the final distribution(assuming same number of steps) would not really be gaussian(in fact it would still have some original image structure). So the model wouldnt be able to generate images, because during generation you would be asking the model to denoise a random sample(from gaussian distribution), which it would have never seen during training, and hence samples generated by this model would most likely be non-meaningful images.
@@Explaining-AI After training, we expect diffusion model to output random samples (similar to original distribution) from arbitrary noise. I mean that we don't run the forward process anymore after training. In that case, what can lead to non-meaningful image generation?
@@MediocreGuy2023 Yes you are right, but we expect the model to be able to do the reverse(gaussian to original distribution) ONLY if the forward process end state is indeed gaussian. But in your specific case, when enough noise is not added in forward process, the distribution at end state after 1000 timesteps wont really be gaussian( it will be some other distribution D). We can expect the model to do the reverse only if the starting point is a sample from D, but since we dont know D, we cant sample from D. And a sample from gaussian(which we usually do during inference) when fed as starting point of the reverse process, will not be something the model has ever seen during training, so doesn't know how to go from xT to xT-1 with this sample.
Hello @GouravJoshi-z7j, I think this list covers the pre-requisites . Gaussian Distribution and its properties .......Mean/variance of adding two independent gaussians Reparameterization trick Maximum Likelihood Estimation Variational Lower Bound Bayes theorem, conditional independence KL Divergence, KL divergence between two gaussians VAE(cause the video incorrectly assumes knowledge about it) I may have missed something so in case there is some aspect of the video that you aren't able to understand even after that please do let me know
Great video, but as feedback, I'd suggest to breath and pause a bit after each bigger step. You're jumping between statements really fast, so you don't give people to think a little bit about what you just said.
i have a doubt at this timestamp: th-cam.com/video/H45lF4sUgiE/w-d-xo.htmlsi=mzOMzB0uACX8mPd6&t=528 - when you do summation of GP - wont the common factor be sqrt(1-beta)? - hence the final summation equation seems wrong to me. need some help to understand that formulation. captions during the time stamp: ... the rest of the terms are all gaussian with zero mean but different variances however since all are independent we can formulate them as one gaussian with mean zero and variance as sum of all individual variances. Thanks
Hello yes while the factors being multiplied to each zero mean unit variance gaussians are indeed sqrt(B), sqrt(B * (1-B)) and so on. But this means that each of the terms individually are gaussians with variances B, (B * (1-B)) and so on. The sum of these gaussians will be a gaussian with variance B + (B * (1-B)) + B(1-B)(1-B) ... and zero mean. The GP that I am referring to is for these summation of variances and hence when I use the formulation, I use terms B and 1-B rather than sqrt(B) and sqrt(1-B) , to say the final gaussian will be a zero mean and unit variance gaussian as the summation of variances(using the summation of GP) is 1 Let me know if this clarifies your doubt
@@Explaining-AI did not full understand this - "The sum of these gaussians will be a gaussian with variance B + (B * (1-B)) + B(1-B)(1-B) ... and zero mean." So I did some digging around it, the key point is this: Sum of two independent normally distributed random variables is normal (+ your explanation in the video about Markov processes helped) Proof: en.wikipedia.org/wiki/Sum_of_normally_distributed_random_variables#Proof_using_convolutions This allows you to combine all the terms together as distributions and not algebraic terms. I think i get it now. Let me know if my interpretation is lacking something. Thanks
@@SagarSarkale Yes. Sorry, I should have clarified this a bit more in the video. Just to add more details for somebody else reading it. Since if X and Y are independent random variables each drawn from gaussian distributions, X+Y is also a gaussian distribution which has mean as sum of their means and variance as sum of individual variances. The means of all gaussian distributions here are 0. The distribution created by summing all these terms(each of which are generated by 0 mean and some variance) will be another gaussian with mean as 0 and variance as sum of these variances. To compute this variance we use that GP formula which ends up proving that the variance is 1.
