
- 131
- 106 990
Marton Balazs UoB
United Kingdom
เข้าร่วมเมื่อ 3 เม.ย. 2020
Marton's teaching-related videos
A short demo: Vim is useful
Learning Vim was one of the best investments of time I ever made. Give it a try.
มุมมอง: 465
วีดีโอ


FTiP21/47: Proof of continuity of measures
มุมมอง 3.8K3 ปีที่แล้ว
The forty-seventh 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/46. Global DeMoivre-Laplace theorem
มุมมอง 2833 ปีที่แล้ว
The forty-sixth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
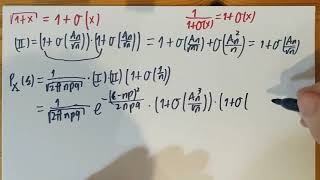
FTiP21/45. Proof of the DeMoivre-Laplace theorem, 3.
มุมมอง 1493 ปีที่แล้ว
The forty-fifth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/44. Proof of the DeMoivre-Laplace theorem, 2.
มุมมอง 1853 ปีที่แล้ว
The forty-fourth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/43. Proof of the DeMoivre-Laplace theorem, 1.
มุมมอง 3923 ปีที่แล้ว
The forty-third 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/42. DeMoivre-Laplace theorem
มุมมอง 1K3 ปีที่แล้ว
The forty-second :-) 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/41. Proof of Stirling's formula
มุมมอง 2593 ปีที่แล้ว
The forty-first 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.

FTiP21/40. Stirling's formula and some motivation
มุมมอง 1783 ปีที่แล้ว
The fortieth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/39. Bernstein polynomials and Weierstrass’ approximation theorem
มุมมอง 7013 ปีที่แล้ว
The thirty-ninth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/38. Weak Law of Large Numbers (with second moment)
มุมมอง 2043 ปีที่แล้ว
The thirty-eighth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/37. Law of Rare Events
มุมมอง 4853 ปีที่แล้ว
The thirty-seventh 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/36. Proof of the integer Continuity theorem 2.
มุมมอง 1183 ปีที่แล้ว
The thirty-sixth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/35. Proof of the integer Continuity theorem 1.
มุมมอง 1203 ปีที่แล้ว
The thirty-fifth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/34. Integer limit distributions and Continuity theorem
มุมมอง 1383 ปีที่แล้ว
The thirty-fourth 2021 video of the online series for Further Topics in Probability at the School of Mathematics, University of Bristol.
FTiP21/32. Recurrence of simple random walk
มุมมอง 4393 ปีที่แล้ว
FTiP21/32. Recurrence of simple random walk
FTiP21/31. Simple random walk, hitting times
มุมมอง 9373 ปีที่แล้ว
FTiP21/31. Simple random walk, hitting times
FTiP21/30. Total population in the G-W process
มุมมอง 1783 ปีที่แล้ว
FTiP21/30. Total population in the G-W process
FTiP21/27. Extinction probability in the G-W process
มุมมอง 4693 ปีที่แล้ว
FTiP21/27. Extinction probability in the G-W process
FTiP21/23. Generating functions and convolutions
มุมมอง 3513 ปีที่แล้ว
FTiP21/23. Generating functions and convolutions
FTiP21/22. Generating function of Negative Binomial
มุมมอง 1183 ปีที่แล้ว
FTiP21/22. Generating function of Negative Binomial
FTiP21/21. Generating function of Geometric
มุมมอง 913 ปีที่แล้ว
FTiP21/21. Generating function of Geometric
FTiP21/20. Generating function of Poisson
มุมมอง 733 ปีที่แล้ว
FTiP21/20. Generating function of Poisson
FTiP21/19. Generating function of Binomial
มุมมอง 1033 ปีที่แล้ว
FTiP21/19. Generating function of Binomial
thanks for the explanation
Great video! I'm currently listening to Markov's chain class and you explaind stopping time very clearly. Thank you!
not all heros wear capes
Thank you great content!
Brilliant
Nice!
1:39
I gotta say your proofs are beautiful and make so much sense. Thank you very much! May God bless you!
I really like this proof. Thank you very much.
