
- 525
- 222 987
Toronto Machine Learning Series (TMLS)
เข้าร่วมเมื่อ 22 ธ.ค. 2017
From Chaos to Control Mastering ML Reproducibility at scale
Speaker:
Amit Kesarwani, Director, Solution Engineering, LakeFS
Abstract:
Machine learning workflows are not linear, where experimentation is an iterative & repetitive to and fro process between different components. What this often involves is experimentation with different data labeling techniques, data cleaning, preprocessing and feature selection methods during model training, just to arrive at an accurate model.
Quality ML at scale is only possible when we can reproduce a specific iteration of the ML experiment-and this is where data is key. This means capturing the version of training data, ML code and model artifacts at each iteration is mandatory. However, to efficiently version ML experiments without duplicating code, data and models, data versioning tools are critical. Open-source tools like lakeFS make it possible to version all components of ML experiments without the need to keep multiple copies, and as an added benefit, save you storage costs as well.
Amit Kesarwani, Director, Solution Engineering, LakeFS
Abstract:
Machine learning workflows are not linear, where experimentation is an iterative & repetitive to and fro process between different components. What this often involves is experimentation with different data labeling techniques, data cleaning, preprocessing and feature selection methods during model training, just to arrive at an accurate model.
Quality ML at scale is only possible when we can reproduce a specific iteration of the ML experiment-and this is where data is key. This means capturing the version of training data, ML code and model artifacts at each iteration is mandatory. However, to efficiently version ML experiments without duplicating code, data and models, data versioning tools are critical. Open-source tools like lakeFS make it possible to version all components of ML experiments without the need to keep multiple copies, and as an added benefit, save you storage costs as well.
มุมมอง: 53
วีดีโอ


AI for AI Scotiabank's Award Winning ML Models
มุมมอง 672 หลายเดือนก่อน
Speakers: Narcisse Torshizi, Data Scientist/ Data Science Manager, Scotiabank Andres Villegas, Data Scientist Manager, Scotiabank Abstract: A brief overview of four innovative models that power and improve a chatbot solution Last year, Scotiabank was awarded the 2023 Digital Transformation Award by IT World Canada for our customer support chatbot. This achievement was made possible through the ...

Modular Solutions for Knowledge Management at scale in RAG Systems
มุมมอง 562 หลายเดือนก่อน
Speakers: Adam Kerr, Senior Machine Learning Engineer, Bell Canada Lyndon Quadros, Senior Manager, Artificial Intelligence, Bell Canada Abstract: An important component of any RAG system or application is the underlying knowledge base that the bot or application uses. At Bell, we have built and adopted modular document embedding pipelines that allow some level of customization in the processing...
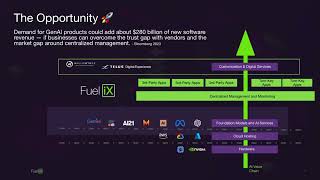
Fuel iX: An enterprise grade Gen AI platform
มุมมอง 3282 หลายเดือนก่อน
Speakers: Liz Lozinkshy, Engineering Manager, Gen AI Platform Team, TELUS Sara Ghaemi, Senior Software Developer, Gen AI Platform Team, TELUS Abstract: Sharing how TELUS enabled Gen AI for everyone internally through Fuel iX to get the most value out of the latest advancements in generative AI, while ensuring flexibility, control, privacy, trust and joy! TELUS has been making incredible strides...
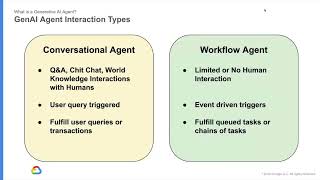
Agentic AI: Unlocking Emergent Behavior in LLMs for Adaptive Workflow Automation
มุมมอง 2322 หลายเดือนก่อน
Speaker: Patrick Marlow, Staff Engineer, Vertex Applied AI Incubator, Google Abstract: Explore the emergent capabilities of "agentic" AI, where agents combine LLMs, reasoning loops, and tools to tackle complex workflows beyond the capabilities of LLMs alone. This session examines techniques for fostering this intelligence, enabling agents to adapt and self-direct their actions for unparalleled ...

