
- 179
- 298 640
Statistics for Sustainable Development (Stats4SD)
เข้าร่วมเมื่อ 10 ก.ค. 2016
Statistics for Sustainable Development is a not-for-profit, social enterprise that provides:
\t• Statistical and data management expertise
\t• Support on research designs and methodology
\t• Technical guidance related to collection and processing of data and information.
As a team of technicians and statisticians, we believe that our best work is done when supporting organisations and communities across the world that share our vision of a more sustainable future for all.
The videos on our channel aim to support students, researchers, and academics, and are accompanied by the free resources on our website.
\t• Statistical and data management expertise
\t• Support on research designs and methodology
\t• Technical guidance related to collection and processing of data and information.
As a team of technicians and statisticians, we believe that our best work is done when supporting organisations and communities across the world that share our vision of a more sustainable future for all.
The videos on our channel aim to support students, researchers, and academics, and are accompanied by the free resources on our website.
Hypotheses, science and statistics: thoughts for students in agriculture and agroecology
A short introduction to research hypotheses, specifically in the context of agroecology and agricultural research. This video was created for the 'Research Methodology' course, given for MSc students in Agricultural Sciences at Sokoine University of Agriculture (SUA).
For our free resources, visit our website:
stats4sd.org/resources
Statistics for Sustainable Development is a not-for-profit, social enterprise that provides:
• Statistical and data management expertise
• Support on research designs and methodology
• Technical guidance related to collection and processing of data and information.
As a team of technicians and statisticians, we believe that our best work is done when supporting organisations and communities across the world that share our vision of a more sustainable future for all.
The videos on our channel aim to support students, researchers, and academics, and are accompanied by the free resources on our website.
Stay updated on what the team is up to over on our LinkedIn:
www.linkedin.com/company/statistics-for-sustainable-development/
For our free resources, visit our website:
stats4sd.org/resources
Statistics for Sustainable Development is a not-for-profit, social enterprise that provides:
• Statistical and data management expertise
• Support on research designs and methodology
• Technical guidance related to collection and processing of data and information.
As a team of technicians and statisticians, we believe that our best work is done when supporting organisations and communities across the world that share our vision of a more sustainable future for all.
The videos on our channel aim to support students, researchers, and academics, and are accompanied by the free resources on our website.
Stay updated on what the team is up to over on our LinkedIn:
www.linkedin.com/company/statistics-for-sustainable-development/
มุมมอง: 22
วีดีโอ


Models, science and statistics: thoughts for students in agriculture and agroecology
มุมมอง 1814 วันที่ผ่านมา
A short introduction to models in research, particularly statistical models, given by Ric Coe. This video was created for the 'Research Methodology' course, given for MSc students in Agricultural Sciences at Sokoine University of Agriculture (SUA). For our free resources, visit our website: stats4sd.org/resources Statistics for Sustainable Development is a not-for-profit, social enterprise that...

Measurements and Joint Analysis
มุมมอง 648 หลายเดือนก่อน
In this video, originally given as on online seminar, Ric Coe talks about measurement and collecting data with farmers, and discusses how they can be involved in the data analysis. More videos on this topic: th-cam.com/play/PLK5PktXR1tmMlefd36ZQKWCn00F_J5YjX.html For our free resources, visit our website: stats4sd.org/resources Statistics for Sustainable Development is a not-for-profit, social ...

Negotiating Research Designs
มุมมอง 828 หลายเดือนก่อน
In this video, Ric Coe follows on from his previous webinar, this time looking at the outcome of negotiating with farmers. This video covers questions of balancing alternatives, deciding who is right, and how to compromise between requirements of both researchers and farmers. More videos on this topic: th-cam.com/play/PLK5PktXR1tmMlefd36ZQKWCn00F_J5YjX.html For our free resources, visit our web...

Methods at the Design Stage
มุมมอง 568 หลายเดือนก่อน
In this video, originally given as on online seminar, Ric Coe talks about choosing designs when involving farmers in the research cycle. The session focuses on the process of co-creation, considering what makes a 'good' design, and whether those rules should be changed for these situations. More videos on this topic: th-cam.com/play/PLK5PktXR1tmMlefd36ZQKWCn00F_J5YjX.html For our free resources...
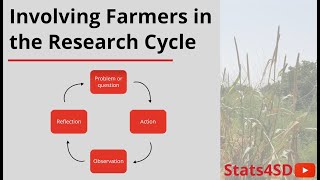
Involving Farmers in the Research Cycle
มุมมอง 469 หลายเดือนก่อน
In this video, originally given as on online seminar, Ric Coe talks about the methods used when involving farmers in the research cycle, and the potential considerations you need to take into account. More videos on this topic: th-cam.com/play/PLK5PktXR1tmMlefd36ZQKWCn00F_J5YjX.html For our free resources, visit our website: stats4sd.org/resources Statistics for Sustainable Development is a not...