Provide proof of it
Sorry, not unless I'll have to teach this proof during a lockdown. :-) Videos like this take a lot of work. You could see a proof in section III/11 of Shiryaev: Probability, Second Edition (Springer 1996).
Very good sir🎉🎉🎉🎉 well explained I learned from u I am from Nepal
in the example at time stamp (15:13) you constructed intervals of the form (0, 1/n] but these intervals do not satisfy a_n > b_(n-1) condition you state above. it would be kind of you to clarify if i misunderstood what you are trying to state.
The orange example at 12:51 is just an example to show that script A on the top of the page is not a sigma-algebra. If your question was about why it is relevant to script A: just one interval of the form (. , .] is in A (take n=1 in the union). Let's change the index of the example from n to k (I should have done that in the video to avoid confusion), and consider a sequence of intervals (0, 1-1/k] as k=2...infinity. For each k, this is in script A (with n=1 in the definition of script A each time). Hence, the union of these things for all k's should also be in script A, if script A would be a sigma-algebra. But it is not, since the union is not in script A: it is not of the form (. , .], nor a finite combination of these. For the next bit starting at 14:44 you could forget about this example in orange: it continues the discussion of the script A algebra on the top of the page. I hope this helps.
You are an agent of god sent on earth to explain conditional expectation to students who never had good teachers. This example cleared so many things, as you said in previous video "Think of the conditional expectation as an averaging over sets (or, equivalently, events) that are too fine for g to see inside."
you are awesome man. thank you uploading these videos.
If you are looking for a non-technical explanation of the 0-1 Law, you can find it here: th-cam.com/video/lopKqJwqk6M/w-d-xo.html
@Marton 13.47, definiton of expectation. Would it be accurate to summarize that if the Ai's are disjoint, then you can convert Ai's into Ai' s such that Ai' are disjoint and then use Ai' in the definition of the expectation?
I guess 2:15, and if they are *not* disjoint? Yes, then one can convert the A_i's and the x_i's to fall back to the disjoint situation.
@@martonbalazsuob4363 thanks
Marton, sorry for troubling you again. Question: Difference between measurable and measure. Measure operates on elements of an algebra (domain). Measurable in the definition of the random variable operates on elements of omega - which are not elements of an algebra. Is this correct?
Sorry I'm not sure I understand. The definition of a measurable function also involves elements of the sigma-algebra.
@@martonbalazsuob4363 @11.15, X is defined as a map from Omega to R. (as opposed to from F, the sigma algebra, to R). So that made me think X was not a set function. Is that incorrect? In other words, if the statement was X maps elements of F to R, I would not have the confusion.
I was under the impression Omega is the set, and F is the Algebra (sigma algebra generated from Omega).
@@RajivSambasivan Omega is a set, and X maps its elements to R. But it also has that special property that pre-images of Borel sets in R are sets in the sigma-algebra F. That is, for each Borel set B in R, we have {omega in Omega: X(omega) in B} in F.
@@martonbalazsuob4363 Thanks Marton, the fact that gets me here is having to read about the definition of the random variable from image to pre-image rather than pre-image to image. Like many, the subconcious association of a function to me is a transformation. A device that takes elements of the domain and creates elements of the range. Here the action is reverse. With X as a function, I have to go from B which is an image under X to it's preimage in Omega. Now, after I saw this and pondered about it, it becomes clear why we reason this way with Random Variables - it is because we only observe the image, not the pre-image. What really happened as a result of the random experiment, the fact we get to observe, is the image.
Marton, first off thanks so much for putting this online. Much appreciated. Question: Random variable X maps omega's to values in R. These values, produced by X as a map do not have to be less than 1. However, because it is in R, we can construct a Borel set for any value produced by X, find its inverse image (produced by X) and then apply the probability measure to it. So every time we have a probablity question about a value of X, it is really a probability question applied to the inverse image produced by X. Would this be an accurate summary?
Thanks. Yes, I think this summarises it well.
@@martonbalazsuob4363 Thanks
Just watching the conditional expectation - so this discussion is what makes X, F measurable - is that right?
@@RajivSambasivan Yes, I think so.
I have a question Ingeneral Can I say that the union of A sub n is the supremum of all An ? And the intersection of A sub n is the infimum of An ?