Thank you for this question. I don't think the noise distribution MUST be normal. There are papers which have experimented with non-gaussian distributions. Like in arxiv.org/pdf/2106.07582 the authors experiment with Gamma distributions, In arxiv.org/pdf/2304.05907 , authors experiment with Uniform and few other distributions with the aim to determine which noise distribution leads to better generated data. In DDPM, the authors used gaussian noise. What were the exact reasons of using gaussian noise only. I dont really know the answer to that. From the perspective of the model being a markov chain of latent variables, a lot of simplifications occur because the noise is gaussian. For instance the property of adding two gaussian distributions leading to another gaussian, enables us to sample states at any timesteps in the markov chain without worrying about all previous time steps(xt in terms of x0 rather than xt-1). But apart from the math being simpler, is there any advantage of using gaussian noise over non-gaussian noise purely in terms of generation results(and if so why?) and under what condition(if any) a non-gaussian noise is better? Unfortunately, I don't know the answer to these yet. If you come across more information on this particular topic, please do share here.
Yes this one indeed has a lot of math required for understanding it which is why I tried to put forth every detail :) Though maybe I could have done a better job presenting it in a better/simpler manner.
Hello, That number was just for diffusion as for 4-5 weeks all I was doing during the day(dont work as of now ) was understanding diffusion. And then post that, implementation. And I give myself ample time to understand things at my own speed, so somebody else can understand the same rather much more/better in lesser time :) But that number was just a means to express on scale as to how much I don't know still and how the video is just my current understanding of it all. Nothing more than that!
@@Explaining-AI Thanks for the reply. I also try to time myself during learning. As I think a definite number (lower bound) is required to build the concepts of any topic. That's why I was curious if 500 hours was a calculative number as Andrej Karapathy in his blogs also recommends an average figure of 10,000 hours to become a good beginner in Machine learning.









*Github Code* - github.com/explainingai-code/DDPM-Pytorch
*DDPM Implementation Video* - th-cam.com/video/vu6eKteJWew/w-d-xo.html
Note:
There’s a typo at 19:49, in the denominator, for the variance, instead of cumulative product of alphas till t-1, it should be cumulative product of alphas till t.
So \bar{\alpha}_t instead of \bar{\alpha}_{t-1}
without a doubt the best video ever made on the subject of DDPM. Even better than the original paper. Thank you very much for that. ❤
I am truly humbled by your generous comment(brought a big smile to my face :) ).
Thank you so much for the kind words.
I can’t genuinely agree more ❤️
After spending one month in web/youtube reading blogs, watching videos finally I got this GEM. Its the best explanation on the mathematics from entire universe. It took me 10 days to grasp all these excellent mind blowing thoughts behind the DDPM. Kudus to you. Keep posting on recent topics.
Thank you for these kind words :) Yes I definitely plan to keep posting videos on both recent as well as slightly older (but still relevant) topics
Thanks for this wonderfully intuitive video! It provided a fantastic breakdown of the fundamentals of diffusion models. Let me try to answer your question about why the reverse process in diffusion models is also a (reverse) diffusion with Gaussian transitions.
Why Reverse Diffusion Uses Gaussian Transitions
1. Forward Diffusion Introduces Noise Gradually
Remember the β term? In the forward process, β is chosen to be very small (close to 0). This ensures that Gaussian noise is added gradually to the data over many steps. Each step introduces only a tiny amount of noise, meaning the transition from the original image to pure noise happens slowly and smoothly.
This gradual noise addition is crucial because it preserves the structure of the data for longer, making it easier for the reverse process to reconstruct high-quality images. If we added large amounts of noise in one go, like in VAEs, the original structure would be harder to recover, leading to blurrier reconstructions.
2. Reverse Diffusion Needs "Gaussian-Like" Inputs
The forward process only involves adding isotropic Gaussian noise at each step. This means the model learns to work with samples that are progressively noised in a Gaussian way. However, in the reverse process, when the model predicts the noise at each step, the resulting sample isn't guaranteed to remain Gaussian-like.
To fix this, after subtracting the model's predicted noise, we add a small Gaussian noise with a carefully chosen variance. This step helps "Gaussianize" the sample, ensuring it aligns with what the model expects at the next time step. This small added noise smoothens any irregularities and makes the reverse process more stable, resulting in higher-quality outputs.
