this demo is good but there are two things missing here. only the incremental data should be loaded in redshift when the job runs again. in your case there is duplication. another thing u could have shown is making changes on the fly in the excel sheet which invokes the crawler and automatically runs a job.
Thank you for watching my videos. These are indeed valuable inputs. I am planning to make next version of this video where these inputs are taken care. Keep watching and Happy learning.
Thank you for watching my videos. I have set Infrastructure using manually here. But its good idea to keep this infrastructure with using Infrastructure as Code i.e Terraform. I shall keep in mind this in my next video
Thank you for watching my videos. The current capability of aws glue crawlers needs to create multiple points of crawlers when you have multiple tables.
Thank you for watching my videos. This really a good question. The method shown in this video is using complete aws given service (Glue crawlers) to extract, load and transform, whereas COPY commond is using SQL method by connecting to RDS and uploads the data.
Appreciate yuor efforts! But you have not explained the significance of creating reshift crawler, why security group required with the same name... I would request you to go step by step for making this things better understand.. Patience!
it was a good demo ...thank you so much. just a small question . Why we didn't use S3 trigger destination to Lambda function if new file is added or update instead of EventBridge ?
Thank you for watching my videos. This is custom solution that designed here. But Indeed we can use S3 object create event to trigger the workflow as well.
Hi, @cloudquicklabs What was the use of second crawler. Is it only run once to get schema of redshift in to temp database and later it won't be running any time?
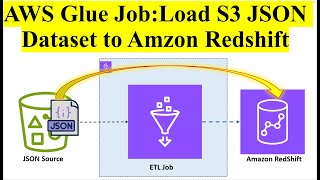
Thank you for watching my videos. It's to load the data from s3 to aws glue data catalog and then to Amazon Redshift services. Did you watch the second version of this video th-cam.com/video/RGSKeK9xow0/w-d-xo.htmlsi=FB_1BXVQp-SnfUtq
I am getting "Account *** is denied access" while creating crawlers. I tried signing in afresh. It's not helping. Also, while modifying inbound rules for security groups i selected allow all for the types.
Thank you for watching my videos. May be AWS might have disabled crawler or ETL job in your account , just raise service quota limit or raise support case should help you.
Hi when exactly do I need to set up a route table and NAT Gateway for using glue? Can you elaborate on that? I can also use glue and crawlers without the route table as long as the roles are correct? Thanks
Thank you for watching my videos. Yes, please make sure that you have all trafic are allowed from internet. And then create Glue crawlers and Jobs, it works as expected.
Hi I am having problem with steps Iam role at minute 37:54. No found roles with services principal aws-glue. this UI I see after clicking the iam roles. I need really your help to solve my problem.
Thank you for watching my videos. In my video I have suggested to use one IAM role with administrative policy attached to it and trust to AWS Glue and Lambda services. Please have these configuration done IAM role use same while creating Glue crawlers job and Lambda.. It should work
Thank you for watching my videos. Yes.. Here in this lab, I have shown for one table at Redshift cluster which is destination and it would one time activity. But source file could keep on coming which needs to updated to Redshift cluster table.
Awesome video!! I have a query: - I wanted to push s3 data(csv) to redshift tables. Can I anyhow use table schema created by crawler to create table in redshift? In every tutorial instructor 1st hand creates a table in redshift, then uses crawler again to create schema in glue then pushes the data to reshift...then what is the use of creating schema using crawler?
Thank you for watching my videos. This is really good question, Glue crawlers works based on source (pre - configured details about source) and destination (pre - configured details about destination ) mapping and it expects both parts to be present before it starts pumping the data using job. Your requirement is more of custom and dynamic one, in this case you might need to rely with AWS Lambda where you can dynamically create table and upload data.
There must be a way to get the schema easily witouth having to us many resources bu I havne't found it yet, what about you? I know that Pandas has a function that helps with that maybe I can download the data and read a chunk and create the schema, but what if the data is FRIGIN BIG? Like teras of data, no way I'm goin to dowload that. As far as I'm concearned the crawler gives you a data schema from the csv which u can use it. RN I will try to upload a csv in S3, the redshift cluster is connected to that S3 which means I can copy the csv from s3 to a table in redshift but i wanna se if the csv appears already there in the DB of the redshift cluster.