It sounds logical to me but I haven't actually come across supremum or infimum of events before.
you are the best teacher in this field. really thank you for your helping
Is there any relation between Lp convergence and a.s convergence at all?
One way to go from a.s. to L^p is via uniform integrability: th-cam.com/video/RbRps6kUniI/w-d-xo.html th-cam.com/video/1YR3zT3hl2s/w-d-xo.html . Conversely, to prove a.s. convergence, Borel-Cantelli or ergodic theorems usually come handy. Martingales also converge a.s. and/or in L^p under some circumstances. But no, there is no general recipe as such between L^p and a.s. convergences.
... and of course monotone or dominated convergence can also do the trick of a.s. to L^p if they apply.
@@martonbalazsuob4363 Thank you !
U are a legend
Thank you so much. I was skeptical at first on how to integrate e^(quadratic) but now I know to substitute the integrals with constants
Are the variables xn+1 ... xn+m supposed to be independent variables, or can they be dependent also?
Independence is essential for this proof, I haven't looked up if there are different versions of the theorem where this is weakened.
Our handwritten script looks almost the same 😁
I feel really sorry for you then. 😄
Heloo can I ask you what this theorem helps us do?
Good question as some of the practice problems we covered in class are not part of these publicly available lecture series. But Optional Stopping is among the few most used theorems in Martingales. One can use it to find expectations of stopping times or probabilities of reaching one state before another in certain scenarios. For two common applications search for 'ABRACADABRA' with martingales, or the gambler's ruin problem.
@@martonbalazsuob4363 Thank you very much I've searched the ABRACADABRA application. Can I ask you if stopping times have anything common with Optimal Stopping Theory? I have a hard time aproaching this problem in a mathematical way.
@@ozgekaraoglan3359 I'm not sure I understand your question: this video is about the Optional Stopping Theorem in which stopping times play a fundamental role.
@@martonbalazsuob4363 Well while I was researching it I came across antoher theory called the optimal stopping theory and wondered if they were similar but I understand better now
In the definition of expectation, you used simple functions which had some measurable sets associated with them, the A_k's. Then you took a limit to find the expectation of nonsimple RVs. Won't the definition of expectation be dependent on these A_k's? How do you get around the fact that expectation definition might depend on the measurable sets in the definition of simple RVs?
This is a very good point and something I haven't detailed much: it is a theorem that the resulting definition of expectation is independent of choice of the approximating sequence of simple random variables.
At 12:30, E Z_n = E Z_{n-1} * m is the application of Wald's identity derived in FiTP25 (E(Z) = E(Y) * mu).
At 7:39, the form of mass function can be rewritten in a form of "negative Binomial coefficient" using the identity introduced in (just before) th-cam.com/video/NP9R7SxW7t4/w-d-xo.html (FTiP21/22. Generating function of Negative Binomial) The mass function of negative Binomial is Prob(X=k) = (k-1, r-1) q^{k-r} p^r, where (k-1, r-1) denotes the binomial coefficient of (k-1) choose (r-1). Define k = r + m, then the coefficient becomes (r+m-1, r-1) which equals to (-1)^m (-r, m). That means, if we define a pessimistic(?) negative Binomial random variable Y := X - r, so that Y measures the number of failures required to achieve r successes. Then, Y's mass probability function is Prob_Y(Y=m) = (-1)^m (-r, m) q^m p^r which is in a form of negative binomial coefficient and hence the name.
At 8:10, "X is proper, when Par(X<infty) = 1", where Par() denotes the partition function. I suppose this is the definition of a proper random variable. Then, if X is proper, the power series form of Par(s) is exactly the expectation E(s^X). It is then claimed that even if X is improper, as long as we consider 0<s<1, the summation form is equivalent to the expectation form of generating function. Could you please address a bit more on that? I feel like it has something to do with the contribution of X when X=infinity, but from the answer to my last question, that summation sum_{i=0}^infty actually does not contain X = infinity. So it looks like that that summation form is never equal to the expectation form as X = infinity is never considered in summation, regardless the value of s?