Step-by-Step Noise Removal
The reverse process works by removing noise step-by-step, moving from pure noise back to a clean image (closer to x0 ). This gradual approach is crucial because predicting small changes (i.e., removing a little noise at a time) is much easier for the model than trying to reconstruct the clean image in one big jump. This is why diffusion models produce sharper and more realistic images compared to VAEs, where predictions often result in blurry outputs due to the lack of such gradual refinement.
That is the best video that i have watched about teaching the diffusion model.
Thank you :)
wow the 2d guassian demo is insanely helpful, please continue doing these over-simplified animations!
Thank you so much for your support! I’m really glad you found the video helpful. :)
Hi Gabriel, just yesterday I sent a message to you on twitter. Right now I'm finding you here in comment section.
Best explnation of Denoising Diffusion Probabilistic Models!
I find it the best source for ddpm maths on web, it took me a week to watch this video. Keep uploading theses kind of math derivations video
Thanks
Awesome explanation, Thanks!
I watched your video again, and cannot give you enough compliments on it! Great job!
@bayesianmonk Thank you so much for taking the time to comment these words of appreciation(that too twice) 🙂
Thanks man, this really helped clear some fundamental doubts which remained even after going through multiple articles on DDPMs. Terrific job!
This is a great video, i completely understood till "Simplifying the Likelihood for Diffusion Models". I'll need to replay multiple times but the video is very helpful..
Please make more such video diving into maths. Most youtubers leave out the maths part while teaching DL part which is crazy because it's all math.
Thank you for saying that! And Yes the idea is to dive into that as doing that also gives me the best shot at ensuring I understand everything.
Wow! This is an incredibly clear explanation of the complex mathematics behind DDPM. Thank you so much, Tushar! This video is a real gem. The formulas may seem intimidating at first, but it's amazing how such a complex model can be derived from a fundamentally simple idea.
Thank You for this :)
Best explanation of diffusion process with connection to VAE process!
Thank you for the kind words!
Absolutely! Bringing VAE really helped me understand the concept in a clearer way.
Definitely the best explanation I've ever seen on this topic. Keep it up! :)
Thank You!
I don't have enough words to describe this masterpiece. VERY WELL EXPLAINED. Thanks. :)
Thank you so much for this appreciation :)
Beautiful video, the efforts put in making it must have been enormously huge, Thanks a lot!!!
Thank you for the appreciation :)
I think there’s a typo at 19:49, in the denominator the variance would be \sqrt(1-\bar{\alpha}_t)I instead of \sqrt(1-\bar{\alpha}_{t-1})I
Yes you are right. It should be \bar{\alpha}_t instead of \bar{\alpha}_{t-1}. Its correct in the next step but I messed up in the starting expression. Thank You. Have now added this error to pinned comment.
Thanks. Many interesting nuggets that I had missed from reading the paper.
Great Video! It was very helpful to understand DDPM ! Thank you so much ! : )
Thank you :) Glad that the video was helpful to you!
Hi, Very good attempt of explaining the DDPM, and thank you for sharing the information. Kudos! to answer your question at 14:22 (why reverse process is the diffusion?) because while reverse process, after the prediction of noise by u-net we check for the condition whether it is at t=0(x0-original image state) our output would be mean(has same shape of image) or not, if we are not at t=0 then our output would be mean+variance (with this variance we are adding noise again - based on x0). Hope this helps!
You sure you're answering the question? You're talking about an implementation detail. Could you please elaborate on the mathematical intuition?
I learnt maths of DM from this lecture. Thank you
14:30 actually the reason we model reverse process also as gaussian is that the distribution q(x_t-1|xt, x0) is gaussian with certain mean and variance. (can be derived using bayes rule not very high level math there) notice that its conditioned not only on xt but also on x0. But in theory p(x_t-1|xt) is the reverse process distribution. Hence we can't say that reverse process is also gaussian. we are just assuming/approximating it
Superb, the math doesn't looks all that scary after your explanation! Now I just need pen an paper to sink it in.
Thank You!
This video was absolutely amazing!
Also giving yourself a rating of 0.05 after spending 500 hrs on a topic is crazy(Not that I would know, because I am about a 0.0005 according to this scale)
Waiting eagerly for the next one!
Thank you so much! the scale was more to indicate how much I don't know(yet)😃
Have already started working on Part 2 of Stable Diffusion Video so that should soon be out.