Thank you for watching my videos. S3 endpoint here is enabling VPC S3 bucket endpoints, this is needed to securely connect to Redshift via VPC AWS backbone network. You need have VPC and S3 bucket access to do this.
Again Running Crawler and Watch dog and Lamda it creates duplicate rows right ? How will be the New data from source to target keep updated automatically kindly explain pls...Other than that Your Full Demo session is wonderful for beginners bro thanks
Thank you for watching my videos. The videos gives a way for Datawarehousing your raw data from Amazon S3 Bucket , upcourse analytics can be done using Spectrum feature which is different use case. Datawarehouse house different use cases like Reporting, analytics, ML etc
Hi Thank you for the informational videos, would you clarify this doubt I have, here gluecrawler created and ran only once I believe instead of creating glue crawler can it be possible to migrate data directly from s3source crawler to redshift table . My intention of asking this query is since we are running gluecrawler only once or only at a time when we would like to see records in redshift table since the functionally of accessing records in redshift is possible by quering in the query editor
Thank you for watching my videos. We migrating data from source s3 to Amazon redshift which is destination here. Crawlers can be scheduled or invoked on demand.
We have invoked the crawler by lamda but we were crawled it se table again what is the purpose same table again pushed? we got already table in redshift from source.
There two aspects are been shown there. 1. Created Glue job based ETL pipeline (manually triggered once) whcih creates table for the first time in redshift. 2. Next we, are triggering the same Glue pipeline using event rule (when there is a file uploaded in s3 bucket), this automation scenario. Hope this helps you to understand it.
Thank you for watching my videos. Hope you have followed all steps been mentioned in the video to invoke lambda.. In that case could you please check the permissions been assigned to role of Lambda.
@@cloudquicklabs Hi, thanks for replying really appreciated. I checked my lamda role permission applied was administrative access and trusted policy I have given for lambda, aws glue and s3 by adding each in json
Thanks for the tutorial. I would like you to give me your point on two doubts that I have - What is the best way to debug the code that does the ETL Glue process? - Is it possible to do all this infrastructure using IaaC ? Do you have any example?
Thank you for watching my videos. Please find my answers below. 1. To debug the AWS Glue configuration, we have to check logs and follow the standard methods. 2. Yes complete configuration fone above can maintained as Infrastructure as Code using Terraform, for examples please check my AWS Infrastructure as Code using Terraform videos.
Hi Thank you for this beautiful video. Unfortunately when we are running the glue job it is putting the duplicate data inside redshift. Like suppose we have new data in s3 and we run the crawler job after the job succeeded it is triggering the glue job and the new data is being updated is inside redshift and the data in redshift is getting doubled as it is duplicating the past data. Can you please help with this...??
Thank you for watching my videos and reaching on this. Here the solution is not intelligent enough to deduplicate the data or rather take the differential data upload in redshift, so I would suggest to clean up the file which uploaded in redshift and make only required data to be present in s3 bucket side when file is uploaded.
I believe we can't do it with glue job but by making s3 file containing unique data. And might be cleaning temp table created by crawlers from sources side.
Thanl you for watching my videos. I have attached policy 'Administrator Access' to the role. You need fine grain it (like give only download access on S3, CloudWatch log group creation, log put access, AWS Lambda, Event bridge, AWS glue access and Redshift accesses) when it is production to follow least privilege method..
Hello ! Wonderful video. You got a sub. Thanks for saving my time of hours of reasearch. However, I have two questions/requests. 1) When I use a crawler in the Console, the Glue Catalog is able to create a table automatically. But, when I use Pyspark to type the code, I am required to provide a table . Why is that ? 2) Can you show how to transfer data from S3 (csv file) to Redshift after some transformation using Glue, in the Visual editor of the Glue console ?
Thank you for watching my videos. 1. It could due pyspark does not the capability while it is meant for Transforming the data and provides high scalable power. 2. Indeed , I am going to create new video here on how to migrate data from S3 (csv file) to Redshift cluster soon.