The key is that when 0<s<1, s^infty = 0. So, either in the probabilistic or the analytic language, E(s^X) = E(s^X ; X<infty) + E(s^X ; X=infty) = E(s^X ; X<infty) which is taken care of by the sum, or sum_{i=0}^infty s^i * p(i) = sum_{i=0}^infty s^i * p(i) + s^infty * P{X=infty} in other words the X=infty case has no contribution for the generating function. (The notation ";" means multiply with the indicator of the event that follows.)
@@martonbalazsuob4363 Thank you so much for the clear explanation!
Thank you, the 2nd example really made something click for me.
At 8:00, why do we have Proba(Union_{i=0}^infty(X=i)) = Proba(X < infty)? I am confused as the left-hand-side is a union containing i = infty, but on the right-hand-side we only look at X<infty which explicitly excludes the infinity? At 8:35, 1 - sum_{i} p(i) = Proba(X=infty) is written down. Although the lower and upper limits of the summation is not explicitly written down, I guess they are 0 and infinity respectively. Then I am confused again why we have i = infinity on left-hand-side but we have Proba(X=infinity) on right-hand-side? I feel it is the same question and I lack background of something to understand this..
The union is over all integers, but it does not include infinity itself. As the union means "at least one of", it will account for all integer values of the random variable, in other words for the event that X is finite. Similarly, when we say sum from 0 to infinity that means all the integers but it does not include infinity itself.
@@martonbalazsuob4363 Thanks for the explanation. That sounds making sense as there would be some integers not included if we stopped the sum at some finite value. So the sum must keep going from 0 to infinity. But this just means we consider all possible integer values of X. On the other hand, the infinity itself seems to be a tricky concept!
At 7:40, it is this proposition in the previous video used th-cam.com/video/UjNSGY_FKpI/w-d-xo.html
Yes, that's the one.
At 2:30, there should be no prime (denoting differentiation) on -exp(-y)?
Yes, correct - yet another typo from me, sorry for that.
At 1:00, from wiki it says that Huygens principle says that every point on a wavefront is itself the source of spherical wavelets. So I think Cau(b_x, a_x) * Cau(b_y, a_y) may be viewed as two consecutive projections and so the locations b_x, b_y and heights a_x, a_y add up intuitively. However, I am a bit confused as Cauchy distribution does not assume wave property of lights at all. How can it obey Huygens principle? By the way, looking forward to see complex function theory series on the channel.
This comment was only at the level of intensities, no intereference is accounted for. Complex function thy series: only if I need to teach that during a pandemic some day. :-)
At 6:51, it seems to say that the existence of odd moments is more tricky, why is so? What I can imagine about odd moments is that if the probability mass function is symmetric, then all odd moments vanish as the whole summand is an anti-symmetric function. But when it comes to the existence of limits I can hardly imagine the effect of odd n.
Expectations can be infinite and that's fine, but they can also not exists. That happens when there is both a positive and negative infinite component in the sum or integral and we don't know how to make the difference. For odd n, this could be the case. For even n, everything is non-negative so the expectation is either finite or infinite but always exists.
Proof part1) Start with a hedging strategy with portfolio including a stock (of that European option) and bond, we show that the initial value must be the value given by the theorem if we choose the probability p = (r-a)/(b-a). Proof part2) Start with the initial value specified by the theorem, we show that if p is chosen as (r-a)/(b-a), and Y_n is chosen as E(...|F_n) as in the lecture, we can find a hedging strategy. Q1. a little question: in proof part1), we define Y_n := (1+r)^{-n}X_n as the present value of the wealth on day n, because we start with an explicit hedging strategy (so can define Y_n in terms of X_n). But in the proof part2) th-cam.com/video/yQWUAqA4tzI/w-d-xo.html , when we write X_n = (1+r)^n Y_n, this is actually a definition of X_n, right? because the definition of Y_n comes first in part2), and then we define X_n = (1+r)^n Y_n so that we can apply calculation in part1) (and also lemma) to find H_n and hence A_n. But for this to make sense X_0 and X_N must match the values we want and that's the final step to check. Q2: is the probability space completely artificial? The result of the initial value x = (r+1)^{-N} E(S_N - K)^+ looks completely independent of a,b. However, p = (r-a)/(b-a) depends on a,b. Naively, it is not obvious if S_N depends on a,b. If b is close to r, I thought mean of S_N would be small compared with the case b>>r, as b is close to r means that stock is just a bit better than a bond when w_n=1. But I noticed later that in this case p approaches 1 as well so the stock is basically always in the "profitable state" (w_n=1). So is it true that once we decided a striking price (K) and number of days later (N), the value of the option is completely determined no matter what the underlying stock is? Thank you.