Great video thank you ! Some maths would need more explanation though such as at 12:59 where you assume espilon(t), epsilon(t-1),...,espilon(0) are all the same and factorize by a new term named espilon.
Thanks! and I agree with you. In hindsight if I made the video again, I think it would be over an hour long atleast, because there are few aspects that I now think I could/should have gone in more detail.
Regarding the epsilon terms, I did talk a bit about this briefly @12:16, where I mention that this can be done because sum of two independent gaussian random variables remains a gaussian with mean and variance being the sum of both the means and variances.
excellent, clear explanation of diffusion
Thank You!
We making it outta the hood with this tutorial🗣🔥💯
Thank you for this fantastic video on DDPMs, it was super helpful. One thing I'm having trouble understanding is the derivation at 12:29, how can we go from the 3rd line to the 4th line on the right side. I mean this part:
sqrt(alpha_t - alpha_t * alpha_{t-1}) * epsilon_{t-1} + sqrt(1 - alpha_t) * episolon_t
...to the next line where we combined these two square roots:
sqrt(1 - alpha_t * alpha_{t-1}) * epsilon
?
In the third line, just view the epsilon terms as samples from gaussian with 0 mean and some variance. So the two epsilon terms in third line is just adding two gaussians. Then we use the fact that sum of two independent gaussians ends up being a gaussian with mean as sum of the two means(which here for both is 0) and variance as sum of the two variances. Which is why we can rewrite it in the 4th line as a sample from a gaussian with 0 mean and variance as sum of the individual variances present in third line. Do Let me know if this clarifies it.
@@Explaining-AI yes perfectly! Thank you for the quick response, that makes sense :)
Hey, very helpful video. I'm making a project for our image processing course on diffPIR paper, this video explains everything in sequence. All the bad calculation missed in my paper is explained and with proper intuition very nicely thanks👍
Edit: just one question what about the term E[log(p(x_0|x_1))], what is the idea behind it, does the model minimize it?
Thank you! This term is the reconstruction loss which is similar to what we have in vae's. Here its measure that given a slightly noisy image x1(t=1), how well the model is able to reconstruct the original image x0 from it. In an actual implementation this is minimized together with the summation terms itself. So during training instead of uniformly sampling timesteps from t=2 to t=T(to minimize the summation terms), we sample timesteps from t=1 to t=T, and when t=1 , the model is learning to denoise x1 (rather reconstruct x0 from a noisy x1). The only difference happens during inferencing, where at t=1, we simply return the predicted denoised mean, rather than returning a sample from N(mean, scheduled variance) which we do for t=2 to t=T.
hey good explanantion. At timestep 19:42 aren't the square roots of all Covariance matrices missing. Please correct me if I am wrong.
Thank You! Do you mean that variance should be sqrt(1- alpha_t) ?
If you see the formulation for xt @12:00 then you can see that xt = sqrt(alpha_t) x_(t-1) + sqrt(1- alpha_t)e where e is mean zero and variance 1. Which means sqrt(1- alpha_t)e will have mean 0 and variance (1-alpha_t) which is what is used @19:42
Let me know if I misunderstood your question.
@@Explaining-AI At 28:18 why are we just returning the mean in the last step, is the variance value 0 for timestep t=0
At 4:27 In the definition of the dXt, it is mentioned random mean and zero variance, but at bottom when you do the re-parameterization, N(0, I) is mentioned i.e. zero mean and unity variance. Isn't that different than the defination?
I think there is a comma missing(sorry about that confusion) , it should actually be ''random, mean zero & variance µ(Xt, t)dt"
The last term needs to have mean zero and variance µ(Xt, t)dt .
@@Explaining-AI Thanks for the clarification
Damn, really earned that sub! Great work :)
I had a doubt. At 17:11 if we had removed this x0 term we would have gotten stuck ahead, and the ground truth reverse function and the approximat ng reverse function would effectively be representing the same thing as both don't have the information of x0. Am I right in saying this?
I just wanted to kow for an image how will the end result be a normal distribtuion with mean 0 considering it has valeues between o and 1 after normlaized
At 28:11 isn't it good to predict the computed noise, all with the timestep
If we dont use the x0 conditioning then what we could get is KL divergence between q(xt|xt-1) and p(xt | xt+1)
You can take a look at Page 8 of this tutorial - arxiv.org/pdf/2208.11970 for that derivation and they also explain later problems because of this on Page 9.