Coding Procedures
มุมมอง 11911 หลายเดือนก่อน
This is the fourth video in our series on qualitative data management. This video defines what coding of qualitative data is and covers some different approaches to coding. Finally, we look at an example of a coding frame and structure for data analysis. Ver en español: th-cam.com/video/5CNNMeeRJ8E/w-d-xo.html Watch more videos in this series on qualitative data management here: th-cam.com/play...

Procedimientos de codificación
มุมมอง 19211 หลายเดือนก่อน
Este es el cuarto vídeo de nuestra serie sobre gestión de datos cualitativos. Este video define qué es la codificación de datos cualitativos y cubre algunos enfoques diferentes de codificación. Finalmente, analizamos un ejemplo de marco y estructura de codificación para el análisis de datos. Watch in English: th-cam.com/video/XbbLk37P_dc/w-d-xo.html Vea más vídeos de esta serie sobre gestión de...

Procedimientos de transcripción
มุมมอง 13911 หลายเดือนก่อน
Este video explica qué son las transcripciones y cómo realizarlas, analiza ejemplos de buenas transcripciones y considera cómo traducir transcripciones. Este vídeo es la tercera parte de esta serie sobre gestión de datos cualitativos. Watch in English: th-cam.com/video/Ya6Dz230BUk/w-d-xo.html Vea más vídeos de esta serie sobre gestión de datos cualitativos aquí: th-cam.com/play/PLK5PktXR1tmN-Mt...
Transcriptions Procedures
มุมมอง 3111 หลายเดือนก่อน
This video explains what transcriptions are and how to conduct them, looks at examples of good and transcriptions, and considers how to translate transcriptions. This video is the third part of this series on qualitative data management. Ver en español: th-cam.com/video/iKOkekbmURo/w-d-xo.html Watch more videos in this series on qualitative data management here: th-cam.com/play/PLK5PktXR1tmN1if...
Sistemas de seguimiento de datos cualitativos
มุมมอง 4311 หลายเดือนก่อน
Este es el segundo vídeo de esta serie sobre gestión de datos cualitativos. Cubre las características de las buenas prácticas de gestión de datos cualitativos, las características clave de los procesos de denominación de archivos cualitativos y explica los pasos de un sistema de seguimiento de datos cualitativos. Watch in English: th-cam.com/video/W4dyK2lCsdo/w-d-xo.html Vea más vídeos de esta ...
Qualitative Data Tracking Systems
มุมมอง 7311 หลายเดือนก่อน
This is the second video in this series on qualitative data management. It covers the characteristics of good qualitative data management practices, the key features of qualitative file naming processes, and explains the steps of a qualitative data tracking system. Mira este vídeo en español: th-cam.com/video/uJjkyHkH6Mg/w-d-xo.html Watch more videos in this series on qualitative data managemen...
Papel de los datos cualitativos
มุมมอง 2611 หลายเดือนก่อน
Este vídeo, el primero de una serie corta sobre gestión de datos cualitativos, explica el papel de los datos cualitativos y la investigación cualitativa. También compara el flujo de datos y las características de los datos cualitativos y cuantitativos. Watch in English here: th-cam.com/video/xaAqnMolLa0/w-d-xo.html Vea más vídeos de esta serie sobre gestión de datos cualitativos aquí: th-cam.co...
Role of Qualitative Data
มุมมอง 7011 หลายเดือนก่อน
This video, the first in a short series on qualitative data management, explains the role of qualitative data and qualitative research. It also compares the data flow and features of qualitative and quantitative data. Ver en español: th-cam.com/video/GO3llFH6LfI/w-d-xo.html Watch more videos in this series on qualitative data management here: th-cam.com/play/PLK5PktXR1tmN1ife2PcM3B17r6jFmE5NX.h...
Farmer Research Networks in Malawi: Socially Just Models of Inclusive Knowledge Co-Creation
มุมมอง 91ปีที่แล้ว
This video introduces the concepts and elements of agroecology, and discusses real examples from Farmer Research Networks in Malawai. This is a recording of a presentation which was originally given by Romina De Angelis at the UKFIET conference on Education for Social and Environmental Justice in September 2023. It also includes a presentation by Frank Tchuwa and Daimon Kambewa. For our free re...