Hello Sir, I hope you are doing well. I have a confusion while creating a new role. At Step 1 of creating role it gives an option to choose Use case . What should we choose there in order to keep both (Glue and Lambda) as trusted entities. Your guidance will be appriciated. Thanks
Thank you for watching my videos. I am doing good, hope you are also doing good as well. You could add 'S3' and 'AWS Lambda' in trusted entities of so that same role can be used on either side.
Thank you for watching my videos. You can find file share in videos description, you can find the repo github.com/RekhuGopal/PythonHacks/tree/main/AWSBoto3Hacks/AWS-ETL-S3-Glue-RedShift
Thank you for watching my videos. Apologies that it made you confused. Please watch again may be just pause and rewind it. Feel free ask doubts as well.
Thank you for watching my videos. Administrator access is blanket access but you could finegrain your IAM role with least previlage approach and use it for solution(I left this part as self service)
No other videos I watch have this many adverts. The overwhelming majority have one advert at the start and no others. Forcing viewers to watch adverts every few minutes disrupts the learning process.@@cloudquicklabs
Thank you for giving valuable inputs. I shall to take it to fine tune myself. This Lab scenario is unfortunately bit complex and content was meant to reach wider audience like starter, proficient and experts.









this demo is good but there are two things missing here. only the incremental data should be loaded in redshift when the job runs again. in your case there is duplication. another thing u could have shown is making changes on the fly in the excel sheet which invokes the crawler and automatically runs a job.
Thank you for watching my videos.
These are indeed valuable inputs.
I am planning to make next version of this video where these inputs are taken care.
Keep watching and Happy learning.
right
Hi brother if you have any update on how we can load only incremental data please share it with me....
Thank you for providing reminder.
I am on it , I shall upload it soon.
@@cloudquicklabsok
thanks. Its help me a lot regarding VPC part
Thank you for watching my videos.
Glad that it helped you.
Great presentation. You speak exactly like someone I met at Generation & I.
Thank you for watching my videos.
Thanks for the demo. Have you created the (Setting the ETL Infrastructure using Terraform) demo for the same?
Thank you for watching my videos.
I have set Infrastructure using manually here. But its good idea to keep this infrastructure with using Infrastructure as Code i.e Terraform. I shall keep in mind this in my next video
Thanks for the video! Very informative!
Thank you for watching my videos.
Glad that it helped you.
This is very useful video with deep level of understanding. Thank you so much for this kind of videos. Looking Forword to upcoming videos.
Thank you for watching my videos.
And thank you very much encouraging words. Keep watching and keep learning from my videos.
what if you have multiple tables? Do you need to create a redshift crawler for each tbl??
Thank you for watching my videos.
The current capability of aws glue crawlers needs to create multiple points of crawlers when you have multiple tables.
Clean explanation. Thank you keep uploaded more
Thank you for watching my videos.
Keep watching, lots of videos are coming ahead.
We can also load data to redshift using copy command from S3. So, what is the difference between the above method and using copy command.
Thank you for watching my videos.
This really a good question.
The method shown in this video is using complete aws given service (Glue crawlers) to extract, load and transform, whereas COPY commond is using SQL method by connecting to RDS and uploads the data.
This is Awesome. I subbed. Hope to see more videos on AWS.
Thank you very much for encouraging words and watching my videos.
Looking forward to contribute more value to the AWS community.
Appreciate yuor efforts! But you have not explained the significance of creating reshift crawler, why security group required with the same name... I would request you to go step by step for making this things better understand.. Patience!
Thank you for watching videos.
I appreciate your patience and valuable feedback are taken. Keep learning. :)
it was a good demo ...thank you so much. just a small question
. Why we didn't use S3 trigger destination to Lambda function if new file is added or update instead of EventBridge ?
Thank you for watching my videos.
This is custom solution that designed here. But Indeed we can use S3 object create event to trigger the workflow as well.
Hi,
@cloudquicklabs What was the use of second crawler. Is it only run once to get schema of redshift in to temp database and later it won't be running any time?
Thank you for watching my videos.
It's to load the data from s3 to aws glue data catalog and then to Amazon Redshift services.
