
- 101
- 421 783
Berkeley AI
เข้าร่วมเมื่อ 21 ม.ค. 2015
Spring 2016 Section 12 (Neural Networks) Solutions
Spring 2016 Section 12 (Neural Networks) Solutions
มุมมอง: 3 135
วีดีโอ


Spring 2016 Section 11 (Neural Networks) Overview
มุมมอง 2.6K8 ปีที่แล้ว
Spring 2016 Section 11 (Neural Networks) Overview

Spring 2016 Section 11 (Perceptrons + Neural Networks) Solutions
มุมมอง 2.5K8 ปีที่แล้ว
Spring 2016 Section 11 (Perceptrons Neural Networks) Solutions


Spring 2016 Section 10 (Naive Bayes + Perceptrons) Solutions
มุมมอง 3.6K8 ปีที่แล้ว
Spring 2016 Section 10 (Naive Bayes Perceptrons) Solutions

Spring 2016 Section 10 (Naive Bayes + Perceptrons) Overview
มุมมอง 2.8K8 ปีที่แล้ว
Spring 2016 Section 10 (Naive Bayes Perceptrons) Overview

Spring 2016 Section 9 (HMMs + Particle Filters) Solutions
มุมมอง 4.2K8 ปีที่แล้ว
Spring 2016 Section 9 (HMMs Particle Filters) Solutions
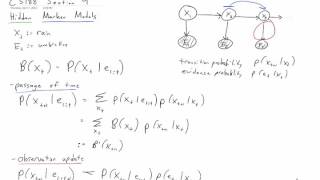
Spring 2016 Section 9 (HMMs + Particle Filters) Overview
มุมมอง 6K8 ปีที่แล้ว
Spring 2016 Section 9 (HMMs Particle Filters) Overview