AI Agents with Function Calling:Tool Use
มุมมอง 932 หลายเดือนก่อน
Speaker: Aniket Maurya, Developer Advocate, Lightning AI Abstract: Learn about Agentic workflows with LLM tool use. Generate structured JSON output and execute external tools/functions.
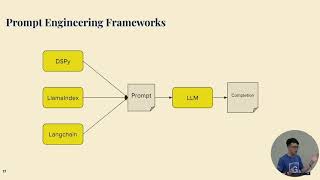
Optimizing Large Language Model Selection for Efficient GenAI Development
มุมมอง 452 หลายเดือนก่อน
Speakers: Royal Sequeira, Machine Learning Engineer, Georgian Aslesha Pokhrel, Machine Learning Engineer, Georgian Christopher Tee, Software Engineer, Georgian Abstract: When developing a Generative AI use case, developers face a variety of choices, particularly with the proliferation of foundational and open-source models. The decision process to choose the suitable large language model (LLM) ...
The Gap From Prototype to Production
มุมมอง 312 หลายเดือนก่อน
Speaker: Ian Yu, Machine Learning Engineer, Groupby Inc Abstract: 2023 was a good year for prototyping LLM-based applications, but 2024 is a great year for productionizing them. However, going into production, there are many unforeseen questions and challenges. These include decisions between managed solutions and custom implementations, balancing the rigour of experimentation with the speed of...

Generative AI Design Patterns
มุมมอง 1042 หลายเดือนก่อน
Speaker: Krishnachaitanya Gogineni, Principal ML Engineer, Observe.AI Abstract: In this presentation, we delve into the expansive world of generative AI design patterns, selecting five pivotal examples to explore in depth: Retrieval Augmented Generation (RAG), Cluster Pulse, State Based Agents, Guard Rails, and Auto-Prompting. These patterns represent a subset of the broader spectrum of generat...
Exploring the Frontier of Graph Neural Networks Key Concepts, Architectures, and Trends
มุมมอง 702 หลายเดือนก่อน
Speaker: Anik Pat, Lead Machine Learning Applied Scientist, Genesys Abstract: In today's data-driven world, the relationships and connections within data are as crucial as the data itself. Graph Neural Networks (GNNs) have emerged as a groundbreaking technology that leverages these relationships to uncover insights and drive innovation across various domains, from social network analysis to dru...
Getting Started With Generative Text And Fine Tuning LLMS In Hugging Face
มุมมอง 1672 หลายเดือนก่อน
Speaker: Myles Harrison, Consultant and Trainer, NLP from Scratch Abstract: If you're new to working with LLMs hands-on in code, this is the session for you! In this introductory workshop, you'll get working with Hugging Face and the transformers library for generating text from LLMs and applying performance efficient fine-tuning methods to a generative text model. Whether you are starting from...
How GenAI is Being Used for Productivity at Wealthsimple
มุมมอง 562 หลายเดือนก่อน
Speaker: Mandy Gu, Senior Software Development Manager, Wealthsimple Abstract: At Wealthsimple, we leverage GenAI internally to improve operational efficiency and streamline monotonous tasks. Our GenAI stack is a blend of tools we developed in house and third party solutions. Today, roughly half of the company utilizes these tools in their day to day work. These are the lessons we learned in ad...
Kùzu A fast, scalable graph database for analytical workloads
มุมมอง 782 หลายเดือนก่อน
Speaker: Prashanth Rao, AI Engineer, Kùzu, Inc. Abstract: In this session, we will introduce Kùzu, a highly scalable, extremely fast, easy-to-use, open source embedded graph database designed for analytical query workloads. Users who are familiar with DuckDB in the SQL world will find Kùzu to be a refreshingly familiar graph analogue. A number of state-of-the-art methods from graph database res...
Arcane, an Internal RAG System to Pinpoint Investment Policies
มุมมอง 162 หลายเดือนก่อน
Speaker: Ehsan Amjadian, Head of AI Solution Acceleration & Innovation, RBC Abstract: In this session we'll walk the audience through the building blocks of Arcane, a Retrieval-Augmented Generation system to point our specialists to the most relevant policies scattered across an internal web platform in a matter of seconds. It has the potential to boost productivity by orders of magnitude. We w...
