
- 11
- 187 299
Kasper Welbers
เข้าร่วมเมื่อ 1 เม.ย. 2020
This has been hastily created to upload some video lectures in times of Corona. In time I might actually add a useful description.
Webscraping in R
!! This video was recorded a while ago, and some of the examples no longer work. For the first example (on wikipedia), please check the updated code in this RMarkdown document:
github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/rvest.md
And yeah I know, the video is pretty long! It's actually 2 parts (in hindsight). Up till 40:00 it's mainly introducing how this works, and after 40:00 it's walking through 2 demo's. If you're the type of person that first wants to see something in action, you can skip straight to 40:00, and then see whether you want to spend time on learning understand what's happening there (for which you can either use the video or RMarkdown document).
github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/rvest.md
And yeah I know, the video is pretty long! It's actually 2 parts (in hindsight). Up till 40:00 it's mainly introducing how this works, and after 40:00 it's walking through 2 demo's. If you're the type of person that first wants to see something in action, you can skip straight to 40:00, and then see whether you want to spend time on learning understand what's happening there (for which you can either use the video or RMarkdown document).
มุมมอง: 16 991
วีดีโอ


LDA Topic modeling in R
มุมมอง 21K4 ปีที่แล้ว
RMarkdown tutorial: github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/r_text_lda.md Video series about topic modeling: th-cam.com/video/ELct2RRENQM/w-d-xo.html More tutorial stuff: github.com/ccs-amsterdam/r-course-material Good article on preprocessing for unsupervised ml: pdfs.semanticscholar.org/95e0/c468a19afc6173053234c7fe660033363ffb.pdf

Multilevel models in R
มุมมอง 18K4 ปีที่แล้ว
This video is the second part of a tutorial video on GLM and Multilevel in R. It gives a general handwaving introduction, with the main goal of showing the R code. For a proper introduction into Multilevel modeling as a technique, we recommend this free manuscript Chapter from a great book on the topic: multilevel-analysis.sites.uu.nl/wp-content/uploads/sites/27/2018/02/02Ch2-Basic3449.pdf

GLM in R
มุมมอง 58K4 ปีที่แล้ว
In this video we walk through a tutorial for Generalized Linear Models in R. The main goal is to show how to use this type of model, focusing on logistic regression, and talk a bit about why it's a good tool to know. The tutorial discusses both GLM and multilevel models, but the video has been split into two parts. github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/advanced_modeli...

Basic statistics in R
มุมมอง 2.3K4 ปีที่แล้ว
An introduction to basic statistics in R, based on the following tutorial: github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/simple_modeling.md

Understanding the glm family argument (in R)
มุมมอง 21K4 ปีที่แล้ว
The goal of this video is to help you better understand the 'error distribution' and 'link function' in Generalized Linear Models. For a deeper understanding of GLM's, I'd recommend the book "Generalized Linear Models" by McCullagh and Nelder. This is a book well worth buying, but I also (somehow) found an online version: www.utstat.toronto.edu/~brunner/oldclass/2201s11/readings/glmbook.pdf

Text analysis in R. Demo 2: Sentiment dictionaries
มุมมอง 4.9K4 ปีที่แล้ว
This demo is part of a short series of videos on text analysis in R, developed mainly for R introduction workshops. A more detailed tutorial for the code discussed here can be found on our R course material Github page: github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/sentiment_analysis.md Vignette for how to use corpustools: cran.r-project.org/web/packages/corpustools/vignettes...
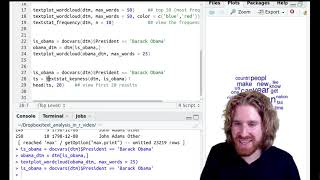
Text analysis in R. Demo 1: Corpus statistics
มุมมอง 21K4 ปีที่แล้ว
This demo is part of a short series of videos on text analysis in R, developed mainly for R introduction workshops. A more detailed tutorial for the code discussed here can be found on our R course material Github page: github.com/ccs-amsterdam/r-course-material/blob/master/tutorials/R_text_3_quanteda.md