Did you watch the second version of this video th-cam.com/video/RGSKeK9xow0/w-d-xo.htmlsi=FB_1BXVQp-SnfUtq
Awesome Session very helpful💐
Thank you for watching my videos.
Please do share it your friends as well.
I am getting "Account *** is denied access" while creating crawlers. I tried signing in afresh. It's not helping. Also, while modifying inbound rules for security groups i selected allow all for the types.
Thank you for watching my videos.
May be AWS might have disabled crawler or ETL job in your account , just raise service quota limit or raise support case should help you.
Hi
when exactly do I need to set up a route table and NAT Gateway for using glue? Can you elaborate on that? I can also use glue and crawlers without the route table as long as the roles are correct?
Thanks
Thank you for watching my videos.
Yes, please make sure that you have all trafic are allowed from internet.
And then create Glue crawlers and Jobs, it works as expected.
Hi I am having problem with steps Iam role at minute 37:54.
No found roles with services principal aws-glue. this UI I see after clicking the iam roles. I need really your help to solve my problem.
Thank you for watching my videos.
In my video I have suggested to use one IAM role with administrative policy attached to it and trust to AWS Glue and Lambda services.
Please have these configuration done IAM role use same while creating Glue crawlers job and Lambda.. It should work
Hey Quick question,
why is not there a trigger at target point? is it cause the Destination would be a one-time activity?? please revert?
Thank you for watching my videos.
Yes.. Here in this lab, I have shown for one table at Redshift cluster which is destination and it would one time activity. But source file could keep on coming which needs to updated to Redshift cluster table.
Awesome video!!
I have a query: -
I wanted to push s3 data(csv) to redshift tables.
Can I anyhow use table schema created by crawler to create table in redshift?
In every tutorial instructor 1st hand creates a table in redshift, then uses crawler again to create schema in glue then pushes the data to reshift...then what is the use of creating schema using crawler?
Thank you for watching my videos.
This is really good question, Glue crawlers works based on source (pre - configured details about source) and destination (pre - configured details about destination ) mapping and it expects both parts to be present before it starts pumping the data using job.
Your requirement is more of custom and dynamic one, in this case you might need to rely with AWS Lambda where you can dynamically create table and upload data.
There must be a way to get the schema easily witouth having to us many resources bu I havne't found it yet, what about you?
I know that Pandas has a function that helps with that maybe I can download the data and read a chunk and create the schema, but what if the data is FRIGIN BIG? Like teras of data, no way I'm goin to dowload that.
As far as I'm concearned the crawler gives you a data schema from the csv which u can use it.
RN I will try to upload a csv in S3, the redshift cluster is connected to that S3 which means I can copy the csv from s3 to a table in redshift but i wanna se if the csv appears already there in the DB of the redshift cluster.
At 9:11 how did you add both lambda and glue as trusted entities? Im only allowed to add one and then Im unsure of how to edit the json to add glue
Thank you for watching my videos.
This can be added when you are defining role , put trust values as 'glue.amazonaws.com'.
@@cloudquicklabs It doesnt allow you to put multiple trust values. I couldnt add both lambda and glue. I had to edit the json to add glue
Great video though!!
Exactly, this the way we need to add it.
Thank you for watching my videos, Happy learning.
Could you please explain the creation of s3 endpoint in detail and what policy is attached while creating s3 endpoint?
Thank you for watching my videos.
S3 endpoint here is enabling VPC S3 bucket endpoints, this is needed to securely connect to Redshift via VPC AWS backbone network. You need have VPC and S3 bucket access to do this.
Again Running Crawler and Watch dog and Lamda it creates duplicate rows right ?
How will be the New data from source to target keep updated automatically kindly explain pls...Other than that Your Full Demo session is wonderful for beginners bro thanks
Thank you for watching my videos.
I am currently looking to create v2 video this lab , I shall solve this problem in that video.
i explained this project in an interview interviewer aske me do you know redshift spectrum? cause we can directly query data in s3 from redshift.
Thank you for watching my videos.