Ask the Graph: How Knowledge Graphs Helps Generative AI Models Answer Questions
มุมมอง 1222 หลายเดือนก่อน
Speaker: Michael Havey, Senior Solutions Architect, Amazon Web Services Abstract: Generative AI has taken the world by storm. The Retrieval Augmented Generation (RAG) pattern has emerged as an effective way to incorporate your organization's data to provide current, accurate answers to questions that users ask a Large Language Model (LLM) Knowledge Graphs make RAG even more accurate and helpful...
Advances in Algorithmic Recourse: Ensuring Causal Consistency, Fairness, & Robustness
มุมมอง 1662 หลายเดือนก่อน
Advances in Algorithmic Recourse: Ensuring Causal Consistency, Fairness, & Robustness
FL4Health Private and Personal Clinical Modeling
มุมมอง 442 หลายเดือนก่อน
FL4Health Private and Personal Clinical Modeling
Making RAG Retrieval Augmented Generation Work
มุมมอง 622 หลายเดือนก่อน
Making RAG Retrieval Augmented Generation Work
Industrializing ML Workflows in Drug Discovery
มุมมอง 532 หลายเดือนก่อน
Industrializing ML Workflows in Drug Discovery
LLMs for Leaders & Senior Product Managers
มุมมอง 372 หลายเดือนก่อน
LLMs for Leaders & Senior Product Managers
AI ready Data Infrastructure for Real time Sensor Data Analytics on the Edge
มุมมอง 312 หลายเดือนก่อน
AI ready Data Infrastructure for Real time Sensor Data Analytics on the Edge
Building Reproducible ML Processes with an Open Source Stack
มุมมอง 132 หลายเดือนก่อน
Building Reproducible ML Processes with an Open Source Stack
A Practitioner’s Guide to Safeguarding Your LLM Applications
มุมมอง 822 หลายเดือนก่อน
A Practitioner’s Guide to Safeguarding Your LLM Applications
Optimizing Recommendations on Wattpad Home
มุมมอง 712 หลายเดือนก่อน
Optimizing Recommendations on Wattpad Home
Connecting the Dots Between AI Ethics and Sustainability
มุมมอง 172 หลายเดือนก่อน
Connecting the Dots Between AI Ethics and Sustainability
Building an Open Source Agentic RAG Application with Llama
มุมมอง 1812 หลายเดือนก่อน
Building an Open Source Agentic RAG Application with Llama
Deploying LLMs on Kubernetes environments
มุมมอง 292 หลายเดือนก่อน
Deploying LLMs on Kubernetes environments
Scaling Vector Database Usage Without Breaking the Bank Quantization and Adaptive Retrieval
มุมมอง 2832 หลายเดือนก่อน
Scaling Vector Database Usage Without Breaking the Bank Quantization and Adaptive Retrieval
Leveraging Large Language Models to build Enterprise AI
มุมมอง 592 หลายเดือนก่อน
Leveraging Large Language Models to build Enterprise AI
What a guy, you definitely eased my fear of agents.
thank you can we have this notebook
Are the slides available?
Are the slides available too?
one additional question - @ 1:09:00, you state shape of Q as ~600 x 20, reduced from ~9000 x 600. So 600 movies are represented by n=20 latent features. Correct me if I've misinterpreted. Given that, what does the output of a recommendation look like from Q? Are specific movies maybe clustered within those latent features? I'm a bit confused as to how the output of SVD would be plugged in a rec system. TIA!
Mitchell talks about how she thinks current tech doesn't make analogies and how she is working on something else. Questions are all asking about how aspects of current tech could somehow be analogies sort of. Except the last question. Maybe insects do analogies, too. And that is an interesting question. I can recommend Peter Godfrey Smith's Metazoa. It would be intriguing if an analogy making module was found relatively early in nervous system evolution.
please can you share slides
Simple Popularity based Recommendation, Collaborative Filtering using Matrix(2D) , Content Based Filtering. These 3 methods are mainly described in the video
In the last method of Matrix Factorization SVD was used. Can an Autoencoder be used ? Will it be computationally very expensive? Also will the quality of recommendation get any better or stay similar?