Text analysis in R. Part 2: Analysis approaches
มุมมอง 6K4 ปีที่แล้ว
This is a short series of videos on the basics of computational text analysis in R. It is loosely inspired by our Text analysis in R paper (vanatteveldt.com/p/welbers-text-r.pdf), closely related to our R course material Github page (github.com/ccs-amsterdam/r-course-material), and 42% love letter to quanteda.
Text analysis in R. Part 1b: Advanced preprocessing
มุมมอง 4.6K4 ปีที่แล้ว
This is a short series of videos on the basics of computational text analysis in R. It is loosely inspired by our Text analysis in R paper (vanatteveldt.com/p/welbers-text-r.pdf), closely related to our R course material Github page (github.com/ccs-amsterdam/r-course-material), and 42% love letter to quanteda. This specific video just adds some stuff about more advanced tools for preprocessing....
Text analysis in R. Part 1: Preprocessing
มุมมอง 14K4 ปีที่แล้ว
This is a short series of videos on the basics of computational text analysis in R. It is loosely inspired by our Text analysis in R paper (vanatteveldt.com/p/welbers-text-r.pdf), closely related to our R course material Github page (github.com/ccs-amsterdam/r-course-material), and 42% love letter to quanteda. Useful links # Low-level string processing: A good place to start is by learning how ...
Doyle Plaza
Tabmodel doesnt work😮
Surely we can make it work. What error do you get?
@@gotnolove923 ah haha, that was me on another account that I was trying to delete.
Weissnat Shores
Hilll Streets
Connelly Mountain
Tanner Rest
Garcia Paul Wilson William Young Karen
Thomas Paul Wilson Eric Hernandez Melissa
Kailey Islands
Very well put together. I think there should be some recognition of the fact some of the symbols are mixed up in the presentation. The systematic component should always be mu and mu goes into the link function to give eta and eta is the value that goes into the random component distribution. Otherwise the slides don't make sense. To take a random example, the probit regression slide, mu is not defined anywhere. But changing systematic component to mu and then changing binomial parameter to eta then fixes everything.
Hi Murphyalex. Thanks for your comment! The notation used here is based on the book in the description. I was also initially confused about using eta as the systematic component, and then defining mu from inside the link function rather than the output of the link function, but thats how the link function is defined, and when you read their runthrough of the generalization it makes sense (just looked it up again; page 42, highly recommended). Note that mu is still defined, but as the inverse of the link function over eta. So for example, for poisson the mean function for the poisson distribution is defined as mu = exp(eta), which is identical to eta = log(mu). Or am I missing something else that you're referring to?
You should make more and more videos. You explained this on point! Like on R and everything on it you will surely be the best no doubt!
Hello it was good to learn LDA from this video, but can you arrange any videos for Structural topic modelling full explanation ?
Hi @guaravsutar9080, I'm afraid I haven't planned anything of the sort. It's been a while since I used topic modeling (simply because my research took me elsewhere), so I'm not fully up to speed on the current state of the field.
@@kasperwelbers oh yes thank you so much Actually I’m going through it but some of the codes I’m not able to interpret in R
How do I add my own csv file as the corpus?
Many thanks for great work! What software/tools do you use to record these videos if you don't mind me asking.
Thanks! I mostly used OBS, which is an open source tool for recording and streaming. I found it quite intuitive (with some tutorials), and as someone without any editing experience was able to set up a good simple system for switching and layering windows. (Though to be honest, this was amid early pandemic despair over how to manage online teaching, so I probably did spend quite some time on it). For the weather-person effect of talking in front of a screen, I bought a pull-up greenscreen, though since then I think automatic background filtering has come a long way, so a greenscreen might no longer be needed. I also used Kdenlive for editing. In my case I only used this for cutting and pasting pieces of recordings, which didn't really take long to figure out, but I think that tool also supports more advanced editing.
@@kasperwelbers thank you so much!
Kasper, how would this work for a correlation topic model heat map with topic rows/topic columns?
If I recall correctly, the correlated topic model mostly differs in that it takes the correlations between topics into account in fitting the model. It probably adds a covariance matrix, but there should still be posterior distributions for document-topic and word-document, and so you should still just be able to visualize the correlations of topics and documents (or topics with topics) in a heatmap. Though depending on what package you use to compute them, extracting the posteriors might work differently.
@@kasperwelbers Thank you! I tried this code, it seems to have worked for basic LDA: beta_x <- tidy(x, matrix = "beta") beta_wider = function(x){ pivot_wider(x, values_from = beta, names_from = topic) %>% arrange(term) %>% select(-term) %>% rename_all(~paste0("topic", .)) } beta _w <- beta_wider(x) cor1 <- cor(beta_w) I then plotted a correlation matrix.
This is a brilliant tutorial on GLM in R with a very good breakdown of all the information in step by step fashion that is understandable for a beginner