The videos gives a way for Datawarehousing your raw data from Amazon S3 Bucket , upcourse analytics can be done using Spectrum feature which is different use case. Datawarehouse house different use cases like Reporting, analytics, ML etc
Hi Thank you for the informational videos, would you clarify this doubt I have, here gluecrawler created and ran only once I believe instead of creating glue crawler can it be possible to migrate data directly from s3source crawler to redshift table .
My intention of asking this query is since we are running gluecrawler only once or only at a time when we would like to see records in redshift table since the functionally of accessing records in redshift is possible by quering in the query editor
Thank you for watching my videos.
We migrating data from source s3 to Amazon redshift which is destination here. Crawlers can be scheduled or invoked on demand.
We have invoked the crawler by lamda but we were crawled it se table again what is the purpose same table again pushed? we got already table in redshift from source.
There two aspects are been shown there.
1. Created Glue job based ETL pipeline (manually triggered once) whcih creates table for the first time in redshift.
2. Next we, are triggering the same Glue pipeline using event rule (when there is a file uploaded in s3 bucket), this automation scenario.
Hope this helps you to understand it.
@Cloud Quick Labs How to configure cloudwatch and lambda function to trigger when job is succeeded I tried but my lambda is not getting invoked.
Thank you for watching my videos.
Hope you have followed all steps been mentioned in the video to invoke lambda..
In that case could you please check the permissions been assigned to role of Lambda.
@@cloudquicklabs Hi, thanks for replying really appreciated.
I checked my lamda role permission applied was administrative access and trusted policy I have given for lambda, aws glue and s3 by adding each in json
Thanks for coming back on this.
Hope this helped you
Can you do the same with Firehose? It supports Redshift from S3 automatically using the COPY command...
Thank you for watching my videos.
Indeed I shall create a new video on it, thank you for giving new ideas.
It was a great demo. Thank you.
You are welcome. Thank you for watching my videos.
Nice video n explanation.
Thank you for watching my videos.
Hii bro i have a doubt i have a datastage job converted into XML file i want to convert the XML file into glue job how can I do
Thank you for watching my videos.
Do you mean that you want to convert the xml file data to Redshift cluster DB.?
a wonderfull video! thanks man !
Thank you for watching my videos.
Glad that it helped you.
aws glue software any tail version?
Thank you for watching my videos.
Glue is PaaS there is versions here but feature options can be explored.
Thanks for the tutorial.
I would like you to give me your point on two doubts that I have
- What is the best way to debug the code that does the ETL Glue process?
- Is it possible to do all this infrastructure using IaaC ? Do you have any example?
Thank you for watching my videos.
Please find my answers below.
1. To debug the AWS Glue configuration, we have to check logs and follow the standard methods.
2. Yes complete configuration fone above can maintained as Infrastructure as Code using Terraform, for examples please check my AWS Infrastructure as Code using Terraform videos.
Hi Thank you for this beautiful video.
Unfortunately when we are running the glue job it is putting the duplicate data inside redshift. Like suppose we have new data in s3 and we run the crawler job after the job succeeded it is triggering the glue job and the new data is being updated is inside redshift and the data in redshift is getting doubled as it is duplicating the past data. Can you please help with this...??
Thank you for watching my videos and reaching on this.
Here the solution is not intelligent enough to deduplicate the data or rather take the differential data upload in redshift, so I would suggest to clean up the file which uploaded in redshift and make only required data to be present in s3 bucket side when file is uploaded.
@@cloudquicklabs Thank you again, Shall we do it with the glue job itself?
I believe we can't do it with glue job but by making s3 file containing unique data. And might be cleaning temp table created by crawlers from sources side.
@@cloudquicklabs Hi I got the solution I think all we need to enable bookmarks in gluejob from the console and it will not repeat the old data.
Great to hear back from you side.
Happy for you that you explored it.
And thank you very much for sharing it here.
what are all policies u have attached in ETLlambdaAccessRole ????
Thanl you for watching my videos.
I have attached policy 'Administrator Access' to the role. You need fine grain it (like give only download access on S3, CloudWatch log group creation, log put access, AWS Lambda, Event bridge, AWS glue access and Redshift accesses) when it is production to follow least privilege method..