Spring 2016 Section 8 (Sampling + VPI) Solutions
มุมมอง 2K8 ปีที่แล้ว
Spring 2016 Section 8 (Sampling VPI) Solutions
Spring 2016 Section 8 (Sampling + VPI) Overview
มุมมอง 2.3K8 ปีที่แล้ว
Spring 2016 Section 8 (Sampling VPI) Overview
Spring 2016 Section 7 (Bayes Nets + Variable Elimination) Solutions
มุมมอง 7K8 ปีที่แล้ว
Spring 2016 Section 7 (Bayes Nets Variable Elimination) Solutions
Spring 2016 Section 7 (Bayes Nets + Variable Elimination) Overview
มุมมอง 12K8 ปีที่แล้ว
Spring 2016 Section 7 (Bayes Nets Variable Elimination) Overview
Spring 2016 Section 6 (RL + Probability) Solutions
มุมมอง 3K8 ปีที่แล้ว
Spring 2016 Section 6 (RL Probability) Solutions
Spring 2016 Section 6 (RL + Probability) Overview
มุมมอง 3K8 ปีที่แล้ว
Spring 2016 Section 6 (RL Probability) Overview
Spring 2016 Section 5 (MDPs + RL) Solutions
มุมมอง 6K8 ปีที่แล้ว
Spring 2016 Section 5 (MDPs RL) Solutions
Spring 2016 Section 5 (MDPs + RL) Overview
มุมมอง 3.2K8 ปีที่แล้ว
Spring 2016 Section 5 (MDPs RL) Overview
Spring 2016 Section 4 (Games + MDPs) Solutions
มุมมอง 3.4K8 ปีที่แล้ว
Spring 2016 Section 4 (Games MDPs) Solutions
Spring 2016 Section 4 (Games + MDPs) Overview
มุมมอง 2.5K8 ปีที่แล้ว
Spring 2016 Section 4 (Games MDPs) Overview
Spring 2016 Section 3 (CSPs + Games) Overview
มุมมอง 2.2K8 ปีที่แล้ว
Spring 2016 Section 3 (CSPs Games) Overview
Spring 2016 Section 3 (CSPs + Games) Solutions
มุมมอง 2.3K8 ปีที่แล้ว
Spring 2016 Section 3 (CSPs Games) Solutions
Spring 2016 Section 2 (Graph Search + CSPs) Solutions
มุมมอง 2.2K8 ปีที่แล้ว
Spring 2016 Section 2 (Graph Search CSPs) Solutions
Spring 2016 Section 2 (Graph search + CSPs) Overview
มุมมอง 2.3K8 ปีที่แล้ว
Spring 2016 Section 2 (Graph search CSPs) Overview
Spring 2016 Section 1 (Search) Solutions
มุมมอง 2.3K8 ปีที่แล้ว
Spring 2016 Section 1 (Search) Solutions
This was great because i needed to understand this for my exam tomorrow.
volume is too much low
thank you so much.
Thank you, could be please share the homework link here if it's possible?
Thank you
Fantastic video explanation! Crisp, clear and formula-based. Easy to follow once you know the concepts and this video helps us clear the confusion among these fancy terms like joint, conditional and independence.
The audio is not clear. Very bad audio.
26:43 Isn't it Smoke is conditionally independent of Alarm given Fire?
Traditional Fire Alarm detects smoke not fire , so if there are other reason of smoke like someone smoking, it can increase the chance of alarm though it is not related to fire broken out.
20:43 His explanation is quite confusing.
The audio is not so clear.
Haha
Good explanation of likelihood weighting, very helpful
The content here flows extremely well. Thank you for making it public.
start at 9:22 if you know probability, if you don't this is a terrible introduction and I'd suggest watching the 3b1b videos on bayes rule. a good textbook is intro to probability by blitzstein hwang
It is just an application of bunch of expressions without a context and a delivery of logic. In my opinion, it does not teach the one anything, but just gives things to memorize.
Is there no need to normalize?
He forgot!
Best Explanation
Perfect!
👍
Thanks for your very clear explanation. For more examples on d-separation see this th-cam.com/video/yDs_q6jKHb0/w-d-xo.html
sound volume is too small.
Is this really MLE? Or is it MAP? 'XD
Perfect!
Really appreciate it.
Shouldn't the score of Alpha A1 at @11:00 be decreased and alpha B1 be increased since B is the right class?
Hi, at 4:17 didn't you do a switcheroo of the formula? Like instead of P(x,y) = P(x)P(y|x), it should've been P(x,y) = P(y)P(x,y) ? From what I hear in the video, this is the way you explained.
P(y|x)P(x) = P(x|y)P(y) because both are equal to P(x,y). See below: P(x|y) = P(x,y)/P(y) P(x,y)P(y) = P(x,y) P(y|x) = P(x,y)/P(x) P(y|x)P(x) = P(x,y) P(y|x)P(x) = P(x|y)P(y)
@@tubesteaknyouri And he did that so you get Bayes' Rule out of it. It wasn't just for the heck of it
The content here was extremely helpful, but the audio was really poor. Still, I wouldn't have figured this out without this particular video, so thank you!
*for first question 2(-1) + -2(2) = -6 not -2
By far the most efficient source of information about this topic I could find anywhere on the internet
After 5 years, its still the only one on whole internet
This was great!
Hey sorry but I don't get why we sample whereas we already have the true distribution... I don't see how it can be useful... Does anyone have an explaination please :)
Great explanation!!! Thank you!
Dude I love you all for posting these lectures but this is a 75 mins one on how to multiply two numbers together. Soooo painful :) <3
Really got a lot out of this thank you!
How do you calculate the update weight? Could you provide an example to calculate it?
Unfortunately the explanation of calculating entropy and information gain is very unintuitive.
concerning ex. 2f: isn't the largest factor generated 2^4? because the join on all factors containing T generates a table over 4 variables (say f2') of which one is summed out to get f2. so f2' has size 2^4
this is a good thought, but the given observation value of +z is a constant, not a variable, so although it is contained in f2(U, V, W, +z) the only variables of f2 are U, V, W, hence 2^3 = 8 .
Thanks for video. I am just wondering how we normalize to sum to 1 in part g. Can you give any numerical example? Thanks
+Zs Sj assume f5 gives you a vector with 2 entries for +y and -y, say [1/5, 3/5]. to normalize this vector simply divide each coordinate by the sum of all coordinates [1/5 * 5/4 , 3/5 * 5/4] = [1/4, 3/4]
Thanks
hansen1101 do you know why we should normalize this and how this became non-normalized one?
+Zs Sj in this particular case you are calculating a distribution of the form P(Q|e) where e is an instantiation of some evidence variables. By definition this form has to sum to 1 over all instances of the query variable Q (i.e. P(q1|e) + P(q2|e) = 1 in the binary case). Be careful, there are queries of other forms that need not sum to 1 and therefore normalization is not necessary (i.e P(Q,e) or P(e|Q)). This became non normalized after applying Baye's rule and only working with the term in the numerator, leavin out the joint prob. over the instantiated evidence vars in the denominator. Therefore you'll have to rescale in the end.
Can anybody please explain results on the slide at 1:05:11 for the given probability tables?
+sahdeV ok I got it... Observation we have is +u and not -u. So there are 4 ways in which +u is possible. Rain, Rain, Umbrella or TT-U Sun Rain Umbrella or FT-U Sun Sun Umbrella or FF-U Rain Sun Umbrella or TF-U Probability of each is respectively: 0.5*0.7*0.9 0.5*0.3*0.9 0.5*0.7*0.2 0.5*0.3*0.2 T-U probability is therefore 63+27/(63+27+14+6)=0.818 F-U probability is 14+6/(63+27+14+6)-0.182 *************** For the next stage, time based update alone gives us probabilities as B'(T)=0.818*0.7+0.182*0.3=0.6272 B'(F)=0.818*0.3+0.182*0.7=0.3728 observation (u+) based updates give us B(T)=0.6272*0.9/(0.6272*0.9+0.3728*0.2)=0.883 B(F)=0.3728*0.2/(0.6272*0.9+0.3728*0.2)=0.117
@@vedhasp Thank you very much.
Audio not goooooooood
1:17:14 It is bad example for LCV !!! This case never happens because MRV heuristic will color SA with blue (one color left !!!)
This is very helpful! Thank you