45:25 - Importance of matrix Sparsity
Advanced Agentic Literacy this video is gold one of the best videos on what works and doesn’t amazing I will teach it to my 45000 staff in our bank spot on.
awesome
You made me undesratnd the chronology of things are suppose to be in A Recommender System and m very grateful Thank You very much Jill.. Gonna go read your medium posts😉
So in summary it’s training a regression model for predicting demand and then use the model to get the demand curve and finally use an optimizer to maximize profit?
Thank you for putting this up for free
these 2 techniques are super old. Like Pre-2018 Era. Most systems like Tiktok, Instagram and etc use a two tower approach instead...
Did you find a good reference for that approach that you could share?
yeah but it depends on the company
Nice webinar, any online resource/example/tutorial on how to do this technically?
👍
At 1:17:00 If your values are continuous you can keep a threshold for eg: thres = 2 5 - 4 < thres is considered close whereas 5 - 2 > thres it's not close. Now, you have a binary matrix for precision and recall
matrix sparsity of MovieLens 20M Dataset using your code is 0.54% where my findings imply the matrix sparsity is 100-0.54=99.46% which makes more sense after all. I dont understand. isnt the formula sparsity=(#zero valued elements)/(#total elements) ?
02.07.2024: Semantic Kernel : 20k stars, 1.3M downloads, 268 contributors Langchain : 88k stars, 81M downloads, 477 contributors
@ternaus I love your hair looks good on you!🎉 Congratulations on this one
Had a meeting with them last week. As of now, bb ai will be released next year but don’t quiote me on this
Thanks great overview!
Completely usless model. Models learn from the past data . They cannot predict the future. Once political event can completely turn the model parameters upside down.
not a denmo what a garbage
The mic. It's so painful to follow. Please, next time you record a conference fix this :)
Hi, thank you for your presentation. Could you please give me the source and dataset for this model?
it seems great but in practice this only works for very small subset of false predictions, which is not worth it in a critical usecase or non critical usecase
thanx.
33:30 That would actually just be a better test to see if a human is a robot.
Can we get the notebooks?
thank you so much bro
17:00 Calculating the average rating
Which white paper is referred in this video? Can i get link?
Dear Jil, Your tutorial is extremely helpful and well presented - well done! However, I do have a small question about the section where You discuss sparsity. In most documentation I see that sparsity is measured by getting the quotient of number of zero or missing values / total number of elements in the matrix. However, You're taking the number of ratings (rather than missing values) into the formula - why? Considering that we have 610x9724=5,931,640 elements and 100,836 ratings - it would seem that our sparsity should be quite big (as most data is missing)! Also, could You point to any documentation which discussed at which levels of sparsity the CF methods should be used? Best regards, Pawel.
You're right, I found 5830804 empty elements out of 5931640 which means the sparsity is 98.30% not 1.7%
tks for sharing
Subpar model 😂. I legit made something better...by myself with $500. I guess everything is so new, it seemd few actually understand how to build a SOTA model. Guess this was a POC though.
Bard got trained on hundreds of trillions of tokens vs 700 billion tokens for Bloom model.
Thank you for sharing your experience which we don't hear from Google and OpenAI
Okay, I nominate this guy to be future Marty McFly in "Back to the future 4"
great talk! lovin' the technical details about training
Very educational, I am only as non-technical novice, especially with Gen AI and Foundation Models. I learned from 40 minutes.
Has it been 10 weeks already?
sorry, don't think that slide on 6:49 was explained well.
I think you should have started from a checkpoint & trained on your private dataset, just monitoring test performance on MMLU and your finance metrics.
This man is a genius
look into
FinGPT is better tho.
방송도 버출얼 캐릭터들이 많이해. 물론 사람이 하는건데, 이것도 AI화 될수있어. 그럼 그것도 인간이 할수 없을꺼야.