@@cloudquicklabs thankyou 😊
You are welcome.
How to configure redshift, vpc ur explain high levele
Thank you for watching my videos.
Thank you for your encouraging words.
@@cloudquicklabs no comment pls answer my question.. Provide your data
Good content, but the flow of your explanation is quite confusing.
Thank you for watching my video.
Apologies that you find this video bit confusing.
Please watch it with patience , it should be helping you.
few more examples create it and place the videos. super
Indeed , I shall create more in this context of Data engineering.
i am making connection to redshift it fails
Thank you for watching my videos.
Please check if you are providing correct username and password and network connections are correct.
Hello !
Wonderful video. You got a sub. Thanks for saving my time of hours of reasearch.
However, I have two questions/requests.
1) When I use a crawler in the Console, the Glue Catalog is able to create a table automatically. But, when I use Pyspark to type the code, I am required to provide a table . Why is that ?
2) Can you show how to transfer data from S3 (csv file) to Redshift after some transformation using Glue, in the Visual editor of the Glue console ?
Thank you for watching my videos.
1. It could due pyspark does not the capability while it is meant for Transforming the data and provides high scalable power.
2. Indeed , I am going to create new video here on how to migrate data from S3 (csv file) to Redshift cluster soon.
@@cloudquicklabs Thanks forcthe info
Hello Sir,
I hope you are doing well.
I have a confusion while creating a new role.
At Step 1 of creating role it gives an option to choose Use case . What should we choose there in order to keep both (Glue and Lambda) as trusted entities.
Your guidance will be appriciated.
Thanks
Thank you for watching my videos.
I am doing good, hope you are also doing good as well.
You could add 'S3' and 'AWS Lambda' in trusted entities of so that same role can be used on either side.
Please try to add subtitles to your videos
Thank you for watching my videos.
Yes.. I am enabling it right away.
Thanks man
Thank you for watching my videos.
Glad that it helped you.
Can u share files and script used here
Thank you for watching my videos.
You can find file share in videos description, you can find the repo github.com/RekhuGopal/PythonHacks/tree/main/AWSBoto3Hacks/AWS-ETL-S3-Glue-RedShift
thanks for the tutorial, please load with sub in spanish :( !
Thank you for watching my videos.
Yes, I shall try to update it.
@@cloudquicklabs thanks, can i load .txt with aws glue? or only csv?
It supports csv (as it has column and rows). I dont think that it supports. txt.
Confusing at many place
Thank you for watching my videos.
Apologies that it made you confused. Please watch again may be just pause and rewind it. Feel free ask doubts as well.
Dude, Administrator access!! SERIOUSLY!
Thank you for watching my videos.
Administrator access is blanket access but you could finegrain your IAM role with least previlage approach and use it for solution(I left this part as self service)
@@cloudquicklabs Yes.
The people who are new to DevOps will just use this administrator role.
You could have provided an IAM policy for people to use.
Thank you for the valuable inputs.
I shall consider these points in my next video.
34 minutos para importar un csv en una tabla... mamita...
Thank you for watching my videos.
Yes took that much time as it has step-by-step explanation..
I tried to watch this video, but there were adverts every 2 or 3 minutes. For me this is unacceptable and unwatchable.
Thank you for watching my videos.
Apologies that you are not liking the often adverts coming while playing it. But note that this is how TH-cam works.
No other videos I watch have this many adverts. The overwhelming majority have one advert at the start and no others. Forcing viewers to watch adverts every few minutes disrupts the learning process.@@cloudquicklabs
Mr. Author, you could be more humble. Your tone should be modulated.
Thank you for watching my videos.
I shall consider this input. Thank you again for your inputs.
I understand the pain point here.
Apologies for inconvenience.
poor video quality.
Thanl you valuable input, I am in progress to improve quality soon. .
Till then please do rely on this and keep learning.
Most confused trainer I have ever seen. This guy just jumps here and there. Follow proper steps if you want to create proper content.
Thank you for giving valuable inputs.
I shall to take it to fine tune myself.
This Lab scenario is unfortunately bit complex and content was meant to reach wider audience like starter, proficient and experts.