Anybody can speak fluff about SVD with 30 pages of incomprehensible lecture notes. This guy can explain it in 10 minutes. If you don't can't explain it simply, you don't understand it well enough -- Einstein. Saving my life 10 minutes at a time, thanks Steve!
Amazing lecture series! Thank you so much for putting the link to the paper in the description. You really go the extra kilometer! It is very much appreciated!
How is this freely available?!! 😀Easy to understand, informative, high production values, and includes code and a free link to the whole textbook. Awesome, awesome resource.
Hey - looking at this. Based on that paper, and if there are key elements (sigmas) that lie below (rely on data below) the noise floor, this may be an illustration as to why AI at a given layer will not get any better that a certain precision. Then after that how a piecewise linear model also at each stage and as a whole may not get better than a certain precision. We renormalize to get accuracy at each layer, and get precision by forcing a collapse of the value range (relu or tanh) to rail the data at each layer. maybe?
Thanks for the video! The proofs in the paper by Gavish and Donoho are a bit complicated to understand, can you provide some intuition or know a source that does? Thanks in advance.
It seems like NMF might be the perfect way to segue from PCA and SVD into non-convex optimization problems and how to utilize initialization, constraints, and regularization in order to get reasonable solutions. I would be forever grateful if you did this.
Excellent video, thank you very much for this. I have comment/question on the Gavish-Donoho hard threshold. It's clearly powerful when you know that the "signal part" of your matrix X is low rank (which is how it's being used here and how people would use it in practice), but it doesn't seem to help you verify this assumption. In the extreme case of a full rank signal matrix all singular values would probably end up just above/at/below the noise floor (given the assumption that the median singular value is "noise"), or am I missing something? Thank you again.
Thanks Steve ... i have seen a matrix formed as below and need to know what is this and how its formed . A(perp) = VD(transpose)UT Ax=b Then W(best vector)= A(perp)b = (ATA)-1ATb
I'm quite confused with beta, do I choose m and n depending on which is larger? Gavish and Donoho mentioned in their paper that B = m/n, but with a matrix of 65025 (m) by 768 (n) in my case, the value I'm getting is pretty large
Unfortunately not at this point. We have thought about porting to R, but haven't had the time yet. One of our papers on randomized SVD is in R: github.com/erichson/rSVD
At this point th-cam.com/video/9vJDjkx825k/w-d-xo.html there are two equality signs in the line of writing. I do not understand why this is valid. It seems to be an approximation.

![SVD: Optimal Truncation [Matlab]](http://i.ytimg.com/vi/u4LG9z4AAdM/mqdefault.jpg)
![SVD: Optimal Truncation [Matlab]](/img/tr.png)

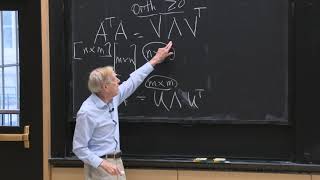





Anybody can speak fluff about SVD with 30 pages of incomprehensible lecture notes. This guy can explain it in 10 minutes.
If you don't can't explain it simply, you don't understand it well enough -- Einstein.
Saving my life 10 minutes at a time, thanks Steve!
I have gained so much more intuitive understanding of SVD from watching your series. Thank you.
This is one of the best explanation you can get on SVD. Thank you Steve.
Thanks Steve. You have really simplified application of SVD. Very useful lecture series
Thank you so much for this series Steve. It's such an elaborate, simple and informative overview of SVD.
Amazing lecture series!
Thank you so much for putting the link to the paper in the description. You really go the extra kilometer! It is very much appreciated!
Most amazing lecture series on SVD, I have ever had !! Thankx :)
How is this freely available?!! 😀Easy to understand, informative, high production values, and includes code and a free link to the whole textbook. Awesome, awesome resource.
Thank you so much for this content. I would love to see a video from you on the generalized SVD...
That was so cool! Fascinating insights.
Hey - looking at this. Based on that paper, and if there are key elements (sigmas) that lie below (rely on data below) the noise floor, this may be an illustration as to why AI at a given layer will not get any better that a certain precision. Then after that how a piecewise linear model also at each stage and as a whole may not get better than a certain precision. We renormalize to get accuracy at each layer, and get precision by forcing a collapse of the value range (relu or tanh) to rail the data at each layer. maybe?
Thanks for the video! The proofs in the paper by Gavish and Donoho are a bit complicated to understand, can you provide some intuition or know a source that does? Thanks in advance.
It seems like NMF might be the perfect way to segue from PCA and SVD into non-convex optimization problems and how to utilize initialization, constraints, and regularization in order to get reasonable solutions. I would be forever grateful if you did this.
Excellent video, thank you very much for this. I have comment/question on the Gavish-Donoho hard threshold. It's clearly powerful when you know that the "signal part" of your matrix X is low rank (which is how it's being used here and how people would use it in practice), but it doesn't seem to help you verify this assumption. In the extreme case of a full rank signal matrix all singular values would probably end up just above/at/below the noise floor (given the assumption that the median singular value is "noise"), or am I missing something? Thank you again.
What a great lecture! Thank you so much, I'll definitely check out your other lectures too!
Why can we use cross-validation for selecting the optimal value of r?
Thank you Sir for your videos. They are very helpful!!
Thanks Steve ... i have seen a matrix formed as below and need to know what is this and how its formed .
A(perp) = VD(transpose)UT
Ax=b
Then W(best vector)= A(perp)b = (ATA)-1ATb
I'm quite confused with beta, do I choose m and n depending on which is larger? Gavish and Donoho mentioned in their paper that B = m/n, but with a matrix of 65025 (m) by 768 (n) in my case, the value I'm getting is pretty large
Thanks Steve! In addition to Matlab and Python code, is there R code available for the Data-Driven Science and Engineering book?
Unfortunately not at this point. We have thought about porting to R, but haven't had the time yet. One of our papers on randomized SVD is in R: github.com/erichson/rSVD
Can this be applied to NMF? Can it (or is it) somehow be incorporated into the nndsvd initialization?
thanks
How did we get this form of matrix btw?
Why did we say X = USVt ?
Why not something like X = ABCDE or something else?
is there any link for code
all code at databookuw.com
Thank you!
At this point th-cam.com/video/9vJDjkx825k/w-d-xo.html there are two equality signs in the line of writing. I do not understand why this is valid. It seems to be an approximation.
Anyone else trying to write backwards in a piece of paper after watching this video??
Wait a minute, does this guy writes perfectly backwards? what the F is going on??