But now we would end up with the task of computing expectation over samples of two random variables, xt-1 & xt+1(high variance) drawn from joint distribution q(xt-1, xt+1 | x0) (which we dont know how to compute).
This is simplified when we add the x0 conditioning which we see later in the video, with expectation now over samples of one random variable xt drawn from q(xt|x0) and what we end up is something we can easily compute.
In the tutorial I linked, this change is done on Page 9
@@Sherlock14-d6x Thats because at each timestep you are destroying the original structure a bit and adding a noise component. If you look @7:15 in video, you can see that the original values were in range -6 to 6 but that didnt matter as we continued destroying the original structure and adding noise repeatedly we had a normal distribution @7:25
@@Sherlock14-d6x Sorry I didnt get this question. Could you elaborate a bit
Amazing tutorial! Thanks for putting this up. Waiting for the stable diffusion video. When can we expect that? :)
Thank you @himanshurai6481 :) It will be the next video that gets uploaded on the channel.. will start working on that from tomorrow.
@@Explaining-AI looking forward to that :)
reeeeeeeeally appreciate
I derived the whole equation for reverse diffusion process and at 21:26 in the last term of equation in the last line, I did not get \sqrt{\alpha t - 1}.
Could you share the complete derivation? Also, the third last line seems to be incorrect, it should be (\alpha t - 1) instead of (\alpha t - 1)^2
Hello, yes the square on \bar{\alpha_(t-1)} is a mistake which gets corrected in the next line. But thank you for pointing that out!
Regarding the last term in last line, just wanted to mention that its \bar{\alpha_(t-1)} which is just coming from rewriting \bar{\alpha_(t)} from the last term in second last line as \alpha_t * \bar{\alpha_(t-1)} .
@@Explaining-AI Ahh yes, ignorant me. Thank you for your time in deriving the equations. I did not find this derivation any where else yet :)
Amazing video, thanks a lot for all the effort you put in this. Just out of curiosity what do you use for the animation of the formulas?
Thank you for the kind words! For creating the equations I use editor.codecogs.com and then use Canva for all the animations
I thought you were using manim@@Explaining-AI
I haven’t yet given it a try. I started with canva for the first video and found was able to do everything that I wanted to( in terms of animations ), so just kept using that only.
Your explanation is really easy to understand. I have one request. Can you make one video on any virtual try on. On models like dior or tryondiffusion who give good results. Paper explanation and implementation both will really help. I am trying understand them over a month but still couldn't understand anything.
Thank you! Yes will add it to my list. It might take some time to get to it but whenever I do it I will have both explanation and implementation.
@@Explaining-AI Thank you Tushar
Wow this was awesome!!
Thank you
28:11 The algorithm for sampling, namely step 4, looks a lot different than what you explain. Why is that? To me, it looks like they take the predicted noise from xt, do a lil math to it, then subtract it from xt, then add a lil noise to it to get xt-1. You kinda just ran through it like it was nothing, but it doesn't look the same at all.
Hello, Do you mean the formulation of mu + sigma*z and Step 4 of Sampling ?
They both are actually the same and just require taking sqrt(xt) term out and simplifying the second term. Have a look at this - imgur.com/a/LJL73z1
@@Explaining-AIThank you, now I remember. Shift and scale. :)
Yes, in theory the forward process and the reverse process is the same given the process is a Weiner Process(Brownian motion). Intuitively, if you have a microscopic view of a Brownian motion, the forward and the reverse process looks similar (i.e. random). th-cam.com/video/XCUlnHP1TNM/w-d-xo.html
Thank you for sharing the video link
Explanation of this paper, i can only say "just like woow.."❤
Amazing video! Thanks
Amazing job, I'm studyinh DDPMs for my thesis and this is the best resource you can find by far!
Thank You :)
Mazaa aa gaya Tushar bhai!
Thank you 😀
Legendry video
Appreciate your hard work🎉
Thank you for that :)
This is a great video! Thanks!
Thank you! Glad that the video was of any help
Can you tell me what is the exact move of adding noise to each pixels? Why is the process a distribution? Shouldn’t it be a certain function?