Q1: yes, you are right. Q2: The parameters a and b are hidden in that expectation, so x does depend on them. The value of the strategy will depend on K, N, r, and also a and b.
The definition of hedging requires that the wealth X_n is never negative during 0 <= n <= N. Though it may become clear after seeing the proof of the theorem in later videos, I am curious why do we need the condition X_n >= 0 for hedging? Naively, as long as the end result, i.e. the wealth on day N, X_N, equals to the value of the mixed stock+bond, we replicated the European option? Or is it required for the uniqueness property of the theorem?
I'm not sure why we need to have it, maybe someone more familiar with finance can shed light on the intuition behind this. From the proof it actually follows that the unique strategy (even without assuming positivity) does X_n >= 0 for all n's.
Thank you so much for sharing such nice lecture series. It is my first time seeing a proof of the strong law of large number. It is enjoyable to watch the lectures paving the way to prove something which may be used often but never proven by many people. It all starts from reading somewhere that conditional expectation is a random variable not a number (which shocked me). Then I found and watched one of the MT course videos introducing conditional expectation and then I couldn't help but started from lecture 1 up to here (and will try to finish all). Really appreciated and hope the videos in this channel grows in the future.
Thanks. The law of large numbers has more classical proofs than with martingales. The weak law, with finite second moments: th-cam.com/video/Y987RzsE0iA/w-d-xo.html . The weak law with characteristic functions: th-cam.com/video/6b5cEB0mWkM/w-d-xo.html . The strong law: th-cam.com/video/wTycSmNU7xk/w-d-xo.html all the way up to FTiP/22.
A very basic question again.., I was trying to articulate what we learned in terms of the example of sequence of fair coin flips but confused. Consider fair coin flip, the probability space is (Omega, F, P), where Omega = {H, T} (i.e. head or tail), and sigma-algebra F = {0, {H}, {T}, Omega}. The random variable X maps H to 1 and T to -1. P(H) = P(T) = 1/2 for a fair coin. 1. When considering filtration, we need a process X_n, where each X_n is a fair coin random variable and hence they all map from the same Omega to {-1,1}. Then, F_0 = F_1 = ... = {0, {H}, {T}, Omega}. Q:The sigma algebras F_n do not get finer and finer because the independent fair coin flips do not accumulate the info? 2. Or, shall we define the probability space in a way that varies with n, Omega_n = {HH...H, HH...T, ..., TT..T }, where each element has exactly n factors of H or T, so the sample space is actually changing with the sequence index n? In this case, F_1 = {0, {H}, {T}, Omega} but F_2 = {0, {H}, {T}, {HH}, {HT}, {TH}, {TT},..., Omega}, where F_n looks finer and finer. However, the random variables X_n then has to be defined on Omega_n. The idea of 2. looks weird to me as we have been defining filtration with respect to a single fixed underlying probability space. But if 1. is true, then it looks like J_n = sigma(X_{n+1},...) = {0, {H}, {T}, Omega} = J, as every X_n contributes same terms to sigma algebra. This result is obviously wrong as P({H}) = 1/2 not equals to 0 or 1. How can I resolve this? Thank you.
After watching MT/32. Discrete Black-Scholes formula: background, it looks like 2. is more correct than 1.. Consider a finite sequence of consecutive N coin flips, the sample space Omega looks like should be a Cartesian product(?) of "elementary sample space Omega_e := {H, T}". Specifically, Omega = Omega_e * Omega_e * ... * Omega_e, where there are N factors of Omega_e and * here denotes Cartesian product. Then, the full sigma-algebra of Omega will then be the power set of Omega. Omega has 2^N elements (of the form HH...H, HH...T,...etc.). The full sigma-algebra script-F has then 2^(2^N) many elements which are subsets of Omega. We should also have a probability measure mapping each element of script-F to a real number in [0,1]. A random variable X_n in the n-th position of the process should be a map from Omega to some space. I am imagining that X_n should map the n-th factor of Omega_e to {+1, -1} and maps other factors of Omega_e "trivially". However, I am not sure if I am on the right track and if so, what will be the map X_n looks like?