thank you french accent man
The dfm function is defunct unfortunately :(
Kasper, I found it very helpful, it was a great video and you set the bar high. Very very informative filled with concepts.
This is a great tutorial. I have a quick question. Which file type do I have to convert my current data set in an Excel file?
Thanks for sharing! The best tutorials I've watched. No fancy slides, but very very useful code line by line.
Dank u!
Best Explanation, the visuals bring the whole idea into life. Thanks
Really good tutorial, thanks a lot!! :)
Hi, why is R studio producing different results even though I am using the same call and data.
Hi! Do you mean vastly different results, or very small differences? I do think some of the multilevel stuff could in potential differ due to random processes in converging the model, but if so it should be really minor.
very clear layout and superb explanation for the intuition. Thanks!
Amazingly well-explained, thanks! Please, make more videos. Nonlinear models, Bayesian... some extra content would be nice!
THANK. YOU.
What a legend! You have no idea how much your videos have helped me. Thanks for making it clear and easy to understand:)
Great video, nicely explained
Thanks!
nice audio bro. you record in bathroom?
Ahaha, not sure whether that's a question or a burn 😅. This is just a Blue Yeti mic in the home office I set up during the COVID lock downs. The room itself has pretty nice acoustic treatment, but I was still figuring out in a rush how to make recordings for lectures/workshops and it was hard to get clear audio without keystrokes hitting through.
In order to be able to plot with textplot_wordcloud, you need first to load the "quanteda.textplots" library. I guess so few things have changed after 3 years. Otherwise it is not going to work. Thank's for the video dear Kasper.
can not use - dfmat_inaug <- dfm(toks_inaug, remove = stopwords("en") -is outdeated - what can I do insted?
Hi @roxyioana, please check the link to the tutorial in the description. We keep that repository up-to-date with changes. (and at some point I hopefully find the time to re-record some videos)
god bless you
Hello Kasper, I appreciate your great video. I have a question. Regarding your example data, what if there are two or more data points for each day for each person? Let's assume that you measure reaction time 4 times each day across participants. Do you need to average those data points and make one data point for each day? or do you use all data points?
Interesting question. We can actually add more groups to the model instead of aggregating, but it depends on your question. In the example, we used days as a continuous variable, because we wanted to test if there was a linear effect on reaction time. If you also want to consider the time of the day as a continous variable, then it indeed becomes awkward how to combine them. However, maybe your reason for the four measurements is just to get more data points, so you think of them as factors rather than continuous. While aggregating might be viable, you could also consider adding another level to your model, for whether the measurement was in the (1) morning, (2) afternoon, (3) evening, or (4) night. You could then have random intercept, for instance to take into account that people might on average have lower reaction times in the evening due to their after-dinner-dip. (though note that with just 4 groups you might rather want to use fixed effects with dummy variables) Perhaps more generally, what you're interested in is multilevel models with more than one group level. This is possible and very common/powerfull. Groups can then either be nested or crossed. be nested, for instance people living in cities.
what about importing text from multiple pdf/docx?
I think the easiest way would be to use the readtext package. This allows you to read an entire folder ("my_doc_files/") or use wildcards ("my_doc_files/article*_.txt). cran.r-project.org/web/packages/readtext/vignettes/readtext_vignette.html#microsoft-word-files-.doc-.docx
Thank you for the tutorial. Is it possible to create a glm model with a variable to explain which has 3 modalities
If I understand you correctly, I think it's indeed possible to model a dependent variable with a tri-modal distribution with glm. Actually, you might not even need glm for that. Whether a distribution is multimodal is a separate matter of the distribution family. A tri-modal distribution might be a mixture of three normal distributions, three binomial distributions, etc. Take the following simulation as an example. Here we create a y variable that is affected by a continuous variable x, and a factor with three groups. Since there is a strong effect of the group on y, this results in y being tri-modal. ## simulate 3-modal data n = 1000 x = rnorm(n) group = sample(1:3, n, replace=T) group_means = c(5,10,15) y = group_means[group] + x*0.4 + rnorm(n) hist(y, breaks=50) m1 = lm(y ~ x) m2 = lm(y ~ as.factor(group) + x) summary(m1) ## bad estimate of x (should be around 0.4) plot(m1, 2) ## error is non-normal summary(m2) ## good estimate after controlling for group plot(m2, 2) ## error is normal after including group
Dear Kasper, thank you very much for your videos. I am just getting into text analytics and I have a quick question. I am planning to work on Turkish language, and I don't know how to handle the stopwords and stemming processes. There are compatible files for TR to work through quanteda, but I don't know how to actually make them work. Could you please give some hints about that also? )