Very Nice! Keep the good word going!!
Thank You!
Nice explanation..!
Thank You!
In the sampling algorithm (algo 2), I don't understand why we have to add noise z back in. Can anyone explain this to me?
In the reverse process, at each time step we have a distribution (P(xt-1|xt)), which is a gaussian(N(mu_t-1, sigma)). We use the prediction of noise at each timestep to compute the predicted mean, mu_theta. The adding noise part is actually reparameterization trick to sample from the predicted P(xt-1) distribution. Which is why we sample a random noise z, shift it by the mean of this predicted distribution and then scale it by sigma.
Also, if we straightaway use mu_theta(so always return mean instead of reparameterization trick to sample from P(xt-1)), then the entire reverse process would end up being deterministic.
@Explaining-AI that makes sense, thank you very much!
So why the reverse process is also a diffusion process with the same Gaussian form? Does anyone know 😢
the reverse process can't be computed. As the process we are doing is not reversible. Can be derived using Non linear dynamics.
Can you tell what will happen if enough noise is not added in the forward process?
If you don't add enough noise in each step, then the final distribution(assuming same number of steps) would not really be gaussian(in fact it would still have some original image structure).
So the model wouldnt be able to generate images, because during generation you would be asking the model to denoise a random sample(from gaussian distribution), which it would have never seen during training, and hence samples generated by this model would most likely be non-meaningful images.
@@Explaining-AI Thanks for your help. I understood some parts of your reply.
@@MediocreGuy2023 Which specific part you had difficulty in understanding ? I can try rephrasing that to clarify it a bit more.
@@Explaining-AI After training, we expect diffusion model to output random samples (similar to original distribution) from arbitrary noise. I mean that we don't run the forward process anymore after training. In that case, what can lead to non-meaningful image generation?
@@MediocreGuy2023 Yes you are right, but we expect the model to be able to do the reverse(gaussian to original distribution) ONLY if the forward process end state is indeed gaussian. But in your specific case, when enough noise is not added in forward process, the distribution at end state after 1000 timesteps wont really be gaussian( it will be some other distribution D). We can expect the model to do the reverse only if the starting point is a sample from D, but since we dont know D, we cant sample from D. And a sample from gaussian(which we usually do during inference) when fed as starting point of the reverse process, will not be something the model has ever seen during training, so doesn't know how to go from xT to xT-1 with this sample.
why gussian noise only added. Not Rician, Laplacian etc.. there are so many other probability distribution.
Hello, have replied to something similar here(highlighted comment) - th-cam.com/video/H45lF4sUgiE/w-d-xo.html&lc=Ugznn1UksOPa3NfWLXR4AaABAg
I am new to this field can anyone provide me with the prerequisites to understand this video
Hello @GouravJoshi-z7j, I think this list covers the pre-requisites .
Gaussian Distribution and its properties
.......Mean/variance of adding two independent gaussians
Reparameterization trick
Maximum Likelihood Estimation
Variational Lower Bound
Bayes theorem, conditional independence
KL Divergence, KL divergence between two gaussians
VAE(cause the video incorrectly assumes knowledge about it)
I may have missed something so in case there is some aspect of the video that you aren't able to understand even after that please do let me know
Great video, but as feedback, I'd suggest to breath and pause a bit after each bigger step. You're jumping between statements really fast, so you don't give people to think a little bit about what you just said.
Thank you so much for this feedback, makes perfect sense. Will try to improve on this in the future videos.
Just pause the video dude. I love the tempo, keep it coming
Bhai Hats off
Thank you!
i have a doubt at this timestamp: th-cam.com/video/H45lF4sUgiE/w-d-xo.htmlsi=mzOMzB0uACX8mPd6&t=528
- when you do summation of GP
- wont the common factor be sqrt(1-beta)?
- hence the final summation equation seems wrong to me. need some help to understand that formulation.
captions during the time stamp:
... the rest of the terms are all gaussian with zero mean but different variances however since all are independent we can formulate them as one gaussian
with mean zero and variance as sum of all individual variances.
Thanks
Hello
yes while the factors being multiplied to each zero mean unit variance gaussians are indeed sqrt(B), sqrt(B * (1-B)) and so on.