@@texla-kh9qx That's right, X_n just takes the n^th coordinate of an element w in Omega. X_n(w) = 1, if w_n="H", and -1 if w_n="T".
For the identity at around 9:40, E(M_r ; F) = EE(M_r ; F | F_{r-1}) <= by Tower rule, = E(M_{r-1} ; F) <= by Martingale property. Notice that F is an element of F_n and so F is an element of F_{n+1}, ..., F_r too. This makes the condition on F and F_{r-1} "interchangeably". Iterate this process until we hit E(M_r ; F) = ... = E(M_n ; F). We cannot continue the iteration because F is not an element of F_{n-k} for k = 1,2,..,n. Just want to make sure that it is the property F in F_n which makes the iteration terminate at n, correct? thanks!
EE(M_r ; F | F_{r-1}) = EE(M_r | F_{r-1} ; F) = E(M_{r-1} ; F) Just found that this trick is used in a later lecture: th-cam.com/video/KyGsKBz9qVo/w-d-xo.html
@@texla-kh9qx Just add a bit more parentheses: E(E(M_r | F_{r-1}) ; F).
Another conceptual question.., C_n is said to be predictable if C_n if F_{n-1} measurable. The idea of this definition is that when making decision/strategy, we have only info up to (n-1) and no idea what happens at time n (and perhaps beyond). However, as we have filtration here, F_n is sigma-algebra in the increasing fashion in n. So if C_n is F_n measurable, it means C_n is F_{n+k} measurable as well for k=1,2,3,... I then have a question: In the definition of predictable/previsible random variable, is it OK that C_n take info up to a few steps before (n-1) but not really up to (n-1)? thanks!
Sure, that's ok. A broker can make decisions based on week-old data. It's fine though not very efficient. 🙂
Questions: 1. How to understand the superficially contradiction that F_n includes all info all to time step n (i.e. history) and event {T>n} (which looks like something happens in the future) should be also in F_n as a definition (i.e. complement must exist) of sigma algebra? Although {F_n} forms a filtration such that F_n gets finer and finer in n, so F_n indeed contains more info than F_m if n > m, as F_n is often constructed as the sigma algebra generated by random variables of X_k from 1 up to n. 2. Does T live in the same probability space as the random variables of the process, X_k, do? We start from a probability space (Omega, F, (F_n), P) with filtration (F_n). So all sigma algebras F_n are associated with the same sample space Omega. As for the random variable T, it takes values from 0,1,..,infty but what is the domain of T? It seems not to be Omega? I feel that if I understand 2. I may be able to resolve 1. but still struck.. thank you!
1. The information content of {T>n} is the same as that of {T <= n} (since exactly one of the two occurs). But the latter can be decided on by observing things up to time n. So it's not really in the future. 2. Yes, T is also a random variable on (Omega, F, P), it's defined on Omega. It just has that special measurability requirement in terms of the filtration.
For eg2 at 12:50, an attempt to prove it raises two little questions.. 1. (adapted) let F_n = sigma(X_1, X_2,...,X_n), then X_1,...,X_n are F_n measurable and hence so is Prod_{k=1}^m X_k =: M_m, for m=1,...,n. This shows F is a filtration and M_n is adapted to F. 2. Since E(X_k)=1 is finite, E|X_k| is finite too. Then, E|M_n| = E|X_1X_2...X_n| <= Prod_{k=1}^n E|X_k| which is finite, where we used Holder's inequality with p=q=1. 3. E(M_n | F_{n-1}) = E(X_n M_{n-1} | F_{n-1}) = E(X_n|F_{n-1}) E(M_{n-1}F_{n-1}), where we used the independence assumption in the 2nd equality. From the independence assumption, E(X_n|F_m) = E(X_n) for n>m. So the 1st factor can be simplified as E(X_n|F_{n-1}) = E(X_n) = 1. From the adapted property 1., M_{n-1} is F_{n-1} measurable and hence 2nd factor = E(M_{n-1}F_{n-1}) = M_{n-1}. So we have martingale property. In the above, there are some gaps I couldn't close it yet: a) a product of random variables which is F-measurable is again F-measurable. Not sure if it is true? b) E(XY) = E(X)E(Y) given X,Y are two independent random variables. This is naively true using the independence property of probability, P(X,Y) = P(X)P(Y) and then thinking expectation as integral. But I am not sure how to prove it formally in terms of what we have in this series of course?