Good question. I'm not an expert on Turkish, so I don't know how well these bag-of-word style approaches work for it, but there does seem to be some support for it in quanteda. Regarding stopwords, quanteda uses the stopwords package under the hood. That package has the functions stopwords_getlanguages to see which languages are supported. Importantly, you also need to set a 'source' that stopwords uses. The default (snowball) doesn't support Turkish (which I assume is TR), but it seems nltk does: library(stopwords) stopwords_getsources() stopwords_getlanguages(source = 'nltk') stopwords('tr', source = 'nltk') Similarly, for stemming it uses SnowballC. Same kind of process: library(SnowballC) getStemLanguages() char_wordstem("aslında", language='turkish') # (same should work for dfm_wordstem) So, not sure how well this works, but it does seem to be supported!
@@kasperwelbers This is so helpful, thank you!!
Hey Kasper. Bedankt voor je gratis youtube premium in een airbnb in Berlijn afgelopen week 😅. Ik heb voor je uitgelogd toen ik naar huis ging. 👍🏻
Hahahaha 🤣. Nice, thanks!!
Hi, I'm trying to do this on reddit data but the files I have are too large (100gb+) for only 3 months of data. That's in .zst. Do you have any suggestions on how to deal with this and apply these techniques on this data set in R?
If your file is too large to keep in memory, the only option is to work through it in batches or streaming. So the first thing to look into would be whether there is a package in R for importing ZST files that allows you to stream it in or select specific rows/items (so that you can get it in batches). But perhaps the bigger issue here would be that with this much data you really need to focus on fast preprocessing, so that you'll be able to finish your work in the current decade. So first make a plan what type of analysis you want to do, and then figure out which techniques you definitely need for this. Also, consider whether it's possible to run the analysis in multiple steps. Maybe you could first just process the data to filter it on some keywords, or to store it in a searchable database. Then you could do the more heavy NLP lifting only for the documents that require it.
great thanks
This is amazing. Thank you
hello i' can't find the moment where you speak bout word documents. I'm having my words documents to crete a corpus
Hi @67lobe, I don't think I discuss word files in this tutorial. But I think the best ways are to use the 'readtext' package, or 'antiword'. The readtext package is probably the best to learn, because it provides a unified interface for various file types, like word, pdf and csv.
Very well explained, thank you!
What if you have combinations of two different groups. For example, you measure blood pressure from volunteers after drinking a certain number of units of alcohol. You do that in two different locations. So you want to fit a line per individual, but you also want to control for the location effect. Right?
You can certainly have multiple groups. First, you could have groups nested in groups. If you perform the same experiment in many countries across the world, your units would be observations nested in people (group 1) nested in countries (group 2). Second, you could have cross-nested (or cross-classified) groups. For example, say we want to study if the effect of more alcoholic beverages on blood pressure differs depending on the type of alcoholic beverage (beer, wine, etc.). In that case, each person could have observations for multiple beverages, and each beverage could have observations for multiple people.
@@kasperwelbers I see, thanks. I can imagine that having all these nested and cross-nested groups can complicate quite a lot the model and its interpretation.
Thank you for informative text analysis videos. I am just begginner on texxt analysis and R, I start with your videos. I have got a question at 12 :13 min, kwic() needs tokens() so, I applied toks <- tokens(corp) k = kwic(toks, 'freedom', window = 5) . Is it true?
Yes, you're correct. The quanteda api has seen some changes since this video was recorded. You can still pass a corpus directly to kwic, but it will now throw a warning that this is 'deprecated'. This means that at the moment it still works, but at some point in the (near) future it will be mandatory to tokenize a corpus before using kwic
Hello! I have a question.. is there a way to implement LDA in other languages? I'm trying to applied to Italian Reviews from the web
Hi Brian! LDA itself does not care about language, because it only looks at word occurrences in documents. Simply put, as long as you can preprocess the text and represent it as a document term matrix, you can apply LDA.
@@kasperwelbers Thanks a lot for your fast reply. And of course thanks for the high quality content videos.
Thank you for this!! Gracias por esto!!
Hi kasper, nice explaination on TM, i am not able to figure out how to plot latent topics to visualise the evolution of topics yearwise.
Hello Kasper, thanks for this great video. Just wondering where I will get the document/chapter where all the codes are given. I mean the document from where you copied the codes and paste them into the R. Please let me know.
Hi @Dr Dilsad. Sorry, it seems I only included the link in the first video (about GLMs). More generally, we maintain some R tutorials that we regularly use in education on this GitHub page: github.com/ccs-amsterdam/r-course-material . The multilevel one is under frequentist statistics. There is a short version in the "Advanced statistics overview" that I think is the one from this video, and also a slightly more elaborate one in the "Multilevel models" tutorial.