But this means that each of the terms individually are gaussians with variances B, (B * (1-B)) and so on. The sum of these gaussians will be a gaussian with variance B + (B * (1-B)) + B(1-B)(1-B) ... and zero mean.
The GP that I am referring to is for these summation of variances and hence when I use the formulation, I use terms B and 1-B rather than sqrt(B) and sqrt(1-B) , to say the final gaussian will be a zero mean and unit variance gaussian as the summation of variances(using the summation of GP) is 1
Let me know if this clarifies your doubt
@@Explaining-AI
did not full understand this - "The sum of these gaussians will be a gaussian with variance B + (B * (1-B)) + B(1-B)(1-B) ... and zero mean."
So I did some digging around it, the key point is this:
Sum of two independent normally distributed random variables is normal (+ your explanation in the video about Markov processes helped)
Proof: en.wikipedia.org/wiki/Sum_of_normally_distributed_random_variables#Proof_using_convolutions
This allows you to combine all the terms together as distributions and not algebraic terms. I think i get it now.
Let me know if my interpretation is lacking something.
Thanks
@@SagarSarkale Yes. Sorry, I should have clarified this a bit more in the video. Just to add more details for somebody else reading it. Since if X and Y are independent random variables each drawn from gaussian distributions, X+Y is also a gaussian distribution which has mean as sum of their means and variance as sum of individual variances. The means of all gaussian distributions here are 0. The distribution created by summing all these terms(each of which are generated by 0 mean and some variance) will be another gaussian with mean as 0 and variance as sum of these variances. To compute this variance we use that GP formula which ends up proving that the variance is 1.
@@Explaining-AI Yes. Thanks for the detailed reply and ofcourse the video much help. 🙌
Why does the noise need to be normal? Can't it be uniform?
Thank you for this question. I don't think the noise distribution MUST be normal. There are papers which have experimented with non-gaussian distributions. Like in arxiv.org/pdf/2106.07582 the authors experiment with Gamma distributions, In arxiv.org/pdf/2304.05907 , authors experiment with Uniform and few other distributions with the aim to determine which noise distribution leads to better generated data.
In DDPM, the authors used gaussian noise. What were the exact reasons of using gaussian noise only. I dont really know the answer to that.
From the perspective of the model being a markov chain of latent variables, a lot of simplifications occur because the noise is gaussian. For instance the property of adding two gaussian distributions leading to another gaussian, enables us to sample states at any timesteps in the markov chain without worrying about all previous time steps(xt in terms of x0 rather than xt-1).
But apart from the math being simpler, is there any advantage of using gaussian noise over non-gaussian noise purely in terms of generation results(and if so why?) and under what condition(if any) a non-gaussian noise is better? Unfortunately, I don't know the answer to these yet.
If you come across more information on this particular topic, please do share here.
@@Explaining-AI I'm not an expert in ML, but I tried using uniform distribution as noise. Here's what I found. Consider
x_(t+1) = a*x_t+(1-a)*u, 0
crazy stuff
bruh my brain is exploding from the math😅
Yes this one indeed has a lot of math required for understanding it which is why I tried to put forth every detail :) Though maybe I could have done a better job presenting it in a better/simpler manner.
now do flow matching
Added this one to my list :)
The quality of the writings too poor to see the equations
Amazing, but please remove the background music.
Yeah, I have gotten that feedback of background music being distracting. Sorry about that.
Have taken care of this in my recent videos.
Hi, did you count 500 hrs as in only on diffusion? Or including previously learned concepts like VAEs, ELBO, KLD etc ?
Hello,
That number was just for diffusion as for 4-5 weeks all I was doing during the day(dont work as of now ) was understanding diffusion. And then post that, implementation. And I give myself ample time to understand things at my own speed, so somebody else can understand the same rather much more/better in lesser time :)
But that number was just a means to express on scale as to how much I don't know still and how the video is just my current understanding of it all. Nothing more than that!
@@Explaining-AI Thanks for the reply. I also try to time myself during learning. As I think a definite number (lower bound) is required to build the concepts of any topic. That's why I was curious if 500 hours was a calculative number as Andrej Karapathy in his blogs also recommends an average figure of 10,000 hours to become a good beginner in Machine learning.
@@Explaining-AI Super cool!