For (b), from the lecture th-cam.com/video/MUwbNdCd03w/w-d-xo.html of MT/14, it seems E(X_n M_{n-1} | F_{n-1}) = E(X_n|F_{n-1}) M_{n-1} directly without the need of independence assumption. M_{n-1} can be factored down because M_{n-1} is F_{n-1} measurable.
E|X_1X_2...X_n| = Prod_{k=1}^n E|X_k|, no need for the inequality. a) Yes, a product of F-measurable random variables is also F-measurable. One needs to check that events of the form {the n-fold product <= x} are F-measurable. Such events are not so simple but can be expanded to the individual factors being in some Borel sets of R^n, hence things work out by the fact that the X_k's are measurable functions. You already answered b). To tackle E(XY) directly, you could use the Tower rule with sigma(Y), then measurability and the definition of independence tells you (assuming expectations exist) E(XY|sigma(Y))=Y*E(X|sigma(Y))=Y*E(X), so applying E on this does the job.
@@martonbalazsuob4363 Thank you! Indeed, the left hand side of equation becomes E(XY) after taking expectation by Tower rule of the version g = {0, Omega}, i.e. EE(A|B) = E(A) [Just noticed that you actually used this trick in the first remark of MT/15 th-cam.com/video/uTfj65-QO6w/w-d-xo.html ], and the right hand side becomes E(X)*E(Y) by linearity of expectation. Hence the identity can be elegantly shown in a formal way.
For eg1 at 11:35, I have a question in an attempt to prove it. 1. (adapted) let F_n = sigma(X1,X2,...,Xn), it is obviously a filtration. Then by construction M_k is Fn-measurable for k=1,2,..,n. Therefore, M_n is adapted to filtration. 2. (finite mean of absolute value for all n) E|M_n| <= E sum_{k=1}^n |X_k| = sum_{k=1}^n E|X_k|, where triangle inequality is used. The eg1 assumes zero mean of X_k but says nothing of E|X_k|, I have difficulty proving that E|X_k| < infty given E(X_k) = 0? 3. (Martingale condition) By the independence assumption and our choice of filtration, we have E(X_n | F_m) = 0 for n>m. Then, rewrite E(M_n | F_{n-1}) = E(M_{n-1} | F_{n-1}) + E(X_n | F_{n-1}), where linearity of expectation is used. For the 1st term on RHS, by adapted property, it equals to M_{n-1}. For the 2nd term on RHS, by independence property it equals to E(X_n) and then equals to zero by zero mean assumption. So we arrive at E(M_n | F_{n-1}) = M_{n-1}. How to complete step 2 (E|M_n| < infty for all n) ? Thank you!
When the expectation is a nonzero constant instead of zero in eg1, it looks like M_n is no longer Martingale? I tried to use the corollary that if M_n is a martingale, (M_n - M_0) is also a martingale, but found no way to proceed..
By definition if E(X_k) is finite then E|X_k| is also finite. That's because E(X_k) is the difference of E(X^+_k) and E(X^-_k) (positive and negative parts), while E|X_k| is the sum.
@@texla-kh9qx Correct, if the X_k is not mean-zero then M is not a martingale. You'll get a sub- or supermartingale. To make it into a martingale again one can center the X's hence use X_k-E(X_k) in the sum.
@@martonbalazsuob4363 I was thinking is it possible to have X_k being a linear function, like X_k(w) = w. In this case mean of X_k looks zero but absolute value looks divergent?
@@martonbalazsuob4363 Thanks! indeed recenter the X's recovers the martingale.
A basic question regarding definition of script F_infty at 2:09. It seems we only defined sigma algebra generated by a random variable before but never defined a sigma algebra generated by unions of sigma algebras? In general, unions of sigma algebras do not need to be a sigma algebra. Then, how is sigma(unions of F_n) defined? Even if we can generate a sigma algebra from the unions, is it guaranteed to be unique?
Apply th-cam.com/video/0i8l-TjMr4Y/w-d-xo.html to the union. I.e., any collection of subsets will have a unique smallest sigma algebra that contains this collection, that's what we use. (If you have many, intersect them (still a sigma algebra) to get the smallest one.)
At 8:23 when it talks about convergence almost surely, it is said that P(X_n -> X) = 1 is true for some set of Omega. Naively, I expected that all these convergence statements should be true for ALL elements of the sample space Omega? as random variables are functions on sample space? thank you!
Hmm for the definition of convergence weakly or in L^p, expectations are involved and so each element of sample space(s) (for the case of converging weakly there is no subtraction between random variables and hence sample spaces can be different) sort of contributes to the convergence. So I naively expected that for convergence in probability and almost surely, the formulas should be true for every element in the sample space Omega? After a brief search, is what i missed related to convergence pointwise or uniformly of functions? the definitions introduced in the lecture sound more like converge pointwisely?
@@texla-kh9qx I'm not sure about your questions. A.s. convergence means that for almost all omegas X_n(omega) --> X(omega). With in-probability, L^p and a.s convergence we do need to look at random variables on the same probability space. This is not the case for weak convergence so there they can be defined in different spaces. A.s. convergence is indeed pointwise on a full measure set of points (omegas, that is). The other modes of convergence here are new compared to the standard analysis notions. Later on there will be a statement saying that adding a sup into the definition of in-probability convergence boosts it up to a.s. convergence. th-cam.com/video/dS61PkLHEzg/w-d-xo.html This resembles a little bit to uniform convergence of functions but still different from that.
@@martonbalazsuob4363 Thank you! proceeding to the rest of the videos. I guess it was my bad mistaken 8:32 "same set of Omega" as "some set of Omega" :-p
In the monotone convergence theorem, how do we understand the effect of Y? say in part (a), Y looks like a kind of "lower bound", but since X_n is already converging to X in increasing fashion, the existence of Y looks redundant naively? although in the proof we will need Y so that we can apply the theorem of simple random variables to construct that set of sequences of simple random variables.
Good point, X_1 can indeed play the role of Y, but in this case we need to assume that EX_1 exists and is not -infty (which follows from the current form of the Thm anyway).
Questions: 1. What if for all n, it is always a fixed event A_K occurring? as it is true for all n, K could be only infinity. Is this scenario not making sense? but if it is possible then it's not infinitely many of A_k occur? 2. Do we need to impose an order on A_k here? from MT/2 Continuity of measure, the concept of limit on events exists only for increasing or decreasing A_k's. I am trying to understand the connection of limsup of events to limsup of functions. Here, the union piece looks like finding a sup (if increasing) from MT2 and then the intersection piece looks like taking a limit (if decreasing).
1. I think you are over-complicating this. We have events A_1, A_2, A_3, ... each of which may or may not occur. What is the question? 2. Indeed there is the natural order in the indices: A_1, A_2, A_3, ... There is no order required on the sets themselves; they do not need to be increasing or decreasing. You are right that the union (on events) has a flavour of sup (on functions): the union occurs iff at least one of the events occur. Now, this union from n...infty will be decreasing as a function of n (the more n, the less sets in the union, so it can only decrease), this might be the ordering you are missing. Hence the intersection in front is actually a set-limit even if the A's themselves are not ordered.
Could you elaborate a little bit on why E(X|g) is g-measurable? E(X|g) is a random variable and is hence a function from sample space to real line. A random variable is by definition measurable but I have difficulty understanding why this random variable E(X|g) is measurable with respect to g? Thank you.
Oh the (a) property of Kolmogorov theorem states that the random variable is g-measurable where g is the sub-sigma-algebra being conditioned on. So E(X|g) is g-measurable is indeed trivial by definition.
@@texla-kh9qx That's right, it's part of the defintion. Think of the conditional expectation as an averaging over sets (or, equivalently, events) that are too fine for g to see inside.